Update on what happened in WebKit in the week from July 14 to July 27.
This two-week update includes plenty of changes to the Skia compositor,
changes to multimedia support, three blog posts, and assorted improvements.
Cross-Port 🐱
The Web Inspector “Layout & Rendering” timeline now shows a Layout Invalidated event for every element
that needs relayout, not just the layout root (with the old root-only event
renamed to Layout Scheduled). This unveils why some layouts take much longer
than others. No more guessing which of dozens of nodes is actually to blame!
The webkit://gpu page has gained a dark
style, which will be used when the
system settings indicate that dark mode is preferred by the user.
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
The experimental GstWebRTC backend was
removed and libwebrtc usage was
enabled in the main branch. We hope
to enable WebRTC support by default in the 2.56 series, scheduled around March
2027.
MP4 edit lists support was enabled in
the MSE backend, improving timestamp accuracy, specially when handling of
B-frames.
Graphics 🖼️
Split the compositing walk in the
Skia compositor into a damage pass and a paint pass, so the frame damage is
known before the first draw. The damage pass walks the layer tree with a
SkNoDrawCanvas in place of the real canvas, so every draw is discarded and
only the damage is collected. Both passes run from a single paint() that
applies animations and computes the transforms once, so the two see the same
tree. Knowing the damage up front is what lets the compositor eventually paint
only the parts of a frame that actually changed.
Wired up damage-driven compositing on
the Skia compositor, so a frame re-composites only the region that actually
changed instead of the whole surface, when the
UseDamagingInformationForCompositing feature is enabled (not yet on by
default). Each frame's damage is combined with what each swap-chain target
still needs to redraw since it was last drawn into, and the clear and every
draw are clipped to that region, which is a milestone towards no longer
repainting untouched pixels every frame.
Made the root layer collect the frame damage
itself in the Skia compositor, instead
of having each layer report its own changes. Reporting leaves a gap whenever a
layer is in no position to report, e.g. a destroyed one took its painted rectangle
with it, so what it had drawn stayed on screen. The root now holds one rectangle per
layer and compares it against what each frame's walk finds, so a layer that
moved is repainted in both places, and a layer the walk never reaches is
repainted where it used to be and dropped. Nothing has to notice anything for
the pixels it left behind to be repainted, which is what makes it safe to
restrict composition to the damaged region by default in future commits.
Limited every content draw to the target's repaint
region in the Skia compositor, so a
composited frame can redraw only the pixels that actually changed. Each content
type restricts itself to the region's rectangles rather than clipping the
canvas, since a multi-rectangle clip cannot be a hardware scissor and would make
Skia build a mask and break batching. This is the groundwork for damage-driven
compositing, which stays off by default behind the damage-tracking feature
flag, as the compositor still passes no region and nothing is restricted yet.
Made each swap-chain target track its own
damage since it was last current.
Repainting only what changed is correct only when drawing into the target that
holds the previous frame, but the swap chain hands back whichever target is
free, and that one is a frame or more behind. Each frame's damage is now added
to every target as it is recorded and cleared from a target when that target is
presented, instead of being built as a side effect of reading it.
Taught the tile and image draws in the Skia compositor to split themselves by
damage rectangle, so a frame only repaints
the parts of a layer that actually changed. A new SkiaDamageRegion holds the
frame's damage in device space and is built once per frame, and each draw is
restricted to it: skipped when it touches no damage, split into one sub-draw
per damage rectangle it overlaps, or drawn under a device-space clip when a rotated
or skewed transform rules out working with rectangles. Nothing feeds a damage region
in yet, so every draw still paints in full—this prepares for future patches
enabling using damage information in the composition
Fixed missing repaints when
compositor-applied layer state changes dynamically in the Coordinated Graphics
backend. A layer recorded damage when its backing store re-rendered or a new
contents buffer arrived, but the compositor also handles filters, masks, clip
path changes, the contents rectangle, the contents tiling, the blend mode and
contents visibility, and changing any of those alters the pixels it produces
without dirtying a tile. Those setters now damage the whole layer, so a
compositor that repaints only the damaged rectangles no longer leaves the previous
frame's pixels on screen.
Community & Events 🤝
Nikolas Zimmermann has written a two-part blog series about the current the new
Layer-Based SVG Engine (LBSE), with the first post covering the effort to
reduce layer
overhead
using layers conditionally, and the second about how compositing is being
implemented
and the complications introduced due to paint ordering rules.
Loïc Le Page has published a blog
post explaining how to
use the new WPEPlatform
API to implement a
custom WPE integration. While presented example uses
GLFW and EGL to show Web content on an X11 window, the
concepts are useful for anyone looking into embedding WPE.
In the past, when you needed to adapt WPE WebKit to a new platform, or integrate it with your own system/application
not based on Wayland, you had to develop a specific backend. I wrote two blog posts in the past about this topic
(One about the process of creating a new WPE backend and another about
using EGLStreams in a WPE backend) and, to be honest, it was not really
straightforward.
Since WPE WebKit 2.50, a new system has been designed to replace all this by a more modern and intuitive approach,
making a lot easier to integrate WPE WebKit into your application. The new API is called WPE Platform and
allows you to define the equivalent of the old backend system into your own executable. At the moment of this post
(version 2.52), the WPE Platform is still in development and the official release is foreseen for the next stable
version 2.54. Nevertheless, it is already stable enough to start playing with it.
This post is going to explain step by step how you can use WPE WebKit as a web view inside a simple X11 window using
EGL with full hardware acceleration and zero-copy of the graphical hardware buffers while avoiding the complexity of
writing an external backend. The X11/EGL window itself will be managed by the GLFW library.
N.B. GLFW is only used here as a convenient, cross-platform way of creating a window and an EGL context with a
minimal amount of code. It is not the topic of this post. What matters here is the generic contract to follow
to implement a custom WPE Platform. It consists basically in three GObject classes and a small set of virtual
methods that would look exactly the same if we had chosen SDL, Qt, or directly a raw X11 Window instead of GLFW.
The reference project for this post is
blog-the-wpe-platform-api. It implements a complete and
minimal WPE Platform taking into account the basic user’s interactions (keyboard, scrolling, mouse, etc…).
The version 0.0 of this code implements
the bases to initialize a web view using WPE (it will need a Wayland compositor to run). While the version
1.0 also integrates all the components
needed to implement the WPE Platform. From the implementation point of view, the only difference is the usage of
a custom WPEDisplay instead of the default one:
If your operating system has a development package for libWPEWebKit-2.0 version 2.52 or above, the easiest way is to
install this package from your distribution. Else, you can build WPE WebKit by yourself:
or by using the webkit-container-sdk reading the instructions
provided on the project,
The following instructions are for building the library locally out of any container. You first need to clone the
WPE WebKit project, version 2.52 or above:
mkdir wpe-webkit
cd wpe-webkit
git clone --depth1-b wpewebkit-2.52.5 https://github.com/WebKit/WebKit.git
Then install clang and all the needed development dependencies by calling: ./WebKit/Tools/wpe/install-dependencies.
Download the build-wpe.sh and set_dev_env.sh
scripts and copy them to your working folder containing the WebKit source code. Then execute:
It will build and install WPE WebKit into ./dist-wpe. The set_dev_env.sh script will set the environment
variables to use the files in ./dist-wpe for pkg-config and for the runtime.
Install the GLFW development dependency (package libglfw3-dev on Ubuntu/Debian).
Configure and build it:
cd wpe-glfw-platform
meson setup build
ninja -C build
You can now run it by calling ./build/wpe-glfw [url].
N.B. In the version 2.52.5 of WPE WebKit, the Skia multithreaded hardware-accelerated compositor is not fully
stable with some specific GPUs. In particular, with NVidia graphic cards, it may crash when the allocated surfaces
are resized to resolutions bigger than HD. If this is your case, you can disable the Skia hardware-accelerated
compositor by setting the environment variable WEBKIT_SKIA_ENABLE_CPU_RENDERING=1. In some cases, you don’t need to
disable the whole hardware-acceleration for the compositor. Sometimes just configuring the hardware compositor to use
only one thread is enough. You can do that by setting the environment variable WEBKIT_SKIA_PAINTING_THREADS=1.
A WPE Backend sits at the crossroads between the WPEWebProcess, in charge of running the ThreadedCompositor,
and the application process, which presents the resulting frames. Both processes must load the same backend shared
library, and that library has to implement an IPC layer to move each handle from one process to the other.
graph LR;
subgraph SA[<b>WPEWebProcess</b>]
A(ThreadedCompositor)
end
subgraph SB[<b>Application Process</b>]
C(User Application)
end
A -->|draw| B([WPE Backend shared library<br/>Loaded by both processes]) --> C
The WPE Platform API removes this shared library and all the IPC burden. WPE WebKit still spawns a
WPEWebProcess to run the ThreadedCompositor but the transfer of the rendered frames from the WPEWebProcess to the
application process is now handled internally by WPE WebKit itself. As an application developer, you no longer need
to implement any IPC: you only receive a ready-to-use WPEBuffer object, backed by a DMA buffer or by shared memory,
directly into your application process.
graph LR;
subgraph SA[<b>WPEWebProcess</b>]
A(ThreadedCompositor)
end
subgraph SB[<b>Application Process</b>]
B[WPEDisplay<br/>WPEToplevel<br/>WPEView]
C(User Application)
end
A -->|"WPEBuffer (handled internally)"| B --> C
What used to be a shared library exposing five libwpe interfaces is now just three plain
GObject classes (WPEDisplay, WPEToplevel and WPEView) that you need to subclass
and link directly into your application binary.
WPEDisplay is the entry
point. It owns the connection to the native graphical system (here, an EGL display bootstrapped through GLFW) and
acts as a factory for the toplevel window and the web views.
WPEToplevel is roughly
the equivalent of a native window. It owns the actual GLFW window, translates native window events (keyboard, mouse,
scroll, focus and resize) into WPEEvent instances, and exposes the usual window operations to the
WPE Platform API (resizing, setting the window title and switching to fullscreen).
WPEView is where the web
page is actually drawn. It receives a new WPEBuffer each time the ThreadedCompositor has produced a frame and is
responsible for presenting it on screen.
graph TB;
subgraph SA[<b>WPEGLFWDisplay</b>]
A["connect(): create the EGL display through GLFW"]
end
A -->|create_toplevel| B[<b>WPEGLFWToplevel</b><br/>owns the GLFW window]
A -->|create_view| C[<b>WPEGLFWView</b><br/>renders one WPEBuffer per frame]
B -.attach view and broadcast window events.-> C
A single WPEDisplay can create several toplevel windows, and a toplevel window can have several views attached to it
(think of tabs sharing one native window). In our example application we only create a single toplevel window with a
single view.
Implementing WPEGLFWDisplay: bootstrapping EGL through GLFW #
The
WPEGLFWDisplay::connect(…)
override is called only once, when wpe_display_connect(...) is invoked from main(). It initializes GLFW, requests
an EGL/GLES2 context for every window that will be created afterwards, and creates a tiny hidden bootstrap window used
only to force GLFW to set up its EGL connection:
// Request EGL + GLES 2 context for all subsequent window creationsglfwWindowHint(GLFW_CONTEXT_CREATION_API, GLFW_EGL_CONTEXT_API);glfwWindowHint(GLFW_CLIENT_API, GLFW_OPENGL_ES_API);glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR,2);glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR,0);glfwWindowHint(GLFW_VISIBLE, GLFW_FALSE);// Create a tiny hidden window so GLFW can initialize its EGL connection
self->init_window =glfwCreateWindow(1,1,"",NULL,NULL);...
self->egl_display =glfwGetEGLDisplay();
If we want to be able to transfer the frames with zero-copy, keeping them in the GPU memory, we will need a valid
WPEDRMDevice. It is also initialized during the display connection, using the EGL_EXT_device_query extension to
fetch the device associated with the current EGL display:
If WPEGLFWDisplay::get_drm_device(…)
returns NULL, the produced frames will be transferred to the application using shared memory, which implies copying
the frames content back and forth between the GPU and the CPU.
Implementing WPEGLFWToplevel: the window and its events #
WPEGLFWToplevel is where the actual GLFW window is created. It is important to manage this creation in the
WPEGLFWToplevel::constructed(…)
override rather than in the init() function because WPEToplevel::constructed(...) is resetting the toplevel
registered dimensions.
staticvoidwpe_glfw_toplevel_constructed(GObject* object){// It is important to initialize the window in the `constructed` virtual// method and not in the `init` method because the parent class// (WPETopLevel) resets the toplevel window size in this call.G_OBJECT_CLASS(wpe_glfw_toplevel_parent_class)->constructed(object);
WPEGLFWToplevel* self =WPE_GLFW_TOPLEVEL(object);// All window hints have already been configured by the display
self->window =glfwCreateWindow(DEFAULT_WIDTH, DEFAULT_HEIGHT,"",NULL,NULL);...// Communicate the initial window size to the WPETopLevel, so when// the WPEView is attached, it can be resized immediately to the correct// dimensions.wpe_toplevel_resized(WPE_TOPLEVEL(self), DEFAULT_WIDTH, DEFAULT_HEIGHT);}
Once the window exists, each GLFW events callback (for the keyboard, mouse, window resizing, etc…) is translating the
window events into the corresponding WPEEvent and broadcasts those events to every view currently attached to this
toplevel window.
The collection and dispatch of the GLFW events themselves are ensured by calling glfwPollEvents(). As this function
is managing the events for all the GLFW windows, it is configured in the
WPEGLFWDisplay as
a Glib source. This way all GLFW window events are collected, dispatched, translated into WPEEvent and broadcasted to
each view from the main application thread running the Glib main loop.
The rest of the class is a set of straightforward virtual method overrides mapping WPE window operations onto GLFW
calls to allow the WPE Platform API to set the window title, change the toplevel window size or switch to
fullscreen.
Implementing WPEGLFWView: turning a WPEBuffer into pixels #
WPEGLFWView is the class doing the actual OpenGL ES drawing. The main interesting override is
render_buffer(…),
called by WPE WebKit every time a new frame is ready to be presented. The rest of the code is basically some
boilerplate used to render a texture on a plane.
The WPEBuffer provided by WPE WebKit can be a wrapper for a DMA buffer allowing to draw the frame without copying
it to the main memory, or it can be the wrapper of a classical block of shared memory if the DRM device was not
available in
WPEGLFWDisplay::get_drm_device(…).
So, when drawing, we first try to get the EGLImage wrapped by the WPEBuffer and, if not available, we fall back to
the shared memory:
// Try to import the WPEView content through an EGLImage to allow a// zero-copy transfer. This is only going to work if the EGLDisplay is// associated with a valid DRM device returned by// WPEDisplay::get_drm_device().
gpointer egl_image =wpe_buffer_import_to_egl_image(buffer,NULL);if(egl_image){
self->glEGLImageTargetTexture2DOES(GL_TEXTURE_2D,(GLeglImageOES)egl_image);glUniform1f(self->uniform_swap_rb,0.f);}else{// Else, fall back to the SHM buffer. In this case the WPEView content// is copied through the CPU into shared memory.
GBytes* pixels =wpe_buffer_import_to_pixels(buffer,&shm_err);...
gconstpointer data =g_bytes_get_data(pixels,NULL);...glTexImage2D(GL_TEXTURE_2D,0, GL_RGBA,(GLsizei)buf_w,(GLsizei)buf_h,0, GL_RGBA, GL_UNSIGNED_BYTE, data);glUniform1f(self->uniform_swap_rb,1.f);}
All the resources (the EGLImage or the GBytes pixels array) are held by the WPE WebKitThreadedCompositor and
so, once the drawing is finished, we must signal that the buffer has been rendered and can be recycled:
The first call (wpe_view_buffer_rendered(...)) triggers the rendering of the next frame, while the second call
(wpe_view_buffer_released(...)) informs that the internal EGLImage or GBytes pixels array can be re-used for a
future frame content, avoiding the allocation of new buffers for each new frame.
N.B. The drawing loop in the example is very simplified for the purpose of this post because we are not
repainting the window content when it is damaged for example. We are only doing the drawing sequentially at one place
when receiving a new frame from the web view. In a real application, we may want to keep the current WPEBuffer for
intermediate repainting, until receiving the next frame. In this case, we would call wpe_view_buffer_rendered(...)
for buffer A once it has been drawn but we would call wpe_view_buffer_released(...) only after receiving buffer
B with the next frame content. So, buffer A may be used more than once to repaint the window content like
shown in the following sequence diagram.
sequenceDiagram
participant A as WPEWebProcess
participant B as Application Process
activate A
A ->> A: Render frame 1 in buffer A
A ->> B: WPEBuffer A
deactivate A
activate B
B ->> B: Draw frame 1 from buffer A
B ->> A: wpe_view_buffer_rendered(A)
deactivate B
activate A
A ->> A: Render frame 2 in buffer B
activate B
B ->> B: Repaint buffer A
deactivate B
A ->> B: WPEBuffer B
deactivate A
activate B
B ->> A: wpe_view_buffer_released(A)
B ->> B: Draw frame 2 from buffer B
B ->> A: wpe_view_buffer_rendered(B)
deactivate B
activate A
A ->> A: Render frame 3 in buffer A
A ->> B: WPEBuffer A
deactivate A
activate B
B ->> A: wpe_view_buffer_released(B)
B ->> B: Draw frame 3 from buffer A
deactivate B
The rendering in the current example is not optimized either because the ThreadedCompositor must wait for the
complete presentation of the current frame with glfwSwapBuffers(...) blocking until the drawing is finished. We can
perfectly imagine a multithreaded view where the render_buffer(...) override just posts the current WPEBuffer to a
separate drawing thread. This way the WPE WebKit drawing of the next frame and the presentation of the current
frame on screen would run in parallel instead of waiting for each other.
Glad to see the Web Engines Hackfest covered in the local tech magazine Código Cero. Of course I’m biased, but I’m very happy with the growth of the event and the really interesting discussions that happen there every year.
Update on what happened in WebKit in the week from June 30 to July 13.
The summer continues with many updates to the new SVG engine (LBSE),
improvements to the new Skia-based compositor, some small API additions,
and ever-important stable releases with security fixes.
Roughly halved the cost of the Skia based
compositor on WPE running on Vivante
GPUs with the Etnaviv driver, by turning off Skia's mipmap sharpening option.
That option is enabled by default and makes the Skia shader generator append a
small negative level-of-detail (LOD) bias to every mipmap-capable texture
sample. WPE does not use mipmapping at all, so the bias sharpened nothing,
but it still turned each texture fetch into a LOD lookup, which is a slow path
on the tiled GPUs found in the i.MX series. Disabling it restores usage of
faster, plain fetch operations.
Fixed broken rendering with the Skia
compositor on WPE when super-tiled
textures are enabled on Vivante GPUs. Those tile buffers are allocated padded
up to a multiple of 64 pixels, so the physical texture is larger than the
logical tile, but the Skia backing failed to take this difference into
account, leading to distorted tile images being rendered.
Stopped the Skia compositor from blending opaque
layers on WPE. Every layer was drawn
with the default source-over blend mode, which leaves GPU blending switched on
even for fully opaque layers that do not need it, so the cost was paid on
every composited frame.
Layers that are opaque, drawn at full opacity and using the default blend mode
are now composited with a plain source blend mode instead, which lets Skia
turn blending off and lowers GPU bandwidth usage, benefiting tiled GPUs the
most.
Reading the transform attribute walked the whole transform list and
multiplied every item together again, and that happened around three times per
animation frame for each element, even though the result only changes when the
transform list itself is mutated.
The concatenated matrix is now stored on the element and invalidated whenever
a transform-related attribute changes, so the multiplication runs once per
mutation instead of once per read. This cuts repeated matrix work out of the
per-frame path for animated SVG content.
Painting a container used to set up a clip rectangle for every child shape in
turn, so each shape did its own graphics-context save, clip and restore even
though the clip rectangle was identical for all of them. When there is a
single region to clip to and no child paints into its own layer, that clip is
now established once and shared by every child, transformed or not.
This removes a per-shape save and clip from the hot painting path of SVG
documents with many children.
Every transform flush recomputed the origin for each non-layered SVG shape,
even though it only depends on the transform-origin style and the transform
reference box, and sampling MotionMark's Suits test at fixed complexity showed
that computation taking around 1% of the WebProcess main thread.
The origin is now cached and keyed on the reference box, with a style change
to transform-origin or transform-box dropping the cache, and the fast path
is limited to plain SVG transforms so viewport containers and CSS-transformed
renderers keep computing it directly. This removes a repeated per-shape cost
from animated SVG content, and the caching scope can be widened later.
The default transform-box for SVG is view-box, so every transformed shape
resolved the viewport from the SVG root's content box again on each query,
both when updating its local transform and again during paint. The viewport is
constant after layout, so it is now cached on the <svg> element and only
recomputed when layout actually changes it, on resize, zoom or a viewBox
update. This removes another repeated per-frame computation from the transform
path for animated SVG content.
Once per rendering update WebKit processes every SVG renderer whose transform
changed, whether from script or an animation, and that repaint pass was the
dominant per-frame cost on MotionMark's Suits subtest. Instead of walking each
moved renderer up to its repaint container, the flush now computes each
child's rectangle in its parent's coordinate space, unions the children per
parent, maps that single union up the chain once, and issues one
repaintUsingContainer() call per repaint container rather than one per
shape.
This also stops requesting outline bounds, which for SVG merely duplicated the
visual overflow rectangle, and refreshes the bounding-box and visual-overflow
caches that a layout would normally update, so getBBox() and paint or
hit-test culling never read a stale rectangle. This collapses many
backing-store invalidations into one while keeping the repainted region
minimal, closing the performance gap to the legacy SVG engine.
Non-layer SVG renderers already cache their transform in m_localTransform,
but the painting code path used to recompute it from scratch each time,
concatenating the transform list, applying transform-origin and
multiplying matrices, only because the cached value uses a different transform
origin. The paint transform is now derived directly from the cached one by
translating around the nominal origin, which removes that per-paint
recomputation and cuts the cost of painting transformed SVG content.
Fixed a repaint bug in the
Layer-Based SVG Engine (LBSE) where dynamically changing a marker's
markerUnits or orient attribute left stale pixels behind. Such a change
resizes every shape that references the marker, but a referencing shape
without a layer gets no post-layout position update, so only its new bounds
were repainted—a shrinking marker left its former area on screen.
The visual overflow rectangle, markers included, is now cached at the end of
shape layout while the geometry is still current, so a marker change can
repaint the old bounds before recomputing the new ones. The extra repaint is
limited to markers, since gradients and patterns do not affect a client's
bounds, and the resulting repaint rects are more accurate than the legacy SVG
engine's.
WPE WebKit 📟
Added a new feature flag,
BackForwardCacheWithMedia, which may be used to disable storing pages with
media content in the back-forward cache. This should solve the problem with
hardware decoders kept occupied on low-end devices in case of caching pages
with media after navigation.
Releases 📦️
WebKitGTK 2.52.5 and WPE WebKit 2.52.5 have been released, including a number of fixes for security issues, and therefore it is recommended to update. An accompanying security advisory will be published in the coming days. Additionally, these releases include small improvements and Web compatibility improvements.
In which I share some thoughts about the state of things, and how maybe we could hope to change them.
Back in 2020, after Microsoft gave up on their own engine, I began writing about a topic I called "Web Ecosystem Health". What ultimately makes a healthy system that will last? Over time I became convinced that it is all much more fragile than we realize. In 2021 I wrote Web Rise beginning to detail some of this.
There have been several more articles and a whole series of at least 20 podcast episodes with guests of all types talking about many, many different aspects of this. But, at the heart of it is really how it is all funded.
The other day I asked on social media "Imagine that one of the big 3 web engine stewards, for some reason, decided they would stop. What do you think would happen? Would someone step in and save the project? Who? Or would it just die?" My colleague Eric Meyer (who is on holiday and had no idea I was posting this, or why) replied
My prediction is that people would step in to save it, but the effort would falter and wane over the next several years as contributors lost momentum and interest until finally shuddering to a halt.
And that's kind of why I asked - because I was landing in a sort of similar situation. I mean, I've said it before, but I think maybe even more radically now, we need to diversify investment. Maybe even diverisfy ownership, somehow in a bigger way.
The Supporters of Chromium-Based Browsers (https://socbb.org/ - which I've recently heard pronounced "Sock Baby" and have now latched onto) is an interesting collaborative initiative under the Linux Foundation that some of our discussions helped inspire. Basically, it's a common pool of money that is paid into by Google, Microsoft, Meta and Opera which then tries to fund work and grow contributions from outside those organizations. Together, they decide how the money is spent.
I think it's still "small" though and I wonder how much you could scale it up. I was thinking about this with regard to Servo. Servo is a really interesting project. It gets people excited. It is written in Rust, it's the first one to come without a long history of baggage that it has to deal with. There is so much promise there.
But, it's also not really remotely ready to compete with Blink or WebKit or Gecko, and none of those are standing still. In fact, while Servo can close ground quickly in some cases, there are just far, far fewer people paddling it forward. It takes a leap of faith to believe that we could make it really competitive, and to provide the resources to do it. Again, very few orgs even could carry the load on their own - and it's still kind of fragile if it's just one org too. But what if we could collectively own it. Something more like the Mozilla Foundation, but... better? What if we could get a lot of companies to invest in that dream with the promise that a kind of collective ownership could really change things and that while no one could do it alone, probably we could all bear to take a chance on something with a lot of interesting upside. What makes Servo interesting here is that doens't already have a powerful and weathy steward. Diverisity of ownership it could ensure that the web would remain despite changes to buisness models and so on. It would help give them some kind of a louder voice - but also present really practical compelling reasons for building concensus and compromise -- because no one org is king.
It would be an interesting new challenge in governance and so on, but... It could be really interesting.
While working on Vulkan Video encode support in Mesa, I needed to capture H.265
encoding traces. gfxreconstruct already handled H.264 video and several other
extensions, but VK_KHR_video_encode_h265 was explicitly blocked. Here’s how I
unblocked it and what I learned about gfxreconstruct’s code generation
machinery along the way.
gfxreconstruct is LunarG’s suite
of tools for capturing and replaying graphics API calls. It intercepts Vulkan
(and D3D12) calls at the layer level, serializes them into a compressed binary
trace file, and can later replay that trace verbatim. This is useful for driver
regression testing, GPU bring up, architecture simulation, and bug reporting.
gfxreconstruct has two independent mechanisms that prevent an extension from
being captured.
The first is a runtime blocklist in
framework/encode/vulkan_entry_base.cpp.
A static array called kVulkanUnsupportedDeviceExtensions lists extension name
strings that the layer strips from vkEnumerateDeviceExtensionProperties
results. If your extension is on that list, applications cannot even see it when
the capture layer is loaded, so they never attempt to use it and nothing gets
recorded.
The second is a generation-time exclusion list in the Python code generator.
gfxreconstruct does not hand-write capture and replay handlers for each Vulkan
function. Instead, it parses the Khronos XML registry (vk.xml, video.xml)
and auto-generates thousands of lines of C++ for encoding, decoding, and
consuming API calls. The generator has exclusion lists that tell it which
extensions and struct families to skip entirely.
This part is trivial: open framework/encode/vulkan_entry_base.cpp and delete
the line
VK_KHR_VIDEO_ENCODE_H265_EXTENSION_NAME,
from kVulkanUnsupportedDeviceExtensions. One line. After rebuilding, the layer
reports the extension to applications. But that is not enough: without generated
capture/replay code, intercepted calls would have no handlers.
After removing the exclusions, I ran the generator and hit an error. The
generator could not resolve a len attribute in video.xml for
StdVideoH265HrdParameters.
The problematic members are pSubLayerHrdParametersNal and
pSubLayerHrdParametersVcl. Both are pointers, and video.xml specifies
len="*_max_sub_layers_minus1 + 1" for them. The expression references
*_max_sub_layers_minus1, a field that lives in an outer struct (VPS or SPS),
not in StdVideoH265HrdParameters itself.
gfxreconstruct’s code generator resolves len expressions by walking the
current struct’s members, but it cannot follow cross-struct references. This is
a reasonable limitation: the generator would need to understand the full
semantics of the Vulkan Video specification to know which outer struct provides
the length field.
The fix is a small XML tree patch in
gencode.py.
Before the generator runs, I strip the len attribute from both members:
hrd_type = video_tree.find('types/type[@name="StdVideoH265HrdParameters"]') if hrd_type isnotNone: for member_name in('pSubLayerHrdParametersNal','pSubLayerHrdParametersVcl'): for member in hrd_type.findall('member'): name_elem = member.find('name') if name_elem isnotNoneand name_elem.text == member_name: member.attrib.pop('len',None)
Without a len attribute, the generator falls back to treating each pointer as
pointing to a single element. This is safe for practical capture scenarios where
only one sub-layer is in use.
With the generator changes in place, regenerating is a single command:
uv run --with pyparsing python3 framework/generated/generate_vulkan.py
uv run --with pyparsing ensures the pyparsing dependency is available
without a manual pip install.
The generator overwrites all files under
framework/generated/generated_vulkan_*.cpp and
framework/generated/generated_vulkan_*.h. The diff was substantial: hundreds
of new functions for encoding and decoding StdVideoH265* structs, plus all the
video session parameter handling infrastructure.
The interesting part of this exercise was understanding gfxreconstruct’s
architecture. The capture layer is not a monolithic block of hand-written
interceptors. It is a generator pipeline: Python scripts consume the Khronos XML
registry and emit C++ that handles serialization, deserialization, and replay
for every struct and function in the Vulkan API surface.
This means enabling a new extension is mostly a matter of telling the generator
to stop ignoring it, then fixing any edge cases where the XML description
does not match the generator’s assumptions. The actual capture and replay logic
comes for free once the generator produces code for the extension’s types and
entry points.
If you are considering enabling other video extensions (H.264 encode is still
blocked), the same recipe applies: remove from the runtime blocklist, remove
from _remove_extensions and _remove_video_extensions, regenerate, and fix
any XML len expression issues that surface.
Update on what happened in WebKit in the week from June 22 to June 29.
After a small break after the Web Engines Hackgest, we're back with another
round of updates, this time with a couple of exciting improvements to the
SVG engine, a WebRTC fix, and support for WebP images with the toDataURL()
API.
Cross-Port 🐱
Made RenderLayer creation conditional for SVG renderers in the new Layer-Based SVG Engine (LBSE), so a layer is now only created when one is actually needed for intrinsic reasons (3D transforms, opacity, etc.) instead of unconditionally for every renderer. Plain 2D transforms no longer force a layer and are applied directly during painting. This is the groundwork for follow-up patches that remove the intrinsic need for layers when applying clipping, masking and filters to SVG subtrees. It is an important milestone towards reducing the overhead that has been holding back LBSE performance compared to the legacy SVG engine.
Fixed the paint order of non-composited children around composited SVG siblings in the Layer-Based SVG Engine (LBSE). A layered container paints its children from a single flat list in DOM (and SVG paint) order, but some children are composited into their own GraphicsLayer for reasons like will-change, a 3D transform or certain opacity cases. The flat child list is now split into contiguous paint-order segments at those boundaries, with each run of plain children painted by its own overlay layer placed at the correct depth in the compositor's child list. This keeps every child in its DOM order without giving trailing siblings a RenderLayer or backing store of their own, and a container with no composited children produces no segments at all, so the common case costs nothing. This allows us to support composition within LBSE subtrees in a performant way, after dropping the requirement that every renderer creates a layer.
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
Fixed initial decoding issues on LibWebRTC on platforms that do video decoding on the final playback stage (for efficiency and performance), instead of on the LibWebRTC decoder component.
Earlier this month, I returned to CSS Day for the first time since
2018 to deliver my first in-person talk since 2022. “Forging Our Own
Paths” should be available at some point; in the meantime, for the six or
seven people in my audience who might need to do something similar, I’d
like to share a small macOS workflow I developed to make syntax-highlighting
code blocks in situ in Keynote a lot simpler. The
end result is to have an entry (or entries) in the Services submenu of
the contextual (right-click) menu for highlighted text. All this is adapted from an old blog
post I found copied in a few places, and which needed some updates to
make things work in 2026.
This is what it looks like for me. It could look much the same for you!
First, install highlight. I used brew install highlight, and the rest of this piece assumes you’ve done it that way. If you install it another way, such that it ends up in a different location than Homebrew would give it, you’ll need to modify a variable value later on, which I’ll point out when we get there.
Next, you need to install the following (also available as a gist) as a shell script called keynote-highlight:
#! /bin/bash
set -e
while getopts 'h:o:i:s:t:' OPTION; do
case "$OPTION" in
h)
highlighthome="$OPTARG"
;;
o)
outputrtf="$OPTARG"
;;
i)
inputrtf="$OPTARG"
;;
s)
syntax="$OPTARG"
;;
t)
theme="$OPTARG"
;;
?)
echo "script usage incorrect?" >&2
exit 1
;;
esac
done
shift "$(($OPTIND -1))"
#=============================
inputrtf="$(pbpaste -pboard -prefer public.rtf)"
regex="fcharset0 ([a-zA-Z0-9 ]+);"
if [[ "$inputrtf" =~ $regex ]]
then
fontface=${BASH_REMATCH[1]}
else
fontface="Courier"
fi
regex="fs([0-9]{1,5})"
if [[ "$inputrtf" =~ $regex ]]
then
fontsize=${BASH_REMATCH[1]}
fontsize2=$((fontsize/2))
else
fontsize2="12"
fi
if [ -z "$theme" ]; then
theme="candy"
fi
if [ -z "$highlighthome" ]; then
highlighthome="/opt/homebrew/bin/highlight"
fi
highlighted=$("$highlighthome" --out-format="rtf" --syntax="$syntax" --style="$theme" --font="$fontface" --font-size="$fontsize2" --no-trailing-nl --stdout)
echo "$highlighted"
Put the script wherever you store your shell scripts, and make sure
it’s both executable and can be invoked from the command line. I
believe, without any real basis for doing so, that if you
already have syntax-highlight
installed, which is (among other things) a wrapper around
highlight, you could use it by modifying the
highlighthome variable assignment to point to it rather
than highlight, as well as modifying a variable in an
upcoming bit of code. But, as I say, I’m just guessing about that.
Once the shell script is installed and ready to execute, launch
Automator and create a new Quick Action. Call it “Syntax Highlight CSS”
or something similar. If you want to set up highlighting for other kinds
of code, like HTML or any of the nearly 250
languages (!!!) highlight supports, each language has
to be given its own Quick Action. Thus, if you want them all next to
each other in the Services menu, pick an appropriate naming scheme. For
this one, we’re doing CSS, but later you’ll see how you can quickly set
up this same thing for other formats.
At the top of the right-hand panel in the new Quick Action workflow,
check the “Workflow receives current” dropdown to make sure it’s set to
either “Automatic (rich text)” or “rich text”, the latter if you plan to
never, ever use this in any non-RTF setting. I go with the Automatic
option. If you want to restrict the action to a particular application,
like Keynote, change the dropdown that says “any application” to pick a
specific application. I leave mine to be available in any application,
just in case I’m ever syntax highlighting code in TextEdit or something. I also set the color to “Red”, because clearly that makes it go
faster.
With all those things set, the first thing to add to the workflow is
a “Copy to Clipboard” action. That’s it for this step, just add that and
leave it alone.
Now, add a “Run AppleScript” action. Paste the following (also available
as a gist) into the textbox that contains the boilerplate skeleton
(replace the skeleton):
on run {input, parameters}
set highlightHome to "/opt/homebrew/bin/highlight"
set syntaxType to "css"
set themeName to "navy"
set command to "PATH_TO_SCRIPT/keynote-highlight -h " & highlightHome & " -s " & syntaxType & " -t " & themeName
do shell script "/bin/bash -c 'pbpaste | " & command & " | pbcopy'"
delay 0.1
tell application "System Events" to keystroke "v" using command down
end run
Change the PATH_TO_SCRIPT in there to wherever you put
the shell script, save the workflow, and it should be ready to go!
What the Automator workflow should look like.
…unless your copy of highlight lives somewhere else or
you’re trying out using syntax-highlight in its place, or
you have a different theme you’d like to use. In either case, change the
value of the corresponding variable in the AppleScript. As for the
syntaxType variable, that’s what you change if you want to
highlight HTML or Pascal or BASIC or whatever else, but since we’re
doing CSS, leave it as is.
At this point, everything should be ready to go. In your Keynote
slides, wherever you want to syntax-highlight some CSS, drag-select (or
select-all) the CSS text in question. Just be sure you have the text
actually highlighted; just selecting the outer text box that holds the
text isn’t sufficient. Right-click on the selected text to bring up the
Context menu, and in there open the “Services” submenu. “Syntax
Highlight CSS” (or whatever you called yours) should be in that submenu. Select it, and after a second or two, the un-highlighted CSS should be
replaced with the same thing, except syntax-highlighted.
A short movie showing the workflow in action. (2.1MB MP4; no audio)
Well, “the same thing” in the sense of being the same font face and
font size it was before you syntax-highlighted it. If you used a line
spacing other than 1.0, it will be reset to 1.0. This is due to a
limitation in highlight, which doesn’t accept line-height
values as an argument, and thus will always return text with 1.0
spacing. It’s likely that other fancy adjustments like kerning will also
be reset to default, though I didn’t test them all. I just know that
highlight only accepts font name and size as styling
parameters, so those were the only ones I could affect.
I did try to capture the output of highlight and
do find-and-replace to restore the line height and tab sizes. Alas, this
was ultimately unsuccessful. I’m fairly confident this is solvable, but
a great deal less confident that it’s solvable by me. Part of the
problem seems to be how highlight returns the RTF, and part
of it seems to be some kind of recursive munging of the RTF result
(maybe?), and in the end I just gave up.
If you want to set up something similar for HTML, then you need only
duplicate the workflow to a different name — say, “Syntax Highlight
HTML” — and then change the value of the AppleScript
syntaxType variable from css to
html in the new workflow. That’s all. Similar steps should
be taken to set up a workflow for any other recognized language.
There are a few things to note.
If you try to syntax-highlight a block of text that contains
multiple font faces or sizes, all of the selected text will be reset to
the first face and size, or the script will simply fail to work. As far
as I can tell, preserving the face and size on a per-line (or
per-character) basis would be difficult to achieve and probably produce
terrible RTF. As a workaround, highlight each bit of differently-sized
or -faced text on its own, and invoke the service.
There is no checking to see if the text you highlight matches the
type of highlighter to apply to it. If you try to use “Syntax Highlight
CSS” on some HTML, the CSS parser will be used. So be careful.
Picking a new theme can be a cumbersome process, involving a fair
amount of trial and error. It looks like Syntax
Highlight has a standalone application that can be used for quick
previewing, but I haven’t tried it so I can’t vouch for or against
it.
I did all this in macOS Sequoia. I would hope it still works in Tahoe, but if not, let me know in the comments and I’ll add a warning note and a heavy sigh.
There are probably more efficient or more elegant ways to do the individual bits of both scripts, but this works for me, so I figured I’d pass it on to anyone else who’d like to use it. Improvements, or pointers to solid information that can help me overcome the limitations I mentioned, are always welcome!
Update on what happened in WebKit in the week from June 9 to June 16.
The major highlight this week is the Web Engines Hackfest! Despite it, there
are a variety of updates as well, such as various improvements to input
handling in WPE WebKit and WebKitGTK, WPE menu rendering changes, and a
plethora of other smaller improvements.
Due to GTK not providing an equivalent value for GtkInputPurpose, the default behaviour is to continue mapping search fields to GTK_INPUT_PURPOSE_FREE_FORM as before; but custom input methods may use the new value to detect search inputs. When using WPEPlatform, the value is mapped to WPE_INPUT_PURPOSE_SEARCH, which has been added as well.
WPE now renders its own popup menus for elements such as select. It supports all styling options the web provides such as colors and fonts. The internal menu can be overriden with the existing WebView::show-option-menu signal. Cog for example still renders its own (with a recent commit).
Community & Events 🤝
The Web Engines Hackfest started! We had a fantastic first day of talks, and now are heading to breakout sessions. Make sure to check the schedule for sessions that may interest you!
In which I am drawn into an unexpected sort of conversation...
I like to feel like I'm working on — or at least toward — something concrete. When things begin to seem too academic or esoteric, or feel disconnected from what appear to be obvious realities, I find it much less interesting. There are clear examples of things I've worked on (or am working on): custom elements, :has, :focus-visible, Custom Properties or even Container Queries. All of these are very concrete, and as such, now that we have them we're also starting to be able to see how successful they are (or aren't). Things take a long time, so in the end, even very concrete proposals can start to feel a bit esoteric when they're so far out ahead of our skis, leaning more and more onto foundations that aren't yet solid.
Anyway... In contrast to this, if you asked me to professionally come up with a definition for "What is the web, exactly?" I have this almost visceral feeling that it's esoteric and I don't want to spend my limited energy on it. I want to run away from it. Far away. Who cares? It means whatever we collectively want it to mean. That's not my jam. It's stuff with URLs. It is not a thing I relish discussing.
But...
Circumstances have put me in a time and place where the question keeps coming up — and I hate to admit it, but I think there are a few reasons to engage with it.
The question surfaced concretely around what belongs as a W3C Recommendation, and more broadly, what belongs at the W3C at all. Its catalog is pretty diverse, actually. Is it all equally "the Web"? The stuff in the browser certainly seems like a special kind of thing. It carries special obligations around privacy, security, internationalization, and accessibility. It runs on just about every device imaginable. But then there's stuff like ActivityPub, JSON-LD, or XML — the browser doesn't do much with those. It could, maybe, but that would come with its own considerations. And yet they're totally relevant, and they're totally the web.
Then there's a whole category of things that have emerged over the past decade pointing toward something... more. Special kinds of apps that come preinstalled (on your TV or your smart toaster), or Electron apps you install yourself, or "super apps" that use web tech for UI while talking to things that aren't really the "drive-by" web we know from the browser. Different rules, but no standards. Yet.
Which of these do the words "web platform" and "web" actually apply to?
If we had a few more names, would it help us organize our thoughts, sharpen our priorities, and shape the overall architecture? Probably.
My current thinking
My current thinking is: I don't know that it is worth defining "the web" very specifically. "The Web Platform," however, I think is best used to describe what lives inside a web engine. And the embedded stuff? I feel like we need a group dedicated to that — an Embedded Web that tries to define something fairly minimal, grounded in the same concerns as the main web engines. We're working on getting people together to talk about this, because it really does affect what we prioritize and the direction we take things.
I recently recorded a podcast on this topic with Dan Appelquist and Eric Meyer called Is this the web?.
Update on what happened in WebKit in the week from June 1 to June 8.
Another great week, this time we have a performance improvement implemented
in the Skia-based compositor, an excellent writeup about how to investigate
and isolate memory leaks in WPE WebKit, a couple of multimedia fixes, and a
variety of improvements and fixes across WebKit ports.
Implement node iterator and live range pre-remove steps for in-progress moveBefore() implementation.
Fix an early return in CloseWatcher close to align with the spec.
The Web Inspector now shows DOM nodes associated with layout and rendering events in a separate column of layout timeline next to initiator, sizing, and timing information. Hovering over rows in the details table highlights the associated node, and clicking it reveals the node in the "Elements" tab. This makes it easier to match events with specific nodes and helps debugging changes to a web page.
Fix popover light dismiss to account for disabled command buttons.
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
FixmediaTime provided with requestVideoFrameCallback in case of captureCanvas as source.
Batched painting support was implemented in the Skia-based compositor, improving the performance in several cases.
Community & Events 🤝
Pawel Lampe published a blog post where he's presenting and discussing a guide on structured approach to narrowing down and debugging memory leaks within WPE WebKit.
As part of Igalia’s collaboration with Raspberry Pi, I have previously blogged about several improvements we landed for the Broadcom VideoCore GPU (known as V3D), with the goal of extracting the best possible performance from the hardware. However, performance is not the whole story. On embedded devices, power consumption is just as important: reducing unnecessary activity helps lower heat generation, improve energy efficiency, and preserve performance over time by avoiding thermal throttling.
That is why, over the last few months, we have been working on adding Runtime Power Management support to the upstream V3D DRM driver, allowing the GPU to be powered and clocked according to its actual usage.
Why Runtime Power Management?
In the Linux kernel, Runtime Power Management (known as Runtime PM) is the mechanism that allows individual devices to be suspended and resumed dynamically while the system as a whole remains running. Instead of keeping a device fully powered all the time, the kernel can put the device into a low-power state when it is idle and bring it back when it is needed again.
In the graphics context, it is easy to see why runtime PM can be useful. A GPU is not necessarily active all the time: it may be heavily used while rendering a scene, but remain idle for long periods afterwards. If the driver keeps the GPU clocked during those idle periods, the system keeps spending energy on a block that is not doing useful work at all.
For embedded platforms, this is even more pressing. Reducing unnecessary power consumption helps decrease heat generation and improve overall energy efficiency. Even if the board is not battery-powered, avoiding needless power usage can reduce the need for cooling and leave more thermal budget available for other blocks.
The Problem: an idle GPU with an enabled clock
Until now, the V3D driver had a very simple power model: the GPU clock was enabled during probe and remained enabled for the entire lifetime of the driver. In practice, this meant that once the driver was loaded, the V3D clock stayed on until the driver was removed, regardless of whether the GPU was actively executing jobs. This was simple and functional, but it meant that an idle GPU was not idle from a power-management point of view.
On Raspberry Pi platforms, this is easy to observe with vcgencmd. Even with no GPU workload running, the V3D clock would still report an enabled frequency:
If the GPU is idle, the driver should be able to let the hardware become idle as well. Runtime PM provides the kernel infrastructure for that, but enabling it in the V3D driver required a bit more than simply adding suspend and resume callbacks.
Making the Raspberry Pi firmware clocks obey
At first glance, adding Runtime PM to V3D might look like a driver-local change, but in practice, things were a bit more subtle.
On Raspberry Pi platforms, some clocks are managed by the Raspberry Pi firmware. From the V3D driver’s point of view, this is supposed to be mostly transparent: the driver uses the standard Linux clock framework, and the clock provider takes care of talking to the firmware underneath. However, this abstraction only works if calls to clk_prepare_enable() and clk_disable_unprepare() are translated into actual firmware requests to enable and disable the clock.
Surprisingly, that was not happening. The Raspberry Pi firmware clock driver did not implement the prepare/unprepare hooks, so these calls did not actually ask the firmware to enable or disable the clock. We fixed that by translating the common clock framework operations into the corresponding Raspberry Pi firmware commands [1][2][3].
However, there was still one firmware-specific caveat: on current firmware versions, RPI_FIRMWARE_SET_CLOCK_STATE does not fully power off the clock as expected. To work around this limitation and achieve meaningful power savings, the clock rate also needs to be set to the minimum before disabling the clock. This behavior may change in future firmware releases, but for now the clock driver needs to account for it explicitly.
With the firmware clock limitation addressed, the V3D driver could start relying on the usual kernel clock APIs as part of its Runtime PM flow. The next step was to reorganize the driver so that powering the GPU up and down became part of its operation.
Introducing Runtime PM to V3D
With the clock side behaving as expected, we could move the V3D driver itself to a Runtime PM model [7][8][9].
This required a small refactor of the probe path to separate power-independent setup from GPU-powered initialization. Resources that do not require the GPU to be powered are allocated during probe, while any initialization that depends on the GPU being clocked is handled during runtime resume. Runtime suspend then disables the clock again when the device becomes idle. The resulting flow is simple:
With that in place, the change becomes visible from userspace. While a GPU workload such as glmark2 is running, the V3D clock is enabled:
After the workload finishes and the GPU becomes idle, the clock can drop back to zero:
$ vcgencmd measure_clock v3d
frequency(0)=0
This is the behavior we wanted: the GPU remains available when there is work to do, but it no longer keeps its clock enabled while idle.
Results
To evaluate the effect of Runtime PM, we measured the board’s power consumption with an external power meter in three scenarios: an idle desktop session with labwc running, an idle system without the compositor, and a full glmark2 run. Each condition was sampled at 100 Hz for around 300 seconds.
The first case represents a mostly idle graphical session, where labwc, the compositor used by Raspberry Pi OS, may still wake the GPU occasionally. The second is a baseline with no graphical workload, while the third is a sustained GPU benchmark intended to keep the GPU active.
The numbers behave the way one would hope. When the GPU is genuinely idle, the clock can be gated off and the savings show up as a clear drop: average draw falls from 3.30 W to 3.19 W with labwc running, and from 3.18 W to 3.09 W with no compositor at all. Both idle scenarios end up with savings of about 0.1 W (around 3%). Under glmark2, where the GPU is doing useful work for most of the run, the difference shrinks to about 0.015 W (0.3%), which is expected, as Runtime PM mainly affects the periods where the GPU becomes idle.
Scenario
Before
After
Difference
Idle, compositor running
3.300 W
3.192 W
-0.108 W (-3.3%)
Idle, no compositor
3.179 W
3.093 W
-0.086 W (-2.7%)
glmark2 full run
5.698 W
5.683 W
-0.015 W (-0.3%)
The distribution of idle samples with labwc running also shows the effect clearly. With Runtime PM enabled, the distribution shifts toward lower power states. This indicates that the board spends more time in lower-power idle states once the V3D clock is no longer kept enabled unnecessarily.
The effect is even cleaner with no compositor running. The samples collapse into two very narrow peaks with no overlap between them: without Runtime PM, the board sits at a stable 3.18 W; with Runtime PM, it sits at a stable 3.09 W.
For glmark2, the time-series data shows that both configurations follow the same general workload pattern. Runtime PM does not significantly change the power profile while the GPU is busy, which is the intended behavior. The benefit appears when the workload leaves idle gaps or finishes, allowing the clock to be disabled again.
Overall, these measurements show that Runtime PM reduces power consumption where it matters most: when the GPU is idle. The absolute savings are modest at the board level, since the measurement includes the whole Raspberry Pi rather than the GPU power block alone, but the reduction is consistent with the intended change. The V3D clock no longer remains enabled for the full lifetime of the driver, and that translates into measurable reductions in idle power consumption.
Conclusion
Runtime PM support for V3D is one of those changes that is easy to overlook when everything is working correctly: userspace does not need to do anything differently, applications keep using the GPU as before, and the improvement happens underneath, in the way the kernel manages the hardware.
Beyond improving raw GPU performance, our work at Igalia is also about making the upstream graphics stack behave better as a system: more efficient when idle, more robust across firmware interfaces, and better aligned with the expectations of the Linux kernel infrastructure.
Last week the Embedded Recipes conference was held in Nice, France.
Igalia was sponsoring the event, and like last year, my colleague Martín and myself were attending.
Unlike last year, we weren’t presenting, which for me means less stress and more opportunities for hallway conversations.
The event was extremely well organized, in a really cool venue (Parc Phœnix, in Nice) for the second year in a row. Kudos to the team at BayLibre!
The selection of talks was overall quite interesting and relevant. Here are a few of my personal highlights:
Yocto Project and the Cyber Resilience Act where Paul Barker (Yocto Project) gave a few relevant definitions (Product with Digital Elements, stewards vs manufacturers) and discussed how this affects the Yocto project, which is essentially tooling, and what the project plans on implementing to remain compliant. [Recording]
U-Boot on boot core as an always-on debug tool where Marek Vasut presented a clever use of the separate Cortex-M33 core used for boot only to run U-Boot to get access to the Cortex-A core that runs Linux. This is intended for development purposes only, not to be deployed in production. Really cool if you’re into that sort of low-level bringup work. [Recording].
A Distributed Phone CI for postmarketOS where Pablo Correa Gómez walked the audience through the different attempts at implementing a CI pipeline running on physical phones by the postmarketOS project. This involved advanced custom hardware design, and the use of CI-Tron as the orchestrator. [Recording].
Four NPUs, One Stack, Zero Blobs: Edge AI Acceleration in Mainline where Tomeu Vizoso presented his work on the kernel userspace APIs and Mesa drivers to enable a truly open-source AI stack. [Recording].
My personal interests normally tend to drive me towards higher-level concerns and constructs, which is why I feel I learnt so much in just two days, being immersed in a sea of hardware and low-level software to control it.
The social event on the beach at the end of the first day was a perfect opportunity for networking, to meet old friends and new folks alike.
Update on what happened in WebKit in the week from May 19 to June 1.
The main feature of this week are new releases: stable ones with many security
fixes, and development ones with the new Skia-based compositor enabled. Additionally,
there was work on Web-facing features, optimizations, spell checking support for
the WPE port, and more.
Cross-Port 🐱
WebKit now supports mirroring
MathML stretchy operators using the OpenType rtlm feature.
Replaced the CloseWatcherManager's
escapeKeyHandler, which will allow other types of close signals to be supported.
Implemented queuing mutation observer
records in the work-in-progress moveBefore() implementation.
Implemented popover integration with
close watcher.
Fixed popover light dismiss to
account for popovertarget on input buttons.
Content filters now create temporary files in the compiled filters
directory, which ensures that a file
rename can always be used to place them at their final location. This avoids
falling back to a regular file copy, which can be slower, when the temporary
directory returned by g_get_tmp_dir() (typically /tmp) is in a different
volume than the filters' storage path configured for
WebKitUserContentFilterStore.
WPE WebKit 📟
Enabled spell checking support in
WPE. The existing implementation for
the WebKitGTK port, which uses the
Enchant library as a backend, was
generalized to provide spell checking support in WPE as well. The feature may
be toggled at build time using the ENABLE_SPELLCHECK CMake option.
Releases 📦️
WebKitGTK
2.52.4 and
WPE WebKit 2.52.4 have
been released; they include a number of fixes for security issues, and it is a
highly recommended update. The corresponding security advisory, WSA-2026-0003
(GTK,
WPE is available as well.
The release also includes a number of small improvements and Web compatibility
fixes.
Additionally, development releases WebKitGTK
2.53.3 and
WPE WebKit 2.53.3 are
available since last week. These include a change to use a new Skia-based
compositor by default, which is intended to replace TextureMapper once ready.
Therefore, bug reports related to website rendering
are particularly welcome when using this and subsequent development releases.
Infrastructure 🏗️
The deprecated and un-maintained Flatpak-based SDK was
removed. Developers working on
the WPE and GTK WebKit ports are encouraged to migrate to the new
SDK.
Depending on the web application, the WPE WebKit memory usage trend can vary. When simple web applications are being processed, the memory consumption tends to be virtually stable (the same) no matter the period. However, when more complicated web applications
are being executed, the memory usage usually grows over time while going back to normal from time to time e.g., when GC / memory pressure mechanism releases all kinds of caches and not-needed memory. Therefore, memory growth itself is not unusual.
Nevertheless, as the memory leaks happen in WPE at times, the memory growth is worth investigating — especially if very rapid or unbounded.
This article presents a structured playbook for investigating such a memory growth and memory leaks in WPE. Rather than diving straight into debugging tools, it starts from first principles: confirming the problem is real, choosing the right
environment to work in, and narrowing down the leaking area before any heavy tooling is involved. The goal is to reach actual debugging as fast as possible, regardless of whether the environment is an embedded device or a desktop machine,
and regardless of how quickly the problem reproduces.
The high-level list of recommended steps to follow is presented below. In a nutshell, the steps 1, 2, and 3 are meant to choose and follow the fastest possible investigation path so that actual debugging of the problem
(step 4) can be started as soon as possible.
The ultimate first step when working with alleged memory leak is to check whether the observed memory growth is actually abnormal. In the case of web browsers in general, the memory growth alone may not necessarily mean something is leaking.
There may be many regular reasons why the browser’s memory usage is growing, but the usual suspects are:
JavaScript-level memory allocations — due to the very nature of JavaScript, the memory it allocates causes the overall web content process memory growth up until the garbage collector (GC) kicks in. Then (from the RSS perspective) some memory
is usually freed. However, as it’s not easy to predict when the GC will be invoked (e.g., when the browser processes an application that performs heavy rendering), it’s possible that memory will grow but remain garbage-collectible.
JavaScript Just-in-Time (JIT) compilation — when not explicitly disabled or limited, the processing of any web application that has JavaScript code associated with it will cause the browser to continuously compile the JavaScript code in the
background so that it executes such code faster in runtime at the expense of memory that is required for storing compiled artifacts.
Caches — as the WPE operates, it caches things such as web resources, style resolution artifacts, textures, glyph atlases, layer tiles, display lists, rasterization artifacts, and many others. Naturally, the cache sizes are limited, however,
if many caches are growing at the same time, they may create an impression of a leak. The difference in that case is, the caches stop growing at some point.
Due to the above, to confirm the memory growth is abnormal, one should usually try the following first:
Triggering memory pressure to force the browser to trigger GC and evict as many cache entries as possible,
If the memory growth doesn’t stop with JIT disabled or its level does not go back to normal after triggering memory pressure, the growth can be assumed to be abnormal, and one can proceed to the next step.
2. Identifying the best setup for reproducing the problem #
When the memory growth is atypical, it needs to be narrowed down in a way that the final debugging is possible. For both narrowing down and the debugging, one should aim at the most flexible development environment along with the smallest possible
web application that reproduces the problem quickly. What it means in practice is — desktop environment along with small demo web application that reproduces the problem. Whilst it’s not always possible to have such an environment, the 3 general
rules are as follows:
Desktop environment is usually better than embedded one in terms of working with memory leaks as it offers minimal overhead (e.g., in terms of compilation times) and huge flexibility in choosing the industry standard tools for profiling/debugging.
Small web application is always better than a big one as long as it still reproduces the same problem in the same amount of time. In such case, a small application minimizes the amount of noise that usually stands in the way of profiling/debugging.
A web application that reproduces the problem quickly is always better than the one that needs much more time for it. The worst thing that can happen in the case of narrowing down memory leaks, is when the memory growth is noticeable or starts
after a very long time such as hours/days+.
Given the above, at this point one should go through the below steps:
Check if the setup is trivial enough already — if the web application reproduces the problem quickly in a desktop environment and is simple enough, one should immediately jump to the Debugging section.
Check if the problem can be reproduced on desktop assuming it originally reproduces on embedded.
Check if the problem can be reproduced faster if it’s not reproducing fast enough.
Check if the web application could be simplified.
Once the setup is simplified as much as possible, one should proceed to one of narrowing down sections depending on the setup. Also, if the setup is still not ideal, one should actively seek opportunities for simplifying the setup
even during narrowing down as it’s likely that some new information will eventually open new possibilities in terms of simplifying setup.
When the problem has been confirmed but there are not enough clues to tell exactly which parts leak, the debugging cannot be started right away. In such case, it’s necessary to narrow down the problem to the browser/application area
that can be easily debugged.
While in some cases narrowing down is not even necessary, quite often it takes orders of magnitude more time than actual debugging, and hence one should pay special attention to this step.
3a. Narrowing down on embedded when the problem takes a long time to reproduce #
This is the toughest situation one can find themselves in. When a problem takes a long time to reproduce (hours/days+), every iteration/test comes automatically with a significant cost. Moreover, when the environment is an embedded one,
rebuilding WPE is usually more time-consuming and the amount of tooling is usually limited — or requires some work to bring it to the image at least.
Due to the above, narrowing down the problem in this setup requires a structured approach with extra care. In such case, the things to check should be approached in steps defined as follows:
in case of embedded devices, extra care is needed when attaching a memory profiler. On low-end devices, memory profilers tend to slow down the application hard enough to trigger otherwise non-existent problems.
in case of embedded devices, one should prefer limiting JIT over disabling it as without it, the JS execution may be slow enough to trigger unexpected scenarios.
Ideally, while checking various things along the above steps, one should batch as many checks as possible within individual tests.
3b. Narrowing down on embedded when the problem reproduces quickly #
When the problem reproduces quickly, the limitations of embedded environment are not that relevant. In this scenario, one should prioritize getting debug symbols (RelWithDebInfo build) into the image and utilizing them by running
the browser with whatever profilers are available. For the specific things to check, one should seek inspiration in the following groups:
However, this time, there are some extra opportunities around tooling:
There should be many more tools available already in the system or available to be installed.
Tools such as memory profilers that could slow down the application making it unusable on embedded, may turn out to be working well when the desktop-class processing power is available.
With the above in mind, it’s worth trying all the tools available with priority because if at least one tool works well, one can save hours of narrowing down.
3d. Narrowing down on desktop when the problem reproduces quickly #
This is technically the simplest possible scenario, so basically, all the possibilities are available. The most time-consuming activity in this case is very likely rebuilding WebKit itself — although it should still be relatively fast.
In such case, just after a few quick checks with the Web Inspector, it’s recommended to get debug symbols (RelWithDebInfo build) and start with tools such as memory profilers.
Other than the above, one should go through the following groups on things to check:
Debugging WPE WebKit is the same as debugging any other C/C++ application on Linux (or Mac if the issue is cross-port and one prefers an Apple port to work with), and hence is outside the scope of this article. Some WebKit-specific information
can be found in the WebKit Documentation article on building and debugging page and therefore is recommended as a first step.
When the problem lies in JavaScript code, the situation is usually fairly straightforward. The majority of bugs in this area should be reproducible across various browser engines and hence a full variety of tooling should be available.
If the WebKit is preferred or if the problem reproduces only there, the tooling available is still very useful and helps debugging problems quickly. The ultimate tool in such case is the
Web Inspector. On official WebKit’s web page there’s entire index of articles on Web Inspector. Among those, the most interesting
read is about Timelines Tab where the most useful debugging can be done. Once the features of Timelines Tab are understood, the next important article is
the memory debugging guide. It dives into the most important Timelines Tab subsections and showcases the work with heap snapshots which is a key. To supplement it,
it’s very important to know the heap snapshot delta feature which is basically about button:
that allows one to inspect the delta-snapshot between 2 snapshots. It’s critical as it answers the question on what JS objects were added between the base snapshot and the later one. If some objects are piling up, it immediately shows
which ones.
One important note on snapshots is that in some cases when using Web Inspector is not possible, one can generate the snapshots manually from the web engine’s C++ code by just calling GarbageCollectionController::singleton().dumpHeap(); at
some appropriate moment. In this case, the dump will be written to standard output. It can be then turned into a file and imported from any Web Inspector using Import button.
As the Timelines Tab with its subsections should be able to answer on what happens, to understand why it actually happens, the last missing piece is the JS debugger within Web Inspector. It’s not very different to debuggers in
other engines, but it’s worth checking a dedicated article on it just to understand the capabilities.
Even if the WPE is running with default settings in release mode, there are plenty of useful things that can be checked while the browser is still running:
Identifying which WebKit process allocates abnormally,
there are multiple ways to do this, but usually it’s as easy as using ps utility.
Identifying how fast the process in question allocates the memory,
this is useful to know at least for comparison purposes, but it may hint some problems already if the numbers correlate with what web application does.
Checking logs from stdout, stderr, and journal (using journalctl).
in short, memory pressure triggers the cleanup of the majority of caches along with GC. Therefore, if this is able to bring memory back to normal level, then the problem is about caches, JS Heap / GC, or fragmentation.
even if the debug symbols are not present, this may be useful to see what data is being captured and how the web application behaves when slowed down by profiler.
even if the debug symbols are not present, various tools offer different perspectives on what the browser is doing. In some cases, such information may reveal some anomalies that may be related to the main issue.
Cross-checking with other browsers,
if other browsers show a similar pattern of memory usage, it’s very likely the problem lies in web application itself. Otherwise, it strongly suggests a bug in the WPE.
Cross-checking with other ports,
if any other WebKit port shows a similar pattern of memory usage, it allows one to narrow down the area in the code a bit based on what port it is:
if the same behavior is visible in any of Apple ports, the problem is most likely related to cross-platform code,
if the same behavior is visible only in GTK port, then the problem is most likely related to GLib-related part, coordinated graphics part, GStreamer-related part, or others that are shared.
while generic logs may hint some unusual behavior, more specific ones such as GC logs (JSC_logGC=1) may be used to check how the individual JS heap sizes evolve over time and how GC behaves. If it’s JavaScript
leaking the memory, this log will quickly provide the evidence.
both breakdown and trend of memory usage in the memory timeline after doing a bit of recording,
the effects of takeHeapSnapshot() invoked from JS console:
as this function usually triggers GC internally, it may be used to check how much RSS memory is reclaimed by GC in isolation (followed up by scavenger),
as this function takes a JS heap snapshot, it then can be used to explore manually if its contents point towards something interesting.
there are at least a few places (levels) where JIT compilation engine allocates memory. If limiting doesn’t resolve the issue completely, it’s likely the engine itself leaks some memory around temporary helper-heaps such as AssemblerData etc.
some environment variables and runtime preferences change the behavior of the web engine significantly. If changing one of them makes the problem go away, it usually helps to narrow down the problematic area quickly.
Running WPE with system malloc (environment variable Malloc=1) and checking the memory usage,
when one suspects bmalloc/libpas issues with fragmentation or scavenger, it’s worth running a browser with system malloc to compare the memory evolution over time against the bmalloc/libpas.
if triggering memory pressure is not possible, an alternative solution is to limit the device memory so that the browser is under constant memory pressure.
stack traces — to see what parts of engine are particularly active as it may hint some problematic area,
WebKit marks — to see what the engine is doing as well as quantitative data in marks such as EventLoopRun etc. as in those cases the numeric value trends may reveal resource pile up.
as WPE allows switching to system malloc as an allocator, it’s possible to use custom malloc implementation with instrumentation such as gperftools. For that, the recommended read is
this article from fellow Igalian, Pablo Saavedra.
the data produced by memory sampler is roughly the same as inspector’s memory timeline, however, it’s much more convenient as it doesn’t need web inspector at all.
when memory growth seems to be related to DOM mutations, it’s worth enabling and reporting node statistics periodically — in some cases, it may directly suggest what the problem is about.
Building and running with malloc heap breakdown,
when all other means fail, a very good last-resort approach for investigating memory usage statistics via a debug-only WebKit feature called Malloc Heap Breakdown. The details can be found in
the dedicated article about it.
On very rare occasions such as memory fragmentation or allocation issues, it may be worth checking the libpas (low-level memory allocation and management library)
statistics as WPE uses it by default on the vast majority of platforms.
As WPE WebKit uses multi-process architecture, there are multiple processes that can be checked, although the most interesting one is usually the Web Content Process. Once the PID of the given process is determined (e.g., using ps utility)
the usual steps to check detailed memory statistics are:
cat /proc/<PID>/status or cat /proc/<PID>/statm for very basic statistics,
pmap -X <PID> - for detailed statistics (if available),
cat /proc/<PID>/smaps_rollup and cat /proc/<PID>/smaps for detailed statistics (requires CONFIG_PROC_PAGE_MONITOR kernel configuration option).
WPE uses a so-called Memory Pressure Monitor to observe the memory usage in the system and to react if there’s not much memory left. The default thresholds are specified in MemoryPressureMonitor.cpp and usually are
90% for non-critical and 95% for critical response. Depending on the response, WPE schedules GC and clears internal caches immediately.
As the above is usually on by default, one can leverage it to trigger GC (along with cache cleanups) by filling up the available memory in the OS to 95+%. There are many ways to allocate memory, yet the simplest is using stress:
e.g. stress --vm 1 --vm-bytes 1024M --vm-keep to allocate 1024 MB.
When attaching any memory profiler, unless one wants to profile only native allocations (Skia, GStreamer, ICU, etc.), the key is to use Malloc=1 environment variable on WPE startup so that bmalloc uses system malloc instead of libpas.
Also, if WebKit is using a sanboxed mode in given configuration, it’s usually necessary to use WEBKIT_DISABLE_SANDBOX_THIS_IS_DANGEROUS=1 as well. Then the commands are as follows:
to attach heaptrack:
heaptrack -p <PID> so e.g. heaptrack -p $(pgrep WPEWebProcess) (see this article for details),
to run with valgrind’s massif (as attaching to running process is not possible):
valgrind --tool=massif --trace-children=yes <WPE-BROWSER-COMMAND> (see this article for details).
If memory profilers are unusable or unavailable, it’s worth checking if other tools are present and experimenting a bit with them if so. In some cases, tools other than memory profilers may give some hints on further investigation
or reveal a suspicious pattern within application execution. Some ideas for experiments with various tools are listed below:
strace:
strace -c -p $(pgrep WPEWebProcess) — strace called with -c gives a nice summary of system calls executed by the traced application. It can be useful to check the overall syscall usage pattern to see if there are any anomalies.
strace -p $(pgrep WPEWebProcess) -e trace=mmap,munmap,mremap,madvise -tt — strace focused on mmap()-related system calls may be useful to debug libpas.
perf:
perf record -F 999 -ag -p $(pgrep WPEWebProcess) -- sleep 60 — regular recording with perf can be very useful, especially if symbols are available. With that, one can generate
flamegraphs and investigate what’s going on in the browser. While it’s not about profiling memory, it may be helpful to narrow down at least a bit.
perf record -F 999 -e syscalls:sys_enter_mmap,syscalls:sys_enter_munmap,syscalls:sys_enter_mremap:sys_enter_madvise -ag -p $(pgrep WPEWebProcess) -- sleep 60 — perf focused on mmap()-related system calls is much more superior
than e.g. strace as it also records stack traces. Therefore, if debug symbols are present, and if the memory growth is very rapid, it’s very likely the libpas mmap() stacktraces will lead to the growth origin statistically.
perf trace -e mmap,munmap,mremap,madvise -p $(pgrep WPEWebProcess) — this is very much similar to strace focused on mmap()-related system calls as it shows a live preview of what’s happening.
sysprof:
sysprof-cli -f — while running system-wide sysprof won’t make WPE push marks into it, the profiling trace may still be useful to some degree, especially if debug symbols are available.
Limiting JIT can be achieved via environment variables:
JSC_jitMemoryReservationSize=<BYTES> to limit JIT memory usage (the limit is semi-strict as some JIT compilation engine buffers are limited by this value indirectly),
JSC_useFTLJIT=false to disable FTL tier,
JSC_useDFGJIT=false to disable DFG and FTL tiers,
JSC_useBaselineJIT=false to disable Baseline, DFG, and FTL tiers.
WPE is a fairly complex piece of software and hence it offers various logging capabilities related to WebKit itself, as well as to related libraries. The vast majority of logging can be controlled via environment variables:
WEBKIT_DEBUG=all to enable all logging channels,
WEBKIT_DEBUG=Layout,Media=debug,Events=debug to enable selected logging channels,
JSC_logGC=2 to enable JS garbage collector logs,
GST_DEBUG=4 to enable gstreamer (multimedia-related) logs (see the documentation),
G_MESSAGES_DEBUG=all to enable GLib-level logs.
If MiniBrowser (or similar browser) is used, one can also set a runtime preference to enable JS console.log(...) logging to the standard output:
Enabling WPE’s remote web inspector is a twofold process:
The first step is to run WPE with the proper environment variable so that it starts listening on IP:PORT using tcp socket:
WEBKIT_INSPECTOR_SERVER=IP:PORT is the most reasonable option as it uses inspector:// protocol that can be utilized by WebKit-native browsers such as GNOME Web (Epiphany) or Safari,
WEBKIT_INSPECTOR_HTTP_SERVER=IP:PORT is a less preferable alternative that uses HTTP protocol and technically works from any browser. However, no seamless integration is guaranteed in this case.
The second step is to connect from a regular web browser to the WPE:
using inspector://IP:PORT/ if native inspector server was started,
using http://IP:PORT/ if HTTP inspector server was started,
forwarding the ports using socat tcp-l:PORT,fork,reuseaddr tcp:IP:PORT if the WPE is running in unreachable network.
Experimenting with environment variables and runtime preferences #
The most outstanding environment variables changing the behavior of WPE are the following:
WPE_DISPLAY — assuming the new WPE platform API is used, this environment variable allows one to switch the pre-defined platform implementation thus
changing a platform-facing part of graphics pipeline. The valid options are:
WPE_DISPLAY=wpe-display-headless — for headless implementation,
WPE_DISPLAY=wpe-display-drm — for direct rendering manager integration,
WPE_DISPLAY=wpe-display-wayland — for wayland integration,
WEBKIT_SKIA_ENABLE_CPU_RENDERING — when set to 1, rendering the DOM contents to the layers is done using Skia CPU backend instead of GPU one.
The most outstanding runtime preferences changing the behavior of WPE are the following:
CanvasUsesAcceleratedDrawing — when disabled, 2D canvas will use Skia CPU backend instead of GPU one,
LayerBasedSVGEngine — when enabled, WPE uses a different SVG engine internally,
AcceleratedCompositing — when disabled, WPE uses experimental, non-composited mode that bypasses all of the compositor work.
On desktop, the simplest way to get release with debug symbols is to utilize CMake’s build type by using -DCMAKE_BUILD_TYPE=RelWithDebInfo within WPE build command, so:
and potentially INHIBIT_PACKAGE_STRIP to control whether debug symbols should be kept with the binary or not. This may be necessary occasionally as some tools have problems reading .gnu_debuglink and therefore work only
with symbols included in the binaries.
WebKit works pretty well with all kinds of sanitizers. To build with any of them a CMake-level helper called ENABLE_SANITIZERS can be used by specifying -DENABLE_SANITIZERS=address, -DENABLE_SANITIZERS=leak etc. With that, the command for
building e.g. on desktop could look like:
Libpas statistics are a debug-only feature that can be enabled by changing 0 of #define PAS_ENABLE_STATS 0 to 1 in Source/bmalloc/libpas/src/libpas/pas_config.h and then running WPE with environment variable PAS_STATS_ENABLE=1.
Like most people, I've been playing with agents to see where they're helpful,
where they're not, and what kind of workflows are a good match for me. One
area I've found friction is in iterating on a piece of code - written by me or
otherwise. I can describe the relevant section and my question/request in
command line chat, but it would be better to do so directly inline and have
the LLM pick it up.
at-agent is a super
minimal approach for picking out such directives from your worktree and
processing them.
This is very much a "worse is better" approach. A separate structured channel
for attaching questions or requests to spans of code would have advantages.
But that requires an interface for creating and editing such annotations as
well as logic for handling edits after the annotation was made. Sticking
@agent comments directly inline means it's trivial to intermingle manual
edits with requests for action, it's trivial to keep comments attached to the
region they were intended for, and reviewing and editing them at the file or
repository level is easy through git diff and your text editor of choice.
You could get away with just asking your LLM of choice to "find all
comments prefixed with @agent in this codebase, treat them as directions to
you, action them, and then remove them". But I still believe in building on
solid primitives, and limited as this little script is, I'd rather lean on its
deterministic behaviour and reduce the number of round trips and tool calls
the LLM needs to handle successfully. So far it's been helpful for some kinds
of tasks and a handy tool to have in the toolbelt.
There are surely no end of IDE-integrated solutions and vim plugins that offer
something similar. aider also supports 'AI'
comments but relies on the model to
remove them after the fact.
Interface
at-agent doesn't try to understand language-specific comment syntax. It looks
for a whole line that starts with optional whitespace, then at least two
punctuation characters such as //, ##, or ///, then whitespace and
@agent. A following ! marks an action request rather than a question, and
the rest of the line is the request text. Subsequent lines with the same
comment prefix are consumed as part of the same @agent directive.
What this means is that you might write something like this:
Example: // @agent explain why std::vector isn't used here. How does the
Example: // custom vector compare in terms of reallocation strategy?
The Example: prefix is only there to keep this blog post from containing live
annotations. Without it, running at-agent over the Markdown file would treat
the example itself as a real request and remove it.
Or for an action request:
Example: ## @agent! split this into a helper and update the two other callers
@agent is a comment/explanation request, and @agent! is a request to make
an edit. Only whole-line annotations are supported. If you want to nest a
request inside a long comment, just tweak the prefix appropriately, e.g.:
Example: // This is a multi-line comment. We want to place a directive in it.
Example: /// @agent explain the paragraph below, with a worked example
/// alongside appropriate source code snippets.
Example: // Normal comment continues here.
Running the tool removes the annotation lines from the working tree and emits
something like:
The user manually added these annotations for you, the agent, to react to.
They are either comment/explanation requests, which ask you to explain nearby
code or answer the user's question without editing files, or action requests,
which ask you to investigate and make the requested code change.
The @agent remark lines have already been removed from the working tree.
Relevant line numbers refer to the files after remark removal.
1. example.cc
kind: comment/explanation request
relevant line number: 42
text:
@agent explain why std::vector isn't used here. How does the
custom vector compare in terms of reallocation strategy?
nearby context before removal:
...
Usage
at-agent can be pointed at specific files listed in command line arguments
(passing files selects args mode automatically), or via --discover=rg
recursively grep the current working directory, or via
--discover=inodes (or indeed, no args) walk the current working directory
recursively to find inodes flagged as being modified recently and potentially
containing @agent directives. For that default mode, the idea is you set
your text editor to append to that list of inodes as you edit files and leave
@agent directives in them. This is particularly helpful to avoid expensive
greps on large trees. There is also --dry-run, which reports directives
without removing annotation lines.
The use of inode numbers rather than path names means that this works
comfortably in the scenario where you are editing files in your normal
environment, but an agent is running in a sandbox and so
may have paths mounted at a different location.
You can just add something like this to your .vimrc (the filter is
imprecise, but this doesn't matter as at-agent will just do nothing for
files that have no valid directives):
Run at-agent from the repository root in the agent session.
There are all kinds of ways this could be integrated into a harness, but I
have a fondness for no integration at all, meaning it's easy to switch between
different options. e.g. just give a prompt such as "Run at-agent and action
its output.".
If using shandbox or similar, the list of inodes that potentially contain
directives needs to be exposed at the expected location. You can add something
like this to .shandbox_meta/init (or ~/.config/shandbox/default-init):
My immediate thought was to throw two spans in the header cell and
position or grid them within that cell, but the accessibility of that
seemed… questionable. It’s also what
Wikipedia already does, and we here at meyerweb are nothing if not
obsessed with finding new ways to do niche stuff. So I tried something
different. But is its accessibility any better?
If you want to see it as a live example, it’s over at
Codepen. Most of the text in the table is what macOS Preview OCRed
out of the original image, which I kept intact because I think it’s
funny. Anyway, here is the original markup I came up with for the
table head, which you should not use:
So one row for the headers across the top of the table, including the
top-left label that goes with them, and then another row with the header
that relates to the row headers for the rows below. That is to say, the
row-scoped table header in each of the rows in the table’s bodies (it
has more than one), like this:
The thing is, when I ran the idea past accessibility experts like Alice Boxhall and Adrian Roselli, they identified
a problem: Not having a full row of cells, as is the case for the second
header row, fails WCAG
1.3.3. The suggested fix was to rowspan most of the cells in the
first row, like this:
With that, table navigation wasn’t perfect, but it seemed decent, so
we could move forward.
In terms of presentation, to get the upper-left header cell to do the
split-diagonal thing, I relatively position the
<thead> and then absolutely position the second row
in the table head to sit over top of the first, pinned to the bottom
left corner.
I fiddled around for a bit with trying to use a grid instead, but it
didn’t really add anything that positioning didn’t already provide and
threw some other wrenches into the works, like having to convert the
entire table into a grid so the columns would stay aligned, so I decided
to just stick with the positioning.
Then I throw a linear gradient background into the first row’s first
cell to draw the diagonal, and everything’s thus more or less as
intended, visually speaking. (That diagonal could also be an SVG, in
fact probably should be in production, but I was seeing how an all-CSS
solution might work so a gradient is where things stand.)
There are some layout caveats with this approach, but they’re pretty
much the same as other solutions I saw: primarily, the two bits of text
that the diagonal visually separates can stick out of their respective
halves of the split cell, or even overlap each other. Also, you
might need to explicitly set a minimum height of the first header row,
in order to not exacerbate the overlap risk just described.
And then there’s a really big caveat: Safari, as of this writing,
doesn’t handle the layout at all well, because it doesn’t apply
relative positioning to <thead> (or
<tfoot> or <tbody>, but at least
it does <tr>s). I went to file a bug and found there’s already
one open, so maybe this will be fixed in the near future. I figured
out a way to get at least close to the intended result while still
allowing line-wrapping in the column header cells, but it mangled the
layout in Firefox and Chrome. In the end, to work around the problem, I
delved into browser
strangeness (at the suggestion of Marius Gundersen) and settled on
the following:
/* this is gross and I hate it but it works to fix
Safari’s layout of the table’s top headers */
@supports (font: -apple-system-body) {
thead tr:nth-child(1) th {
white-space: nowrap;
}
thead tr:nth-child(2) th {
position: static;
display: block;
margin-block: -1.5lh 0;
padding-block: 0;
text-align: start;
transform: translateY(0.25lh);
}
}
Thanks, I hate it! But it works, and I try to be pragmatic.
Anyway, the point being, what I’ve done here feels more accessible
to me, and basic testing by both me and Adrian didn’t reveal any major
problems, but I still worry about the positioning dorking things up for
the users of screen readers I don’t have access to. So I throw it to the
audience, particularly the accessibility-technology-using part of the
audience: does this solution fall down for you, or is it good enough?
Please let me know!
shandbox is a simple
Linux sandboxing script that serves my needs well. Perhaps it works for you
too? No dependencies between a shell and util-linux (unshare and nsenter).
In short, it aims to provide fairly good isolation for personal files (i.e.
your $HOME) while being very convenient for day to day use. It's designed to
be run as an unprivileged user - as long as you can make new namespaces you
should be good to go. By default /home/youruser/sandbox shows up as
/home/sandbox within the sandbox, and other than standard paths like /usr,
/etc, /tmp, and so on it's left for you to either copy things into the
sandbox or expose them via a mount. There's a single shared sandbox (i.e.
processes within the sandbox can see and interact with each other, and the
exposed sandbox filesystem is shared as well), which trades off some ease of
use for the security you might get with a larger number of more targeted
sandboxes. On the other hand, you only gain security from a sandbox if you
actually use it and this is a setup that offers very low friction for me. The
network is not namespaced (although this is something you could change with a
simple edit). If you do want more than one sandbox environment, see the
relevant section below.
Usability is both subjective and highly dependent on your actual use case, so
the tradeoffs may or may not align with what is interesting for you!
Bubblewrap is an example of a
mature alternative unprivileged sandboxing
tool that offers a lot of configurability as well as options with greater
degrees of sandboxing. Beyond that, look to
Firecracker based solutions or
gvisor. shandbox obviously aims to provide a
reasonable sandbox as much as Linux namespaces alone are able to offer, but if
you're looking for a security property stronger than "makes it harder for
something to edit or access unwanted files" it's down to you to both carefully
review its implementation and consider alternatives. The recent spate of
disclosed localprivilegeescalationvulnerabilities
is helpful to keep in mind as a reminder of the limits of this namespacing
based approach.
Usage example
$ shandbox run uvx pycowsay
initialised sandbox at /home/asb/sandbox
created default ssh config at /home/asb/sandbox/.ssh/config
to add an init hook, create an executable script at: /home/asb/sandbox/.shandbox_meta/init
started (pid 1589289)
Installed 1 package in 5ms
------------
< Hello, world >
------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
$ shandbox status
running (pid 1589364)
log:
2026-02-11 13:02:51 stopped
2026-02-11 13:05:06 started (pid 1589289)
$ shandbox add-mount ~/repos/medley
mounted /home/asb/repos/medley -> /home/sandbox/medley
$ shandbox run ls -lh /home/sandbox/medley/README.md
-rw-r--r-- 1 sandbox users 2.7K Feb 11 20:02 /home/sandbox/medley/README.md
$ shandbox run touch /home/sandbox/medley/write-attempt
touch: cannot touch '/home/sandbox/medley/write-attempt': Read-only file system
$ shandbox remove-mount /home/sandbox/medley
unmounted /home/sandbox/medley
$ shandbox add-mount --read-write ~/repos/medley
mounted /home/asb/repos/medley -> /home/sandbox/medley
$ shandbox run touch /home/sandbox/medley/write-attempt
$ shandbox list-mounts
/home/sandbox /dev/mapper/root[/home/asb/sandbox]
/home/sandbox/medley /dev/mapper/root[/home/asb/repos/medley]
shandbox enter will open a shell within the sandbox for easy interactive
usage. As a convenience, if the current working directory is in
$HOME/sandbox (e.g. $HOME/sandbox/foo) then the working directory within
the sandbox for shandbox run or shandbox enter will be set to the
appropriate path within the sandbox (/home/sandbox/foo in this case). i.e.,
the case where this mapping is trivial. Environment variables are not passed
through.
You can also explicitly control the working directory used by shandbox run
or shandbox enter by setting SB_PWD to an absolute in-sandbox path. If
SB_PWD isn't set, paths within the sandbox home are translated to
/home/sandbox/..., and some host paths that are directly visible in the
sandbox (such as /tmp, /usr, /etc, and similar) are used as-is.
Functionality overview
shandbox new <dir>: Initialise a sandbox directory, setting up the
.shandbox_meta layout and a default .ssh/config suitable for use with
share-ssh. If ${XDG_CONFIG_HOME:-$HOME/.config}/shandbox/default-init
exists it is copied to .shandbox_meta/init.
shandbox start: Start the sandbox, creating the necessary namespaces and
mount layout. Fails if the sandbox is already running. If the selected
$SANDBOX_DIR hasn't been initialised yet, it is initialised first. If
present, the init script in .shandbox_meta/init is always run.
shandbox stop: Stop the sandbox by killing the process holding the
namespaces. Fails if the sandbox is not running.
shandbox status: Print whether the sandbox is running and if it is, the
pid. Also print the last 20 lines of the log.
shandbox enter: Open bash within the sandbox, starting the sandbox first
if it's not already running.
shandbox enter-root: Open bash within the outer "root" namespace. This is
mostly useful for debugging the namespace or mount layout.
shandbox run <command> [args...]: Run a command inside the sandbox. The
current working directory is translated to an in-sandbox path when this is
straightforward, and SB_PWD can be used to override it explicitly. Starts
the sandbox first if it isn't already running.
shandbox add-mount [--read-write] <host-path> [<sandbox-path>]: Bind-mount
a host path into the running sandbox. Mounts are read-only by default; pass
--read-write to allow writes. The sandbox must already be running. Both
directories and individual files are supported, and if no sandbox path is
provided the host path basename is mounted under /home/sandbox.
shandbox remove-mount <sandbox-path>: Remove a previously added bind mount
from the running sandbox.
shandbox list-mounts [--all]: List mounts visible from the sandbox. By
default this is restricted to mounts under /home/sandbox; --all shows
the full namespace mount table.
shandbox share-ssh <socket-name> <ssh-target> [ssh args...]: Expose a
host-side ssh ControlMaster connection inside the sandbox without copying
private keys or ssh-agent state into the sandbox. The sandbox directory must
already have been initialised with shandbox new. See below.
Minimum requirements and Ubuntu compatibility
Two core requirement are the ability to create a new user namespace, and a
recent enough util-linux release (2.41 or newer should work). The earliest
Ubuntu release known to work is 25.10 (25.04 won't work, as its util-linux is
too old).
Recent Ubuntu releases restrict unprivileged user namespaces through AppArmor,
meaning additional settings are required. Chromium's AppArmor user namespace
restrictions
notes
describe this policy and workarounds.
You can alternatively add an AppArmor profile covering the path you install
shandbox to. e.g. put this at /etc/apparmor.d/shandbox and then do sudo service apparmor reload:
abi <abi/4.0>,
include <tunables/global>
profile shandbox /usr/local/bin/shandbox flags=(unconfined) {
userns,
}
Self-contained sandbox directories
A sandbox is represented by a normal directory, defaulting to $HOME/sandbox.
The files visible as /home/sandbox live directly in that directory, and
shandbox's own state lives under .shandbox_meta inside it. That means a
sandbox is self-contained: you can create another one with shandbox new ~/other-sandbox, select it by setting SANDBOX_DIR (using the absolute path
it prints, or a shell-expanded path such as ~/other-sandbox), and it will
have its own root layout, runtime directory, pid files, log, init hook, and
ssh socket directory.
For example:
$ shandbox new ~/other-sandbox
$ SANDBOX_DIR=~/other-sandbox shandbox run pwd
/home/sandbox
$ shandbox new ~/throwaway-sandbox
$ SANDBOX_DIR=~/throwaway-sandbox shandbox status
stopped
Sandboxes in different SANDBOX_DIR have independent state and home
directories. The contents of .shandbox_meta is hidden from inside the
sandbox by mounting an empty tmpfs over it. I don't personally use separate
sandboxes outside of testing purposes. But it's simple functionality to
provide and it's easy to imagine cases where this is useful.
Sharing ssh connections
One aspect of this I'm pretty pleased with is the mechanism for exposing an
ssh connection without having to share any key material or password, or set up
credentials specifically for the sandbox. shandbox share-ssh will create an
ssh ControlMaster and expose the control socket in the sandbox home directory.
The sandbox can use this connection for as long as that ssh process lives.
e.g.:
$ shandbox share-ssh buildbox user@example.com
shandbox share-ssh: connecting (user@example.com) using /home/asb/sandbox/.ssh/sockets/ext%buildbox
shandbox share-ssh: connected
shandbox share-ssh: from inside the sandbox, use ssh ext%buildbox
Then from inside the sandbox:
ssh ext%buildbox
The ext%... name format is recognised thanks to a config fragment installed
in ~/.ssh/config within the sandbox.
Init hooks
The main way of customising sandbox setup outside of hacking on the shandbox
script yourself is through an "init script" which will be called for every
shandbox start (implicit or explicit). Just place your script in
.shandbox_meta/init, and if you want a default one that is copied into that
location for you when creating a new sandbox then put it in
$XDG_CONFIG_HOME/.shandbox/default-init.
As the script is executed for each shandbox start, you should either ensure
it is idempotent or have it create and check for some marker file so it exits
early for subsequent invocations.
The following environment variables are passed through:
SHANDBOX_SELF: Path to the shandbox script being run.
The core sandboxing functionality is provided by the Linux namespaces
functionality exposed by
unshare
and
nsenter.
The script's
implementation should be
quite readable but I'll try to summarise some key points here.
The goal is that:
Within the sandbox, you appear as an unprivileged user, with uid and gid
equal to your usual Linux user.
It should be possible to expose additional files or directories to the
sandbox once it's running.
Applications running within the sandbox have no way (modulo bugs or
vulnerabilities in the kernel or accessible applications) of reaching files
on the host filesystem that aren't explicitly exposed.
To underline: This is a goal, it is not a guarantee.
It's possible to launch multiple processes within the sandbox which can all
see each other, and have the same shared sandboxed filesystem.
This is all doable as an unprivileged user.
To implement that:
Two sets of namespaces are used to provide this isolation: the outer
'shandbox_root' has the user mapped to root within the namespace and retains
access to standard / (allowing us to mount additional paths into after the
sandbox has started). The inner 'shandbox_user' represents a new user
namepsace mapping our uid/gid to an unprivileged user, but other namespaces
are shared with 'shandbox_root'. Sandboxed processes are launched within the
namespaces of 'shandbox_user'.
The process IDs of the initial process within 'sandbox_root' and
'sandbox_user' are saved and recalled so the script can use nsenter to
enter the namespace. On newer systems this uses util-linux's getino to
store a pid:inode pid reference while on older systems it stores pid plus
process start time.
To help make it easier to tell when you're in the sandbox, a dummy
/etc/passwd is bind-mounted naming the current user as sandbox.
When shandbox start is executed, the necessary directories are bind
mounted in a directory that will be used as root (/) for the user sandbox
in $SANDBOX_DIR/.shandbox_meta/root. This happens within the sandbox_root
namespace, which then uses unshare again to create a new user namespace
with an unprivileged user, executing within a chroot.
A small private /dev is created rather than exposing the host /dev
wholesale. Basic devices such as /dev/null, /dev/zero, /dev/random,
and /dev/tty are provided, along with a private devpts instance.
'sandbox_root' retains access to the host filesystem, which is necessary to
allow mounting additional paths after the fact. Without this requirement, we
could likely rewrite shandbox start to use pivot_root.
The host-side .shandbox_meta directory is hidden inside the sandbox by
mounting an empty unreadable tmpfs over /home/sandbox/.shandbox_meta.
When /etc/ssh/ssh_config.d exists, shandbox stages a user-owned copy of
that directory and bind-mounts it over the original inside the sandbox. This
avoids OpenSSH refusing to process included config snippets that appear as
owned by nobody in the inner user namespace.
Article changelog
2026-05-30: Added note about Ubuntu compatibility and util-linux
requirements.
2026-05-26: Update article to reflect a wide range of improvements to the script.
share-ssh functionality.
init hooks
Easy to use support for multiple independent sandboxes (with sandbox state
now localised to a single directory).
This post summarizes my talk at Wasm I/O 2026: Five Years of JavaScript on WebAssembly. The recording will be uploaded to the 2026 playlist.
By the end, you should have a clear picture of how JavaScript on WebAssembly evolved from an experiment into a production toolchain, the design decisions that shaped it, and where I think it's heading next.
The talk is structured into 5 main sections, each representing a key event during the past 5 years (2021 - 2026) of development of JavaScript on WebAssembly and Javy, which is the leading character of the talk.
A fair and usually common question that gets asked is why do you need to run JavaScript on WebAssembly? Isn't WebAssembly meant to run in the browser and alongside JavaScript? It all depends on the use-case. WebAssembly's inherent secure-by-default and near native performance properties are very appealing for use-cases that involve executing untrusted code server side.
Thus, in 2021 I had set myself the objective of creating a toolchain to make it extremely easy and accessible to target WebAssembly. Additionally, the toolchain should also:
Produce the smallest possible WebAssembly modules, to minimize the operational infrastructure cost of managing the native binaries produced by compiling Wasm to machine code and to be competitive with other WebAssembly toolchains.
During 2022 Javy became production ready: it was put in the hands of developers and started serving real production use-cases.
The first production ready version included an extremely simple interface for building WebAssembly modules:
javy build index.js -o index.wasm
And it also included a feature to generate extremely small WebAssembly modules, in the range of 1kb - 16kb. During Wasm I/O 2023, Jeff Charles presented the underlying technical details that make this possible.
2023 brought no major technical milestones, but an equally important shift happened: Javy moved to a hosted-project model under the Bytecode Alliance.
While Javy was initially designed for a specific use-case, it eventually found its way into multiple companies operating in the WebAssembly space. This adoption prompted us to rethink its governance model, shifting towards an open, community-driven model that ensures a healthy environment for the project's growth and development.
During 2024, we set out to solve the problem of profiling JavaScript programs on WebAssembly. It is critical for developers to understand how their programs behave inside WebAssembly in order to perform optimizations where applicable. This post intentionally skips over all the technical details behind the research and implementation work; however, if you're interested in reading further, you can check out the first post of my series, A profiler for JavaScript on WebAssembly, Part 1, which accompanies the work happening upstream to materialize this research. The series is not complete, but the first part lays the foundation for why this is important and the challenges behind it.
Javy's design philosophy was always to provide a minimal and lightweight JavaScript on Wasm implementation by default, allowing for extensibility where appropriate. The very initial version of an extensible runtime required users to assemble their own runtime from a set of official Rust crates. This approach was not ergonomic and required a non-trivial knowledge of Javy's internals to get right.
During 2025, we overhauled the extensibility story, making the Javy CLI the canonical starting point of extensibility, promoting the CLI from a simple entry point for the basic use-case into a build tool capable of orchestrating JavaScript-on-WebAssembly builds for third-party use cases.
The official RFC behind this work contains all the technical details.
2026 — A preliminary look at potential throughput improvements #
WebAssembly, as a Harvard Architecture, does not allow just-in-time code generation yet. Thus, any dynamic language running on WebAssembly which requires just-in-time generation as a means to improve throughput is limited to interpreter mode only. This is the case for Javy today: it principally relies on QuickJS' interpreter for code execution. Even though QuickJS' interpreter is very well optimized, there is still room for improvement. Profiles, taken from the work done in 2024 and being upstreamed this year, show that optimizing for:
Field accesses
Closure creation
Function calls
has the potential to considerably improve throughput. More concretely, a recent proof-of-concept of compiling QuickJS bytecode to Wasm, conducted during late 2025, showed that optimizing function calls can improve performance by ~1.2x over the interpreter, and optimizing closure creation, particularly by relying on the Wasm GC proposal, can improve performance by ~1.5x-~3.5x over the interpreter. Note that this work is in its very early days, and the benchmarks were conducted on a very small sample of programs. Our plan is to upstream the compiler as an experimental feature during the upcoming 6-12 months.
What started in 2021 as — "can we make JavaScript on WebAssembly easy?" — has turned into a question we now get to answer in more interesting ways: not just easy, but small, fast, extensible, and soon, possibly, faster.
Sometimes features take a long and winding road on the way to a good solution. We could use your help testing improvements for something that's been somehow developing for about a quarter of a century...
Back in the mid-2000s there was a great debate on where the web was going. The web itself had really exploded and people were really starting to use it as an application delivery platform. Most of the world, including W3C members, seemed to kind of assume that we would get a web for apps instead of documents, and there were several pieces being developed for this. Mozilla had XUL, Microsoft had XAML, Adobe had Flex, even Oracle wound up with this JFX thing. Back then, anyone using these would have definitely noticed that the layout models were different from the web which was then still all abspos and floats. David Baron wrote about this in 2006.
This all brewed for a while until CSS picked up a similar concept. As often happens, they were experimenting with implementations before anyone submitted a public draft. David Baron wrote to the www-style mailing list in June 2008
Much of the specification is implemented in both Gecko and Webkit (with prefixes), and this implementation forms the basis of the formatting model of XUL
This created -webkit-box which was an earlier take on Flexbox.
This is not flexbox's story.
It is instead the strange story of the origins of line clamping, if you can believe it! That's because given this internal ability, Apple added some support for line clamping which used it. Internally, WebKit supported -apple-line-clamp (and later -khtml-line-clamp). This became -webkit-line-clamp and it accidentally escaped the lab and made it into the public releases of Safari.
Given it, one could suddenly have a few lines that would show ellipsis if rendering went beyond that.
As far as I can tell, it was never actually publicized by Apple. Despite this, it was useful enough that as people learned about it, they shared (as we do) and eventually so many people used it that it became something of a de facto standard. This is before the WebKit/Blink fork, and so it wound up in Chrome and later in other chromium flavored browsers, all with the -webkit- prefixes. In the Project Spartan/EdgeHTML era Microsoft found that they needed to support it for compatibility and added support for the -webkit- prefix in April 2018. Firefox added support in July 2019. The fact that it was internally flex related at all changed in most browsers a while back, but this weird winding road led through lot of pains.. Chris Coyier wrote a piece about the state of it in 2013. A few years later, in 2016 Nils Rasmusson wrote CSS Line-Clamp — The Good, the Bad and the Straight-up Broken.
Today, according to chromestatus, it's in over 40% of page loads, and on over 30% of pages in the HTTPArchive crawl — and popularity is still growing.
Interoperability and Correction
Despite all of that, lots of it was not consistent or interoperable.
Lots of it didn't even really make sense internally.
It wasn't well designed.
So, there has been a real effort to create a good solution here for the past few years. Igalia (primarily my colleague Andreu Botella) has been working on it, and started with an explainer that is still pretty good and includes images and lots more info. It is now part of CSS Overflow Level 4, and there is an updated implementation in Chromium — you can try it today by enabling experimental web platform features at chrome://flags/#enable-experimental-web-platform-features. If you flip that flag, you're using it!
Guess what it lets you do now....
.thingr {
line-clamp: 3;
}
So cool that Millie Bobby Brown's mind is blown... (via GIPHY)
It's so simple by default. So good, right?
You can also use the auto value to do this based on some kind of measured value — a max-height, for example:
.thingr {
max-height: 400px;
line-clamp: auto;
}
Great, how can I help?
Excellent, I'm glad you asked!
Well, for one you can try out the new unprefixed line-clamp, it's way nicer. You can read about it in the explainer.
Ask questions (you can send them to Andreu on bluesky or mastodon), or report issues if you find them.
Maybe say "thanks" to Bloomberg Tech for funding the work!
But more importantly: This work also involved reconciling as much as we can in order to share code and tests and standard, well-defined behavior for -webkit-line-clamp and friends. We believe that all of these decisions are good, but we need some time for research and feedback given the scale of existing deployments. Remember — this thing is on over 40% of page loads. That means even a small percentage of regressions is a lot of real pages and real users. Check your sites, let us know if you experience issues related to this, and help us make sure a quarter century of history ends with something everyone can be proud of.
I’ll attend the Media Summit remotely (I’m interested in the discussion about
the usage of Vulkan Video API in embedded devices), then I’ll travel, as other
multimedia folks, to the GStreamer Hackfest. While other Igalians will be at
the Display Next Hackfest and Embedded Recipes.
My goal for the hackfest is to chat with other GStreamer developers about
hardware-accelerated encoders and how to test them, especially those using
VA-API and Vulkan.
Here’s what my multimedia colleagues are planning for the hackfest:
Stéphane Cerveau will talk about new features in
GstPipelineStudio
and its future integration with
GstPrinceOfParser, along with several
core GStreamer improvements.
Alicia Boya will tackle subtle timing issues, out-of-order and race
conditions in frame processing, and other GStreamer bugs.
Xabier Rodríguez Calvar plans to close the issues around static compilation
of gstreamer-rs, including selected plugins with system-deps.
Thibault Saunier will aim to finish upstreaming some new features and focus
on WebAssembly support.
Recently I’ve found myself repeating the same explanations to different people about how to test a V8 patch in Node.js, how to patch the Node.js fork run in V8’s integration CI, or how to get these patches into their repositories/CIs
Update on what happened in WebKit in the week from May 11 to May 18.
For this week we have quite a collection of news! Ranging a variety of improvements
to dialog.requestClose(), rendering fixes, the new Skia-based compositor enabled by
default, and proper versioning and improvements to the WebKit Container SDK, there's
news for everyone.
Cross-Port 🐱
Update the closeWatcher.requestClose() function to no longer require user activation, aligning with the spec.
Implement actually moving the node in the DOM when moveBefore() is called.
Fix handling of nested calls to dialog.requestClose().
Add missing preliminary checks to dialog.requestClose().
Graphics 🖼️
Fixed an issue where background images were unexpectedly stretched, primarily affecting the reCAPTCHA checkmark image.
Added opt-in auto-enter for the WebKit Container SDK - the GTK/WPE wrapper scripts (build-webkit, run-webkit-tests, run-api-tests, etc.) now relaunch themselves inside a pinned wkdev-build podman container when WEBKIT_CONTAINER_SDK_ENABLE_AUTOENTER=1 is set. A new .wkdev-sdk-version file at the repo root pins the SDK image, so the image can be bumped in a PR and validated through EWS. Without the flag, wrappers run on the host exactly as before.
Introduced a proper version scheme for the wkdev-sdk image provided by the WebKit Container SDK so consumers can pin to a known revision. The :latest tag, the WKDEV_SDK_TAG/--tag override and the tag/* branch mechanism are replaced by a single machine-checkable format <major>.<minor>-v<count>-<gitsha> (e.g. 2.53-v1-916f9ef), where <major>.<minor> tracks the WebKitGTK/WPE release cycle, v<count> is the per-cycle SDK build counter, and <gitsha> traces the image back to its source commit. wkdev-create gains a --version switch (full or bare <major>.<minor>). wkdev-update supports updating from latest tag to the new versioning scheme, just run it on your host to update to the latest SDK.
Switched the wkdev-build container from a persistent container to ephemeral podman run --rm --init per invocation. This removes the manual podman rm step necessary whenever container creation arguments changed (which the tooling was not handling by itself), the first-run recursive-chown cost, and the podman start step after host reboots.
I'm not a Yocto developer, so if you are reading this and think there are other
approaches to consider or alternative ways of solving the problem that are
better, please do drop me a note!
Common setup
I'm running on Arch Linux which isn't one of the tested Yocto host
distributions, but seemed to work just fine.
I found I needed to enable the en_US locale:
sudo sed /etc/locale.gen -i -e "s/^\#en_US.UTF-8 UTF-8.*/en_US.UTF-8 UTF-8/"
sudo locale-gen
As is often the case, the workload I'm interested in here is LLVM. If you're
looking to build a sysroot to cross-compile something else, you may need a
slightly different package list.
In this first stanza, we use bitbake-setup to initialise our development
environment. Because there isn't a predefined machine target for riscv32 in
bitbake/default-registry/configurations/poky-wrynose.conf.json, we
avoid selecting machine and will address it later. Importantly, we set a
SSTATE_DIR which will be used for the shared state cache, avoiding
rebuilding packages when not necessary (I'm not totally sure when this isn't
exposed in bitbake-setup settings like dl-dir is). Another relevant
variable is BB_HASHSERVE_BB_DIR which controls where the hash equivalence
database is stored. But with current bitbake-setup this defaults to
SSTATE_DIR, so there's no need to set it explicitly.
With that done, we can source the generated definitions to enter the build
environment (note we're using the default setup directory, you can override it
to something other than poky-wrynose by using --setup-dir-name) and
use enable-fragment to set the qemuriscv32 machine:
This results in 4624 build tasks and takes quite some time to complete if you
haven't run it before (i.e. aren't hitting in the sstate cache). The next
section of this article explores how to produce the needed output while
building much less, but let's finish the job and extract a rootfs from what
was built. I would like to now follow advice in the
documentation
and run runqemu-extract-sdk on the rootfs archive (I submitted a little
patch
upstream)
to fix this command for .zst which was applied:
At this point, you have a sysroot that's almost directly usable for
cross-compiling Clang/LLVM (with --target=riscv32-poky-linux) but there are
three finalisation steps we will perform:
Add an additional symlink to the tree so that upstream Clang's search
procedure for the GCC install finds the correct directory. The combination
of
thesetwo
downstream patches which Yocto applies to its own Clang builds would make
this unnecessary. I'm not sure if upstreaming has ever been pursued.
Convert all absolute symlinks to relative ones. Yocto provides a Python
script for this, which is in our $PATH after sourcing
build/init-build-env.
(Optional) Apply workaround for a ninja
issue
that would otherwise mean incremental builds don't work.
The core-image-minimal recipe above is straightforward, but does a lot more
work than strictly necessary. We can reduce this by instead adding a
dependency-only recipe that explicitly lists the needed build-time
dependencies and contains logic to produce the sysroot.
The do_deploy function implements the sysroot preparation logic that largely
mirrors the previous section. Otherwise, DEPENDS specifies the needed
dependencies (of these, virtual/${MLPREFIX}compilerlibs is a bit magic:
this resolves to the compiler runtime provider which pulls in things like
libstdc++).
Build the sysroot with:
bitbake rv32-llvm-deps-sysroot
This performs ~948 build tasks and will produce the sysroot tarball at
tmp/deploy/images/qemuriscv32/rv32-llvm-deps-sysroot-qemuriscv32.tar.zst.
The sysroot is slightly larger than the one in the section above because it
contains large unstripped static archives like usr/lib/libstdc++.a.
Producing a featureful image bootable in QEMU
We could probably quibble on the definition of "featureful" as listed in the
subheading above. For me, this means an image that boots using systemd and you
can ssh into, roughly approximating what you get from my debootstrap
recipes.
But by adding other packages to the image recipe you can certainly make it
more featureful.
First, let's start to set up the build environment and directories we'll use
for additional recipes. We use distro/poky-altcfg which is just Poky with
systemd as the init
manager.
Some may prefer to split different aspects of image configuration into
independent recipes, but I opt to combine it into one for simplicity (in this
case, just configuring systemd-networkd dhcp and adding a config file that
will enable sudo for our user account):
Use the above config recipe as well as pull in other needed packages.
Add a user account and set passwords of root and user to root and
user respectively. This follows the approach in the Yocto
docs.
Make it so runqemu will configure things so we can connect ssh in via a
Unix domain socket (as done in the debootstrap-based article). Alternatively
you can choose to set QB_SLIRP_OPT = "-netdev user,id=net0,hostfwd=tcp:127.0.0.1:2222-:22" if you'd rather just connect
to localhost:2222.
Now write necessary configuration and build (disabling a number of distro
features that would lead to larger build time). The following results in 4305
build tasks on my machine:
Over the past year, we have continued developing this effort, and I recently had a chance to share an update along with a demo running on a real Apple TV device at BlinkOn 21 in 2026. In this post, I’d like to walk through what has changed since the initial prototype, what works today, and what challenges still remain.
A quick recap
Apple TV runs tvOS, which is derived from iOS, but it comes with important differences. Most notably, tvOS does not provide a WebKit WebView for third-party applications. This means that any application requiring web functionality needs to embed its own web engine. This constraint was one of the key motivations behind exploring whether Blink, originally being ported to iOS, could also be adapted to tvOS.
While the idea sounds straightforward, the reality is more complicated. tvOS lacks several low-level system APIs required for Chromium’s multi-process architecture, which makes it impossible to use the standard process model. On top of that, BrowserEngineKit, which the iOS Blink effort relies on, is not available on tvOS. There are also platform restrictions such as the lack of JIT support, and the input model is fundamentally different since Apple TV relies on a remote control rather than touch or pointer-based interaction. Because of these constraints, our goal has not been to build a full-featured browser, but rather to enable Blink-based web capabilities in a way that works within the limitations of the platform.
Progress over the last year
Over the past year, we have made steady progress toward that goal. One of the most significant milestones is that we have upstreamed the initial tvOS implementation. This means that the work is no longer just an isolated experiment, but part of the upstream Chromium codebase. As part of this effort, we enabled content_shell running on the tvOS simulator and on actual Apple TV devices. Moving from simulator-only execution to running on real hardware was an important step, as it allowed us to validate real-world behavior and platform integration.
We have also improved platform integration in several areas. Crashpad support has been added, and input handling for the Apple TV Remote has been significantly improved. The latter is particularly important because navigating web content with a remote requires a focus-based interaction model, which is quite different from what Blink typically assumes on desktop or mobile platforms.
On the web platform side, we have enabled a number of features that make it possible to run more realistic content. WebAssembly now works in interpreted mode, which allows execution within the constraints of the platform. We have also enabled VP9 software decoding and verified hardware-accelerated decoding for H.264 and H.265. These improvements are essential for media playback scenarios and were necessary to support the demo content.
To support ongoing development, we also set up reference bots for tvOS builds and tests. This helps ensure that the port can be maintained over time and reduces the risk of regressions as upstream Chromium continues to evolve.
Demo on a real device
This demo shows playing a YouTube video in content_shell running on a real Apple TV device. The demo also showed that we can navigate the video using the remote controller, which highlights the progress we’ve made in adapting Blink to the tvOS interaction model. While simple, this demonstration is an important milestone because it proves that Blink can run real-world web content on actual hardware.
Current limitations
Despite this progress, several challenges remain. One of the most noticeable issues is build stability. The tvOS port has been broken frequently, mainly because both the iOS and tvOS ports are still experimental and not always considered in upstream changes. In particular, configurations such as the WebAssembly interpreter mode are not consistently handled by all changes, leading to breakage.
Testing is another area where limitations are evident. Since the port relies on a single-process model, running web tests is currently not supported, which makes it harder to validate correctness and compatibility. There are also platform-level gaps, such as missing accessibility support and the absence of certain UI components like file choosers and color pickers. As a result, some web pages do not behave as expected on tvOS.
Next steps
Looking ahead, our focus is on improving the robustness and maintainability of the port. This includes stabilizing the build, expanding test coverage, and investigating ways to run web tests in a single-process environment. We also plan to keep the port up to date with the latest tvOS SDK and continue maintaining it in upstream Chromium.
Closing thoughts
Over the past year, Blink for tvOS has evolved from an initial experiment into a working upstream port that can run on real devices. While it is still early and many challenges remain, the progress so far shows that it is possible to bring Blink-based web capabilities to a constrained platform like tvOS. We will continue exploring this space and see how far this effort can go.
Finally, I would like to thank all the contributors, reviewers, and sponsors who made this work possible.
Update on what happened in WebKit in the week from May 4 to May 11.
This week we have a bag of exciting updates, such as fixes to crashes, better
YouTube playback, a handful of advancements to WebXR, and the development
releases of WebKitGTK and WPE WebKit 2.53.2.
Cross-Port 🐱
If the filesystem runs out of space while the NetworkProcess is writing into its network cache, the process will crash with SIGBUS. This would surface to users as the "Internal error fired from WebLoaderStrategy.cpp(559) : internallyFailedLoadTimerFired" error, and would be handled by re-spawning another NetworkProcess that would similarly fail.
This was addressed by using fallocate, if available, to reserve the required size. If fallocate fails to reserve, the NetworkProcess will skip caching, avoiding the crash. If fallocate is not available, the existing behaviour is preserved.
Networking 📶
Networking support, including the libsoup HTTP library.
libsoup now supports the zstd compression encoding.
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
getUserMedia() and getDisplayMedia() support should work better thanks to a couple PipeWire related fixes.
Playback of some YouTube videos (usually at low framerate) has been fixed. Eventually a better solution will involve supporting edit lists in the GStreamer MSE backend.
Graphics 🖼️
A crash when accessing the diagnostics webkit://gpu page was fixed, making sure we handle the case where libGL.so.1 or libOpenGL.so.0 are missing.
Fixed missing glyph before ZWJ/ZWNJ if no font is found for the cluster.
The second unstable releases for the current development cycle have been published: WebKitGTK 2.53.2 and WPE WebKit 2.53.2. Development releases are intended is to gather early feedback on upcoming changes, and as such issue reports are welcome in Bugzilla.
At BlinkOn 20 in 2025, I gave a short lightning talk about an experimental project called Blink for Apple tvOS. Although the presentation took place about a year ago, I wanted to take some time to provide more context on why we started this work, what challenges we encountered along the way, and where the project stands today in this blog again.
Motivation
Apple TV runs tvOS, which is based on iOS, but it differs in some important ways. One of the most notable differences is that tvOS does not provide a WebKit WebView for third-party applications. This limitation has significant implications, as applications that need web functionality must embed their own web engine.
A well-known example is the YouTube app on Apple TV, which uses a custom web engine called Cobalt. This engine is based on an outdated Chromium fork, and maintaining such a fork becomes increasingly difficult over time, especially as the web platform continues to evolve.
At the same time, the Chromium community has been exploring Blink-based implementations on Apple platforms, including the experimental Blink for iOS project. As that work progressed, it naturally led to a new question: whether Blink could also be brought to tvOS. Beyond that, we also started wondering if it would be possible to eventually upstream Blink support for tvOS. These questions became the starting point of this project.
Challenges
Although tvOS is derived from iOS, porting Blink to this platform turned out to be far from straightforward. One of the biggest challenges comes from the lack of support for the multi-process architecture that Chromium relies on. Several low-level system APIs, such as fork(), mach_msg(), and posix_spawn_*(), are not available on tvOS, which makes it impossible to adopt the standard process model.
Another major limitation is the absence of BrowserEngineKit, which the Blink port on iOS uses for process management and integration. Without this framework, alternative approaches are required to make the system work on tvOS.
In addition, tvOS does not allow JIT compilation due to platform restrictions, which directly affects the execution model of V8. This requires running JavaScript in a more restricted mode compared to other platforms.
The input model also differs significantly. Apple TV primarily relies on a remote control, which leads to a focus-based navigation model rather than pointer-based interaction. This affects how web content needs to be handled and navigated.
Given all these constraints, it became clear that the goal of this project should not be to build a fully-featured browser. Instead, we focused on enabling Blink-based web capabilities on tvOS in a way that is both practical and maintainable.
Current progress
To get Blink running on tvOS, we made a number of changes across both the build system and the runtime. On the build side, we introduced tvOS-specific configurations, including a new toolchain, the IS_IOS_TVOS build flag in C++ and Objective-C code, and a target_platform = "tvos" setting in GN.
On the runtime side, the lack of multi-process support required us to enable a single-process mode. We also removed or disabled code paths that depend on BrowserEngineKit and ensured that unsupported low-level system APIs are not used in the tvOS build.
Several modifications were also necessary in core components. For example, JIT was disabled in V8, and build configurations were adjusted for third-party libraries such as ANGLE, V8, and Dawn to make them compatible with tvOS.
At the same time, we worked on integrating platform-specific features. This includes support for hardware-accelerated graphics, media codecs, and Crashpad, as well as improvements to input handling to better support remote-based interaction.
As a result of these efforts, content_shell is now able to run in our internal repository, and work toward upstreaming is currently in progress.
Demo
To demonstrate the current state of the project, we prepared a simple demo showing Blink running on tvOS. In this demo, a YouTube video is played inside content_shell on the tvOS simulator, which illustrates that Blink is capable of rendering and running real-world web content in this environment.
Next steps
There is still a significant amount of work ahead. In the short term, our focus is on making content_shell build and run in upstream Chromium, setting up a reference bot for tvOS builds, and passing relevant unit tests, browser tests, and web platform tests.
In other words, we are currently transitioning from a prototype that “works” to something that is stable, maintainable, and ready for upstream integration.
Closing thoughts
One of the most interesting aspects of this project is how different tvOS is, despite being closely related to iOS. Even relatively small platform restrictions can have large architectural implications when working with a complex system like Blink.
While tvOS is a constrained environment, that is precisely what makes it an interesting engineering challenge. We will continue exploring how far we can take this effort and whether Blink on tvOS can eventually become part of upstream Chromium.
Acknowledgements
This work would not have been possible without the support of many contributors, including Blink and Chromium reviewers, the Google YouTube team, and many collaborators in the community.
Quite some time ago I shared a script and methodology for performing a
cross-architecture debootstrap in a rootless
way. I had a short
note on producing an image bootable in QEMU, but it was fairly minimal. This
page provides a cookbook / quick reference on producing such images across
various Debian target architectures supported by QEMU. The goal is that the
starting point here "gets the basics right" for local experimentation, but of
course you are encouraged to evolve the recipe for your needs.
The basic process is to:
Build a root filesystem with rootless-debootstrap-wrapper.
Configure just enough networking, DNS, serial login, and SSH.
Create a 30 GiB ext4 filesystem image directly with mkfs.ext4.
Boot it with qemu-system-*, passing the Debian kernel and initrd directly.
We use Debian trixie for amd64, arm64, armhf, ppc64el, riscv64, and s390x.
We use sid for ppc64 big endian and loong64. I ran all of this on a current
Arch Linux install.
mkdir -p qemu-debian-images
cd qemu-debian-images
mkdir -p "$HOME/debcache"
Paste the following into your terminal, which will be called to do the common
guest-side configuration. The main thing that's slightly non-standard in this
setup are the systemd drop-in overrides which allow authorised SSH keys to be
specified by teh systemd credential mechanism. If that's not something you're
interested in doing, you can skip the parts touch /etc/systemd/system/ssh*
altogether.
This should not be exposed on any public network without further
configuration. You can ssh in to either the root user or user via ssh, using
password root or user respectively. The commands below expose ssh via a
unix domain socket. One potential gotcha: this unix domain socket must not
have any - in its name as that collides with the splitting done for the
hostfwd argument. The examples given below avoid this issue. The boot
commands pass net.ifnames=0, so the single QEMU network device is
consistently named eth0 and matched by the networkd config above (I found
this more reliable than ln -sf /dev/null /etc/udev/rules.d/80-net-setup-link.rules).
For simplicity we make use of mkfs.ext4's ability to populate the image from
a directory. Pleasingly, mkfs.xfs gained a similar ability in the xfsprogs
6.17.0 release in Oct 2025. If you have
a new enough version, and you prefer an XFS rootfs over ext4 you can tweak the
recipes below to do the following for the final image population step:
As noted above, you can log in with root/root or user/user. The launch
commands above run QEMU with -nographic causing your terminal to be
connected to the guest serial console. Ctrl-c alone won't kill the virtual
machine, so it's helpful to know:
Ctrl-a x exits QEMU immediately.
Ctrl-a c switches between the guest serial console and the QEMU monitor.
From the monitor, quit exits QEMU and system_powerdown asks the guest to
shut down cleanly.
Ctrl-a h prints QEMU's help for the other Ctrl-a shortcuts.
Once the guest is booted, you can connect via ssh to the Unix domain socket
that forwards to guest port 22. Assuming you're on a recent system with
systemd-ssh-proxy (and the ssh config file it adds) present, this can be
done with e.g.:
ssh root@unix/tmp/qemu_amd64.sock
Without systemd-ssh-proxy, you can specify ProxyCommand instead:
# For socat:
ssh -o "ProxyCommand=socat - UNIX-CONNECT:/tmp/qemu_amd64.sock" root@vm
# Or for OpenBSD netcat:
ssh -o "ProxyCommand=nc -U /tmp/qemu_amd64.sock" root@vm
If you'd rather use a TCP port, replace the -netdev part of the qemu launch
command with something like the following and connect to localhost:2222:
The systemd-provided config for use of systemd-ssh-proxy disables host
identity checks, which is what you typically want with this setup. If using
one of the ProxyCommand options above you may want to add -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null to your `ssh
invocation.
Alternative: SSH over vsock
It's possible to avoid QEMU user-mode networking and use ssh via AF_VSOCK.
This can even work without any additional image changes as
systemd-ssh-generator in the guest will generate an appropriate
socket-activated sshd service if vsock is present. On the host, you'll need to
pick a numeric address for the vsock ('guest CID') that isn't already in use on
the system, and change the qemu command line to add the appropriate vsock
device with that CID assigned. The vsock device used depends on the machine
being emulated - e.g. whether to attach on PCI or the virtio device bus.
For amd64, ppc64el, ppc64, and loong64, add:
-device vhost-vsock-pci,guest-cid=42
For arm64, armhf, and riscv64, add:
-device vhost-vsock-device,guest-cid=42
For s390x, use:
-device vhost-vsock-ccw,guest-cid=42
Assuming your host has systemd-ssh-proxy and its OpenSSH config installed,
you can connect with:
ssh root@vsock/42
Using an injected SSH key
Images set up using the recipes above allow a public key to be specified at
boot time using the systemd system credential mechanism. Just append the
following to the qemu launch command and you can ssh in using that key:
Web browsers do an astounding amount of stuff with language - and we're always trying to do more. Like most things that we get "for free" and don't give a lot of attention to, there is a lot more to it than you might realize.
Recently, I've been bouncing around looking at several browser language features. Today, our web browsers can listen to us and transcribe our words, they can speak to us, they can do spell checking, and grammar checking. At a surface level there is just a seeming "need to understand words", right? But what exactly that means is actually really variant!
Speech to Text... but more.
Today, your browser can talk to you via the Web Speech API. That's not new. Recently there was a W3C workshop on Voice Interaction. All of the presentations are available on the W3C's playlist. For some reason the sound on some of them seems pretty bad, and unfortunately many very good discusions aren't recorded. One presentation Solving Lead vs. Lead: Consistent Pronunciation for Web Content was very interesting to me. In my 2017 post Greetings, Professor Falken I talked about how the underlying speech system was able to gather a lot from context. For example, even back then, all of the browsers and OSes I could try got these "right" in that they were not naively read but rather read as the correct "forms".
1. Pi is about 3.14
2. We loaded the 4x4
3. Please meet me at 3.14pm EST
4. My birthday is 2/17/1974
Going on 10 years later, today's speech systems would get most "lead" (the heavy element) vs "lead" (being out in front) examples correct because of context. But, in the talk and later discussion, there are plenty of examples where you shouldn't really rely on that. For example, if we're trying to teach someone how something is said. That isn't really just about academics, instances abound.
In that same 2017 post I also mentioned that what the speech subsystems didn't get right was "Greetings, Professor Falken". They didn't pronounce it like the movie. I overcame that in the post by feeding it a misspelling, but this was sort of non-deterministic too, and solved by trial and error. Sarah (the presenter of the W3C talk) lays into a lot of examples like this - we discussed way more examples than I was initially considering where either there was no great context, or where no amount of context is actually likely to help. A lot of these cases are proper nouns or regional pronunciations. Montpelier, VT and Montpelier in the south of France are pronounced very differently. Barre, VT and Martin Barre the lead guitarist for Jethro Tull are pronounced very differently. These are somewhat famous examples. Ana can be pronounced several ways - which one is this? How do you pronounce the names of fictional characters? Or companies and products? And so on.
Sarah is from ETS, who also participated in an earlier "Spoken Presentation Task Force" which produced a proposal for Spoken HTML - and in theory Web Speech should support SSML too. So, that's the proposed solution for that kind of problem. Keep that in the back of your mind for now.
As you can imagine, this is all true in the reverse direction as well. That is, if you are transcribing speech there are sound-alike words and so on - which do I transcribe? “cache” or “cash”? Is it "Barre" or "Barry" or "Berry" Vermont? Do I write "4 by 4" or "4x4" or "Four by Four"? Again, today's models will do very well, generally - but you'll have problems with most of those same things, including especially all of those proper nouns.
At the end of the day all of the listening part is statistics based. The listening machine is this many % confident that it heard X, a little less confident that it heard Y and so on... Then it's sort of a lot like an LLM. So, given context it can do better. Contextual biasing is a simple, common way to improve the result: Just tell it a list of words you might be more likely to use and it'll bias toward them (optionally, provide a weight as to how much more likely it is to be this word, vs something that sounds similar). So, in our example above, if your page is a discussion forum about Vermont politics, it's probably going to hear what is pronounced like "berry" but we want it to write "Barre" and not "Barry" or "bury" or "berry" or anything else, even if it's just a single word without a larger context. Like a host asks "where was that?" and someone replies "Barre".
That functionality was recently added to the Web Speech API in Chrome.
More Different Than You Might Think...
Listening, and speaking both feel so related, but the approach to the two is actually very different. In one it's just a word and optionally a number, and in the other is more complex - you need specialized knowledge about SSML and IPA (International Phonetic Alphabet), some mapping and... in practice more. That's because while SSML seems very deterministic compared to an arbitrary number and statistics, in practice, results vary. In theory, providing the IPA to pronounce "tomato" both of the popular ways- /təˈmɑːtəʊ/ and /təˈmeɪtoʊ/ (think of the old song Let's Call the Whole Thing Off) should make them be pronounced as expected. However, sending this to different speech engines yields unpredictable results. There isn't a way to check the authoritativeness. If the engine doesn't support IPA, it may read contents of the SSML itself, if it exists. If you Give it a name like Saoirse Ronan - even with SSML and a very good engine that supports phonemes and IPA - it often still won't actually pronounce it properly unless it has a good Irish voice... And there aren't actually a lot of them.
Contextual biasing is clearly no help on the pronunciation side of things. But, flip it around and you might think that IPA would be a good input as to how to hear words too - but I've not really found anyone who even tries to do that.
And now for something completely different
As I hinted at the beginning, those are only two examples. We also have things like spell checking - that's the part that marks things as spelled incorrectly - or grammar checking. You can independently style these two cases with the CSS :spelling-error and :grammar-error pseudo-classes independently, as written about by my colleague Stephen Chenney who did the work at Igalia thanks to funding from Bloomberg.
Note that neither of these suggests words in any way. None of them deal with the concepts of autosuggest or autocorrect or autofill or hints or maybe soon even stuff to indicate and generate text rewrites in the future.
None of these are the same thing. Many of them also inevitably have this same general specialized domains problem. For example, if I am editing some Hitchhiker's Guide to the Galaxy wiki and it contains a quote of Vogon poetry:
Oh freddled gruntbuggly,
Thy micturations are to me, (with big yawning)
As plurdled gabbleblotchits,
On a lurgid bee,
That mordiously hath blurted out,
Its earted jurtles, grumbling
Into a rancid festering confectious organ squealer.
[drowned out by moaning and screaming]
None of those words are actually spelling errors in this context, and highlighting them as such entirely ruins the experience - there are so many false positives, you miss the real errors.
And almost all of these problems are also somehow still differently handled.
For example, spell check dictionaries are located at potentially several levels. Sometimes you have one in a browser, sometimes the browser is just integrated with the OS level one. Sometimes a browser has 1 per profile. In Android, virtual keyboards have their own dictionaries.
But what does that even mean, "dictionaries"?
Just as is in the cases of speech to text, or text to speech, it can mean something different. A lot of things use a thing called Hunspell which packs up language "dictionaries" that work for all languages and more efficiently can encode complexities like plural rules, autosuggestion help and all sorts of things. For example, here is the LibreOffice en_GB.dic. In this file you'll find simple words like ablaze but most words have some kind of 'affixes' and you'll find similar words in runs that look something like this
These connect to affix definitions in an parallel ".aff" file. This is full of entries like
SFX n e ations [^ckt]e
SFX n 0 ations [^e]r
SFX n e ations [iou]te
SFX n y ations py
SFX n ke cation ke
SFX n ke cation's ke
SFX n ke cations ke
SFX n y ication [^p]y
SFX n y ication's [^p]y
In other words... It's complicated, but covers a lot.
If you ever right clicked something and selected "learn word" or "add to dictionary" or something, you're doing the equivalent of adding ablaze in the ".dic" file - just a simple string. But, unlike Hunspell or other complex formats, it's simple enough that even an end user can do it.
Bloomberg is also sponsoring our work on a proposal called the SpellCheckCustomDictionary API. We've been working on an explainer. Realistically maybe we should call it SpellCheckExclusions to be clearer that all it really does is allow a site to provide a list of words to not match as :spelling-error. We also let you do that in groups so that any active spellchecking can just re-run once.
There was a lot of debate and thought about how much of this should be shared or centralized, but starting with a simple list that can be well defined in terms of standard exclusion seems like a nice first step. It does mean that you would need to potentially add both "Gandalf" and "Gandalf's" as valid, and "hobbit" and "hobbits" and "hobbit's" and "hobbits'". But at least this is simple and understandable, works in every language and widens the pool of developers who might do it. A nice trade-off here might be to allow some sense of regexp in this list - though, for practical purposes it should probably be a limited subset (() for grouping, | for alternation, ? for optional, plus maybe an :i sigil for case insensitivity). This would potentially help make it easier for some authors to express more with less and help shrink the memory initially required, while still not getting too specialized and fairly easy to make performant enough.
It would also be nice to follow this with a purely declarative solution.
I'm pleased that this went to Stage 1 in WHATWG this week and looking forward to figuring out how we move this forward.
Anyway, it's been really interesting and fun to dig into all of this and it's always eye-opening to look behind another curtain... I'm looking forward to continuing these conversations and ultimately getting something useful into all of the browsers! Thanks again to Bloomberg Tech for the sponsorship!
Update on what happened in WebKit in the week from April 8 to April 28.
After a short hiatus, we return with a galore of releases, more Web Platform improvements,
tricky tweaks to thread scheduling, new niceties in the Web Inspector, and new build
options to take advantage of compiler optimizations.
Cross-Port 🐱
Delivered a number of changes that have strengthened WPE WebKit and WebKitGTK's behaviour around real-time thread promotion and demotion:
This means WebKit now has time to gracefully handle SIGXCPU, and will do it in an async-signal-safemanner.
Additionally, the NetworkProcess' Cache Storage thread is now defined as QOS::UserInitiated on Linux, which no longer maps to real-time priority. Its earlier mapping to real-time was previously reported as a NetworkProcess crash in the logs (it was in practice a kernel-delivered SIGKILL, but WebKit doesn't make any distinction while logging). After limits were adjusted, this thread was successfully demoted, and now that the mapping has changed, this is no longer promoted to real-time to begin with.
Finally, logging around portal-related failures has been updated to reduce noise.
Implemented the connectedMoveCallback() for custom elements to react to moveBefore().
Implemented the scaffolding for the moveBefore() DOM function. This is the first step towards implementing the full feature and is currently behind a runtime feature flag.
The Web Inspector now highlights the layout root element by hovering over a Layout event in the “Layout & Rendering” timeline view and reveals it in the element tree by clicking a little “go to” arrow button.
Releases 📦️
WebKitGTK 2.52.2 and WPE WebKit 2.52.2 have been released, which include a number of fixes. In particular, building for some less tested configurations should now be possible, and the WPE port includes fixes for input event handling in the Qt API bindings.
The releases were quickly followed by WebKitGTK 2.52.3 and WPE WebKit 2.52.3, with further fixes including an important patch for crashes in JavaScriptCore on architectures other than x86_64, support for the scrollbar-color CSS property, and a fix for rendering certain emoji glyphs. Additionally, the WPE port also gained a new setting to disable overlay scroll bars and use always-visible ones, fixed focus handling for touch input in the built-in Wayland platform implementation, and a build fix for the Qt one.
In addition to maintenance for the stable branch, the first unstable releases for the current development cycle are also available: WebKitGTK 2.53.1 and WPE WebKit 2.53.1. These are the first published versions that remove the option to use Cairo for 2D rendering—only Skia will be supported going forward. On the additions front, there are graphics subsystem improvements, a few API additions, and initial support in the CMake build system for builds using Profile-Guided Optimization (PGO, needs Clang for now). The goal of development releases is to gather early feedback on upcoming changes, and issue reports are welcome in Bugzilla.
Infrastructure 🏗️
PGO (Profile-Guided Optimization) builds with Clang are now supported by the CMake build system.
Over the years, I’ve created an experiment or two that drew stuff to a <canvas> element: a wave function collapse experiment here, a crystallizing palette there. After a while, I found a way to wire up a button so that clicking it would save the canvas’s contents to my computer as a PNG file. Pretty cool, I thought. Can I do the same thing with HTML+CSS structures?
First I generated it on a canvas, then I clicked a button to save it.
Turns out, no. I could use, and often have used, Firefox’s “Screenshot node” menu entry in the web inspector, or the :screenshot command in Firefox’s console, but not do it with an in-page button. Because HTML nodes don’t go in <canvas>, you see, let alone styled and scripted ones.
Or they didn’t, until just recently, when Chrome shipped a flag-gated preview of the HTML-in-canvas API. How it works is, you add a layoutsubtree attribute to a <canvas> element, and then you can put whatever HTML you want in there, with whatever CSS and JS you would normally apply to it, add a couple of magic JScantations, and what the browser would normally have painted to the page is painted to the canvas, at whatever speed the browser can manage (usually 60 frames per second or more, because web browsers are high-end first-person scrollers).
If you want to try all this out for yourself, I commend you to Amit Sheen’s “The Web Is Fun Again” over at the Frontend Masters blog, where he details how to get yourself set up for the wackiness this makes possible, and then shows some experiments. Water ripples over your pages, lens distortions that follow the mouse pointer, chromatic aberrations!
Which, I admit, all sound really off-putting to the “I just want to use the web” folks among us. What possible utility is there in having an input form that, say, makes ripples spread out from every character you type? Or having dropdown menus fall to the bottom of the page, but still actually work? Probably not a lot, unless you’re an expensive design studio working on a brag page.
But remember, this is how any new graphic advancement goes: we, by which I mean the collective web industry, start by doing really outré and eye-catching stuff that we later have cause to regret. Remember parallax scrolling effects? The early days of CSS animation? Drop shadows? There will be an initial period of excess, and then it will all settle down.
I’ve already skipped straight to the settle down part, though.
See, when I asked myself if I could render HTML+CSS on a <canvas> and then save the image to my computer, it wasn’t just me doing that “push at the limits of web features” thing I do sometimes. I had an actual, practical use case in mind: I wanted to save social media banners and thumbnails from a browser-based tool I built for my work at Igalia, just by clicking or otherwise triggering a button.
If you’re subscribed to our YouTube channel, you’ve seen these thumbnails; ditto if you’re following us on Mastodon or Bluesky. To produce those, I have an in-browser thing I built out of custom elements. It’s where the super-slider pattern developed (though they have a different name in the tool). I’m not going to link to the tool because it’s on our intranet and very few of you have a login, so here’s a screenshot of it in all its dweeb-designed semi-glory.
The banner maker, with a recent thumbnail already loaded in.
The text bits in the banner are all contenteditable HTML elements, and the various themes are managed with various blocks of CSS. (And yeah, those range inputs are all “super sliders”.) The point of all this being, I built it so that anyone at work could use it to make
banners whenever they needed, without having to wait on me to do so.
What I’ve always wanted, in order to make things easy for anyone who isn’t me, is a “click this button to save the banner as an image” feature. Anyone at Igalia could easily learn (if they didn’t already know) the web-inspector-or-console stuff I was using, of course, but it just felt so janky. A touch embarrassing, if I’m being honest.
Well, now I have what I wanted. In any browser that supports HTML-in-canvas, there is a button labeled “Download banner image”. Right now, that’s recent Chrome with the proper developer flag enabled. For all other browsers, there’s no button, and you just use the same web inspector screenshot tricks we’ve always relied on.
Making this happen wasn’t as easy as maybe that sounded, though. I hit a couple of snags along the way, one of which was quite frustrating. Those are what I actually brought you here to talk about.
The first snag was that I had to get the thumbnail preview into a <canvas> element without blowing the call stack. To explain that, let me show you a rough skeleton of the tool’s markup.
As you can read, it’s basically all custom elements, each with their own connectedCallback() function to do whatever scripting magic needs to be done when the browser first encounters them. To wrap that last element, the <thumb-preview>, inside a <canvas>, I needed to create a new canvas element, shift the preview element into the new canvas, and then insert the preview-bearing canvas, ending up with this structure.
Thus, when the <thumb-preview> was loaded in, I had its connectedCallback() run a check to see if HTML-in-canvas is supported. In situations where it is supported, I did what was needed to get to the above result.
At which point, since the <thumb-preview> is a custom element that was being placed into the DOM, it fired its connectedCallback(), thus starting the process again, creating a canvas and inserting the <thumb-preview> into the new canvas, which started the process again, recursing toward infinity. Within milliseconds, the call stack was exceeded.
So… that wasn’t going to work.
I thought for a moment that I could avoid this by setting a flag variable to true and then checking for its existence in order to skip the whole canvas-creation-preview-insertion part, but I couldn’t figure out how to make that actually work. Then I thought maybe I could sidestep the whole imbroglio using connectedMoveCallback(), but this wasn’t a move, it was a (re-)creation.
That callback was the route to fixing this problem, though. You see, there is a way to move elements from one part of the DOM to another: Element.moveBefore(). There’s no moveAfter() or moveInto(), sadly, just “move this node to the spot right before some other node”.
Here’s how I made use of that feature:
let canvas = document.createElement('canvas');
canvas.setAttribute('layoutsubtree','');
canvas.setAttribute('width','1280');
canvas.setAttribute('height','720');
this.closest('section').appendChild(canvas);
let beacon = document.createElement('span');
canvas.appendChild(beacon);
canvas.moveBefore(this,beacon);
beacon.remove();
Yep. I created a canvas, stuck the canvas into the closest ancestor section, created a span, stuck the span into the canvas, moved the preview element to right before the span, and then deleted the span. (There may well be a better way to do this, one that my DuckDucking failed to turn up. If so, please comment below!)
Oh, and here’s what gets executed when the preview is moved, instead of append-created:
connectedMoveCallback() {
return;
}
Heckuva way to run a railroad.
At that point, I had the canvas where I wanted it and the preview where I wanted it, and the call stack remained un-blown. Huzzah! I then recited the magic JScantations to make the canvas actually render its subtree (see the “Web is Fun Again” article I linked earlier for details on this), and hey presto, DOM was being rendered into a canvas! Then, when I clicked the button, the canvas was rendered as a PNG and my browser downloaded that PNG! I had what I wanted!
Almost.
Because the second snag, you see, is that canvases have an explicit size. Are in effect required to do so, because otherwise they default to zero pixels tall and wide. So if you want to see anything, you need to give them some dimensions. I did that, as the code before showed, making the canvas 1280×720 (YouTube’s recommended thumbnail size) through setAttribute() methods.
The problem is, the default scale factor on the thumbnail preview is 0.75, which translates to 960×540. Thus, when I clicked the image capture button, my browser downloaded a 1280×720 image with the thumbnail in the top left, and transparency below and to its right.
The previously-seen banner, which was rendered at 0.75 scale in an un-resized canvas, as shown in the macOS image editor Acorn.
“Just resize the canvas, ya dork!” you might say. I certainly did (say that, I mean). But if I set it to 960 wide and 540 tall, then when the scale was increased to 1, I got a 1280×720 DOM node cropped to its top left 960×540. I needed to dynamically resize the canvas element to have its size match the size of the thumb-preview.
And this is where I ran headfirst into several brick walls, because orcing a canvas element to resize in all the situations you want it to, including when it’s spawned, is not nearly as easy as you’d think. It wasn’t for me, anyway. I bulled my way through to a solution, eventually, painfully, but I got there.
(As I write this, I’m wondering if I should have also created a <div>, appended the canvas to that, and then used CSS to change the div’s size while the canvas was set to have 100% height and width. Or maybe have the DOM subtree pinned to 1280×720 and use CSS scale to change the canvas size visually. Or perhaps some kind of resizeObserver shenanigans. Or probably just pass some parameters to the HTML-in-canvas drawElementImage method. Hmmm.)
Regardless of whether I overlooked a less frustrating way do what I wanted, this does still point to a fundamental tension in the HTML-in-canvas approach: sizing.
Canvases do not, as a rule, grow or shrink to fit their contents. DOM elements, as a rule, very much do, unless you force them not to. HTML-in-canvas is taking a very fluid, flexible, mostly unbounded layout paradigm and rasterizing it, or at least some of it, into a very bounded window of a given size. Sixty times (or more) every second, the browser is taking a screenshot the size of the canvas’s content box and pasting said screenshot into that content box. You can do fun stuff to it along the way, with filters or shaders or canvas draw calls or whatever you can code up, so that each one of those screenshots gets jazzed up in some fashion, but at base, it’s still fundamentally screenshot, paste, screenshot, paste, over and over.
For use cases like mine, this isn’t really a big problem. I am, in the end, trying to get a screenshot of a static part of the page. HTML-in-canvas is very good for that. It could completely revolutionize the browser-based slideshow genre. The Reveal.js plugin landscape alone could be a sight to behold.
But in the general cases — the kinds of things we mostly do most every day — I don’t think this is likely to catch on. We might develop some patterns to make it easier, some interesting hacks to overcome the mismatch, but I don’t think that will significantly move the needle. On the other hand, if canvases can be made as flexible and content-wrapping as a bog-standard <div>, then I would expect to see a lot more usage.
Although if that can be done, then we wouldn’t really need to stay chained to HTML-in-canvas. Instead, we could define a syntax to mark standard HTML elements as more visually manipulable, via an HTML attribute or CSS property or DOM method or all three.
We’ve gotten close to that before: CSS Houdini and Microsoft’s original filter property, to pick two examples. We could try again. Maybe the HTML-in-canvas period is how we figure out what that simpler syntax should look like, by figuring out what it should make possible, and what it should make easy.
I’d be okay with that. How about you?
Many thanks to my colleagues Brian Kardell and Stephen Chenney for their early review and feedback on this post.
TL;DR: Some times, usually when you are not using the default build flags you can easily fall in the situation were you got fails to link the WebKit libs with undefined reference errors caused by missing #include directives in .cpp files. This post describes how I manage the situation to identify the missing headers in […]
I've been thinking a lot recently about the W3C's Priority of Constituencies...
You've probably heard it cited before, the Priority of Constituencies. And what you've probably heard is
User needs come before the needs of web page authors, which come before the needs of user agent implementors, which come before the needs of specification writers, which come before theoretical purity.
Everyone loves this principle. It's almost poetic right? I often hear it cited as if it were part of a founding W3C document from 1995, so it might be surprising to learn that it wasn’t.
Back in 2004 there was a kind of a schism in the W3C that led to the creation of WHATWG and the effort to create "HTML5". In many ways it was a bit of a left turn from what was happening in the W3C at the time. In 2007 there was a kind of admission that maybe the WHATWG was on to something, and a rechartering of HTML and, (inspired by a requirement suggested by David Baron), a group of people (Maciej Stachowiak, Anne van Kesteren, Marcos Caceres, Henri Sivonen and Ian Hickson) got together and drafted some Proposed Design Principles - March 2007... The original text is available from the wayback machine.
The main statement was added to the W3C TAG's Design Principles in 2020 with minor tweaks and then later in 2020, Alice Boxhall (currently at Igalia, but at the time with Google) added some additional clarifications (incorporating David's thoughts) to be more or less what it reads today.
I've been thinking a lot about these additions because I think they're important, but somehow not talked about as much. They're less "poetic", but nevertheless actually critically pragmatic:
Like all principles, this isn’t absolute. Ease of authoring affects how content reaches users. User agents have to prioritize finite engineering resources, which affects how features reach authors. Specification writers also have finite resources, and theoretical concerns reflect underlying needs of all of these groups.
I really appreciate the nuance these bits add because it really isn't just about some statement - it needs to be grounded in realities. It really is about considering tradeoffs and looking for how to optimize the application of this principle. At some level, for example, a decent feature that vendors agree they can deliver is of considerably more practical value to end users than a "better" one that we cannot.
The edits also add the most simple version, a one-liner:
If a trade-off needs to be made, always put user needs above all.
User-first: We prioritize the needs of users over other constituencies, including over those of W3C Members.
But, again, it must be acknowledged that this is a principle and not an absolute mechanism. It bumps up against reality in several ways without additional nuance. To take one example: Users, and authors benefit from good MathML support. I've argued before that the ability to share native mathematical text is societally important. You could say that its weight in a simplified Priority of Consituencies should be pretty high. But it's also pretty complex, and expensive and harder to appreciate. In practice, browsers don't prioritize it. In fact, they don't even belong to the Working Group. Nearly all of the work on MathML has been the work of volunteers or outside sponsorships. The recent work on MathML-Core has been successful largely because it has taken a more pragmatic approach wrestling with these sorts of optimizations: The MathML (or insert whatever feature you like) we can get is considerably better than the one that we cannot.
Lately I’ve been thinking the web’s constituencies are broader than the familiar list suggests. I’m not arguing we should rewrite the principle, but I do think there’s value in drawing a map of the parts of the web ecosystem, asking who else is affected, who else is missing, and how our mental models shape the choices we make. I feel like, if the Priority of Constituencies has taught us anything, it’s that the way we understand the players and frame the statement can certainly have a positive influence on the way we approach it.
If you’ve been working with the Yocto Project for a while, you already know it’s the de facto standard for building custom embedded Linux distributions. What you might not know is how much the tooling around it has improved.
Many teams adopted Yocto years ago and have kept roughly the same workflows ever since, copying setup scripts between projects, letting each developer figure out how to clone layers, and building releases manually on dedicated machines. These were the common patterns at the time, but by now they are just unnecessary friction.
The Yocto community and surrounding ecosystem have introduced tools and practices that significantly improve reproducibility, onboarding, and CI integration. But lack of comprehensive documentation for how to integrate these improvements has likely kept some people from adopting them. This post aims to cover the most important ones and close that gap.
Up until very recently, the Yocto documentation and tutorials encouraged developers to work with local files and gave little guidance on project structure. This nudged teams toward a set of common but costly habits: bootstrapping new projects by copying scripts from existing ones, leaving each developer to figure out layer setup on their own, and relying on specific machines for production builds. The result was projects that were fragile to onboard, hard to reproduce, and difficult to scale.
The most mature and tested solution to the problem today is kas. Kas is an open-source setup and automation tool to better manage Yocto layers. It simplifies the process of configuring a Yocto build environment into a single, declarative configuration that covers all of the issues mentioned before.
Defining your layers, repositories, revisions, and build settings in one place makes it straightforward to spin up new projects and onboard new team members: a fresh clone and a single command is all it takes to get a working build environment. Kas also provides container integration and CI/CD tooling out of the box, so the same environment that runs on a developer’s laptop runs identically in your CI pipeline. And because everything is expressed in YAML, project definitions can be versioned, diffed, and collaborated on like any other source file.
Here’s what a complete project definition looks like in practice:
repos: meta-moonforge: url: https://github.com/moonforgelinux/meta-moonforge.git commit: 628d710b7e076be1daa2376065ea12bb8eeded3a branch: main
distro: moonforge machine: raspberrypi5
The above example is enough to build a working image of Moonforge Linux for the Raspberry Pi 5. If you are curious about Moonforge, check out this tutorial for how to create your own distribution.
An official alternative to kas, called bitbake-setup, has recently been released by the maintainers of the Yocto project. Although still not as feature rich as kas, being part of BitBake makes bitbake-setup worth exploring and considering. A recent comparison from Richard Weinberger clarifies the similarities and differences.
Using containerized build environments is now common practice across Desktop Operating Systems. Containers enable members of a team to use the same environment regardless of what they are running on their development machines.
However, in the world of Yocto, many teams still follow the old practice of installing packages locally and then struggling to be able to reproduce the same conditions when building on a different machine. Nowadays, the best approach is to use a container that includes all the needed build dependencies at the desired version.
Kas integrates naturally with containers by using kas-container:
This containerized approach fits perfectly for CI workflows as well, so the conditions are always the same regardless of the machine or the stage of development.
The manual way of installing dependencies has meant that many teams have stayed away from CI/CD when using Yocto, building releases manually on developer machines. This tends to hold teams back, as errors are discovered too late and then problems might be hard to reproduce and solve.
Running automated pipelines like GitHub Actions, GitLab CI, or even Jenkins with the same containers as those used locally by developers ensures consistency and reduces human error.
Once these pipelines are enabled, remote computing resources and processes can be shared across multiple projects within the organization, and made available via reusable GitHub actions. As can be seen in this example:
The above example shows how Moonforge’s GitHub actions can be reused to build and publish OS images. These actions are available to all Moonforge derivative projects. Check this tutorial for how to reuse these actions with your own distribution.
The OpenEmbedded build system allows you to isolate different types of customizations into multiple layers. Each layers can provide a specific solution that is reusable and extensible. In general, layers can:
Provide recipes for new software.
Modify recipes from existing layers.
Provide new configuration files for machines and distributions.
What layers can’t do:
Modify existing distribution or machine configurations.
Manage dependencies on external repositories and layers.
Set sensible defaults to the local configuration.
All of these limitations can be overcome by a sensible combination of layers and kas fragments. Simply put, fragments are YAML files that can be reused by other kas files.
Kas support for include directives can help structure these fragments in reusable blocks. These fragments can also be pulled from remote repositories. With this, derivative projects can reuse existing combinations of layers and fragments to build their own distributions, reducing duplication, manual steps, increasing reproducibility and having a clear upstream and downstream separation.
The above example shows how external layers can be made available to other fragments, keeping them pinned to a specific upstream release to ensure reproducibility.
The above example shows how having separate fragments for each layer can address the above limitations, like managing dependencies on external layers, setting sensible defaults to the local configuration and more.
Yocto remains the de facto standard for embedded Linux customization, but teams have to catch up with evolving workflows. Modern tooling and processes makes Yocto more reproducible, easier to use, maintain and scale.
As a last recap, remember to:
Use kas for build configuration.
Use containers for build environments.
Automate builds in CI/CD.
Keep layers modular and provide reusable fragments.
After months of development and testing in Chromium, Container Timing is ready for real-world testing. We will run an Origin Trial from Chromium 148 to 153. You can register for the trial.
Until now, developers have had to manually enable the ContainerTiming feature flag in Chromium to test the new API. With the Origin Trial, early adopters can enable the API in production for a subset of their users by including the trial token. More information on how to use origin trial tokens.
Why is this important? We have been internally testing and evolving the API, but now we need feedback from real-world users. The Origin Trial will allow web developers to use the new API in production and experiment with it.
Next week, April 20th and 21st, the Chromium community will gather for BlinkOn 21. I’ll be giving a lightning talk summarizing the updates over the last year.
I will keep a close eye on the BlinkOn Slack channels during the event, so feel free to reach out to discuss the roadmap, implementation details, or any API feedback.
The Origin Trial is a key step toward finalizing the specification. Real-world feedback from the trial itself and from BlinkOn 21 discussions will feed into the standards working group discussions, and we expect the specification to evolve from there.
If you build with Container Timing during the trial, please share what you find: what works, what does not, and what is missing. That input will shape the final API.
You can also test locally by enabling the ContainerTiming feature flag in Chromium, while you wait for your Origin Trial registration to be approved.
GStreamer is an open-source multimedia framework started in 1999. It lets you build pipelines of interconnected elements to stream, encode, decode, and manipulate media. The core idea is simple: a source element produces data, passes it through one or more transform elements, and delivers it to a sink. For example, here is a pipeline that decodes an MP3 audio file:
filesrc --> mp3dec --> audiosink
For more than 20 years, GStreamer has relied on its in-house toolbox to demonstrate the power
of its pipelines. As this toolbox is used in thousands of projects and serves as a reference
implementation, modifications and enhancements are deliberately kept minimal to maintain stability.
gst-pop was created to go beyond these limitations.
Accessible over the network, via CLI arguments, or through D-Bus, gst-pop aims to provide
a multi-pipeline-capable command-line tool.
With a simple invocation of gst-pop (or its alias gst-popd), you can run a daemon that accepts
multiple pipelines simultaneously, accessible through D-Bus or WebSocket via the pipeline
ID. You’ll be able to control, query, and get information about each pipeline — all of that
over a remote network, secured with API key authentication and origin validation to prevent unauthorized access.
As demonstrated in the blog post related to GstPipelineStudio, it will be possible to connect to a remote pipeline or launch new pipelines through the GStreamer GUI. If a GUI is not available
on the platform, it will soon be possible to use a web interface to control GStreamer, offering
everything GStreamer can provide and more, limited only by your imagination.
gst-pop (or its alias gst-pop-inspect) is also capable of listing the elements on a local or remote host, inspecting their capabilities, and providing a remote way to interact with your GStreamer installation.
It can also provide information on a media file using GStreamer’s discovery interface using gst-pop-discovery, offering an easy and remote-capable media discovery system for your setup.
And of course, it can serve as an alternative to the gst-play tool, with gst-pop-play, allowing you to instantiate as many playback sessions as you need, with the ability to use any sink you want.
The possibilities are vast: provide multimedia services such as transcoding, media analysis, or remote playback to your setup using the power of a remote machine, all controllable from your terminal or a GUI such as GstPipelineStudio.
The tool is written in Rust for memory safety and reliability and provides client libraries in both Rust and C, offering all the flexibility needed for your existing applications. It is available on Linux (deb, rpm or docker), MacOS, and Windows, see the release page.
Update on what happened in WebKit in the week from March 31 to April 7.
Support for iOS dialog light dismiss, a new API to obtain page icons,
WebKit nightly builds for Epiphany Canary produced by
GNOME GitLab, and more conservative checks for MPEG-4 Audio object types
are all part of this week's edition of the WebKit periodical.
Cross-Port 🐱
A new API to obtain page icons (a.k.a. “favicons”) has been added to the GTK port. The new functionality reuses the recently added WebKitImage class and provides access to multiple page icons at once through the added WebKitImageList type, allowing applications to better choose an icon that suits their needs. Changes to the WebKitWebView.page-icons property are guaranteed to be done once per page load, when all icon images are available to be used. This new API has been also enabled for the WPE port, and the plan is to deprecate the old page favicon functionality going forward.
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
canPlayType() is now more conservative regarding MPEG-4 Audio object types. This primarily affects AAC extensions: In the past, as long as there was an AAC decoder installed, WebKit was accepting any codec string that started with mp4a. Now it only accepts codec strings that correspond to object types that have widespread support. This can prevent accidental playback of newer formats like xHE-AAC, which many decoders don't yet support — for example, as of writing, FFmpeg support for xHE-AAC is only very recent and still incomplete.
The GStreamer WebRTC backend now rejects SDP including rtpmap attributes in the disallowed range of 64-95 payload types. Compliance with RFC 7587 was also improved.
Infrastructure 🏗️
The WebKitGTK nightly builds for Epiphany Canary are now handled entirely by the GNOME GitLab infrastructure, many thanks to them! The previous approach was not optimal, producing release builds without debug symbols. With the new builds, it is now easier to get crash stack traces including more information.
GStreamer is an open-source multimedia framework started in 1999. It lets you build pipelines of interconnected elements to stream, encode, decode, and manipulate media. The core idea is simple: a source element produces data, passes it through one or more transform elements, and delivers it to a sink. For example, here is a pipeline that decodes an MP3 audio file:
filesrc --> mp3dec --> audiosink
GStreamer is written in C, with a growing ecosystem of plugins in Rust and bindings for languages such as Python and C++. It ships with many command-line tools to build and test pipelines, but validating ideas still requires writing C/Rust/Python code or using the command line. That’s where GstPipelineStudio comes in — providing a visual interface to help newcomers discover and adopt GStreamer, and skilled developers debug their pipelines.
The GstPipelineStudio project started in 2021 with the idea to provide the same environment that brought me to multimedia: GraphEdit on Windows with DirectShow. Indeed, DirectShow and GStreamer share the same idea of plugins sharing data. As I started to implement a DVB decoder with DirectShow, the graphical interface made it easier to validate which filters to use. But DirectShow only works natively on Windows, unlike GStreamer which can run everywhere — Linux, macOS, Windows, iOS, Android, and even low-power devices such as a Raspberry Pi.
GstPipelineStudio aims to work on all these platforms, easing GStreamer adoption where its use was not always obvious, such as on Windows.
GStreamer is based on GLib, a cross-platform toolkit that abstracts system calls and provides a common base layer. For the GUI, since Rust was offering very good bindings, GTK was the natural choice to achieve cross-platform support.
There was an attempt to create a GUI using Qt, named pipeviz, which has been a great inspiration for GPS, but the Qt Rust bindings were not mature enough, unlike those for GTK.
The first official release of GPS was 0.3.4, and you can read its official blog post published in 2023. Since then, we have been devoted to providing new features
to bring GPS to another level.
A first revision, GPS 0.4.0, came out before Christmas 2024 with a refreshed interface — including zoom on the graph
and contextual menus on any element or pad of the pipeline. The versions of GStreamer and GTK have also been updated to get the latest plugins and features from both frameworks.
A new icon has also been introduced to let GPS dive into another dimension.
0.5.1 is here, and it brings a game changer: the dot file reader.
Previously, it was possible to open a command-line pipeline or save/open pipelines with an XML-based format, but now you can also open the generated dot files, the native format in GStreamer, to display a pipeline graphically. This is still a beta version as it can only display
high-level pipelines such as those described with the command line. Nevertheless this is a great improvement and allows users to see their pipeline and manipulate it.
Here is the list of other improvements you’ll find in this release:
Open Dot Folder menu entry for loading dot files from the common GStreamer folder
Remote pipeline introspection using the GStreamer tracers
App ID renamed to dev.mooday.GstPipelineStudio
Improved look and feel of the interface
Auto-connect on node click (node-link-request)
File selector button for location property
Logger copy to clipboard with multi-selection support
The remote pipeline introspection is a new way to connect to the WebSocket tracer available in GStreamer, pipeline-snapshot.
In addition to dot file loader, it allows you to visualize a pipeline directly in GPS from an external process running with the tracer.
As you may know, GStreamer pipelines can be very complex, so one dream was to be able to visualize them live. There is already a mini tool in GStreamer named gst-dots-viewer which creates a web server to display pipelines in a browser from the $XDG_CACHE_DIR folder, see the blog post from Thibault about it.
Now with GPS, you can directly create a WebSocket server and let the tracer connect to it and provide available dot files to be displayed.
For example, to visualize a running pipeline in GPS:
In GPS: Menu → Remote Pipeline → Listen…
Enter the WebSocket address (e.g., ws://localhost:8080)
Run your GStreamer pipeline with the pipeline-snapshot tracer:
The pipeline graph will appear in GPS once the tracer connects.
These dot files are converted to GPS pipelines, making it possible to modify them. That’s a first step for real interaction with GStreamer pipelines — and there are more features coming in the pipeline.
In parallel, a new tool named GstPrinceOfParser (gst-pop) has also been implemented. This tool allows remote control of all pipelines instantiated locally or over the network.
It is a multi-pipeline daemon accessible through WebSocket or D-Bus, aiming to centralize all GStreamer options in one tool for launch, inspection, and discovery. GstPipelineStudio will be able to control this daemon, making gst-pop the backbone of the GStreamer GUI. A blog post will come soon, stay tuned…
A new tracer is under development: a WebSocket server that will allow you to inspect and interact with the current pipeline — modify the play state (pause, seek), fetch the logs, and of course see the current dot representation, all from the GstPipelineStudio interface.
In addition, more features are on the way: a new look and feel based on libadwaita on Linux/macOS/Windows, better localization, an auto-plug feature, seek and step-by-step playback, and bug fixes on demand.
We hope you’ll enjoy this new version of the tool and please feel free to propose
new features with an RFC here or merge requests here.
Stay tuned for the next GStreamer Spring hackfest 2026 coming soon (end of May) where new features and deeper interaction with GStreamer pipelines will be discussed.
As usual, if you would like to learn more about GstPipelineStudio, GStreamer, or any other open multimedia framework, please contact us!
Following up on my previous post, I would like to share an update on the progress of the Extension migration work that has been underway over the past few months.
To briefly recap the motivation behind this effort: Igalia’s long-term goal is to enable embedders to use the Extension system without depending on the //chrome layer. In other words, we want to make it possible to support Extension functionality with minimal implementation effort using only //content + //extensions.
Currently, some parts of the Extension system still rely on the //chrome layer. Our objective is to remove those dependencies so that embedders can integrate Extension capabilities without needing to include the entire //chrome layer.
As a short-term milestone, we focused on migrating the Extension installation implementation from //chrome to //extensions. This phase of the work has now been completed, which is why I’m sharing this progress update.
Extension Installation Formats
Chromium supports several formats for installing Extensions. The most common ones are zip, unpacked and crx.
Each format serves a different purpose:
zip – commonly used for internal distribution or packaged deployment
unpacked – primarily used during development and debugging
crx – the standard packaged format used by the Chrome Web Store
During this migration effort, the code responsible for supporting all three installation formats has been successfully moved to the //extensions layer.
As a result, the Extension installation pipeline is now significantly less dependent on the //chrome layer, bringing us closer to enabling Extension support directly on top of //content + //extensions.
Patch and References
To support this migration, several patches were introduced to move installation-related components into the //extensions layer and decouple them from //chrome.
For readers who are interested in the implementation details, you can find the related changes and discussions here:
These links provide more insight into the design decisions, code changes, and ongoing discussions around the migration.
Demo
Below is a short demo showing the current setup in action.
This demo was recorded using app_shell on Linux, the minimal stripped-down browser container designed to run Chrome Apps and using only //content and //extensions/ layers.
To have this executable launcher, we also extended app_shellwith the minimal functionality required for embedders to install the extension app.
This allows Extensions to be installed and executed without relying on the full Chrome browser implementation, making it easier to experiment with and validate the migration work.
Next Steps
The next short-term goal is to migrate the code required for installing Extensions via the Chrome Web Store into the //extensions layer as well.
At the moment, parts of the Web Store installation flow still depend on the //chrome layer. The next phase of this project will focus on removing those dependencies so that Web Store-based installation can also function within the //extensions layer.
Once this work is completed, embedders will be able to install Extension apps from Chrome WebStore with a significantly simpler architecture (//content + //extensions).
This will make the Extension platform more modular, reusable, and easier to integrate into custom Chromium-based products.
I will continue to share updates as the migration progresses.


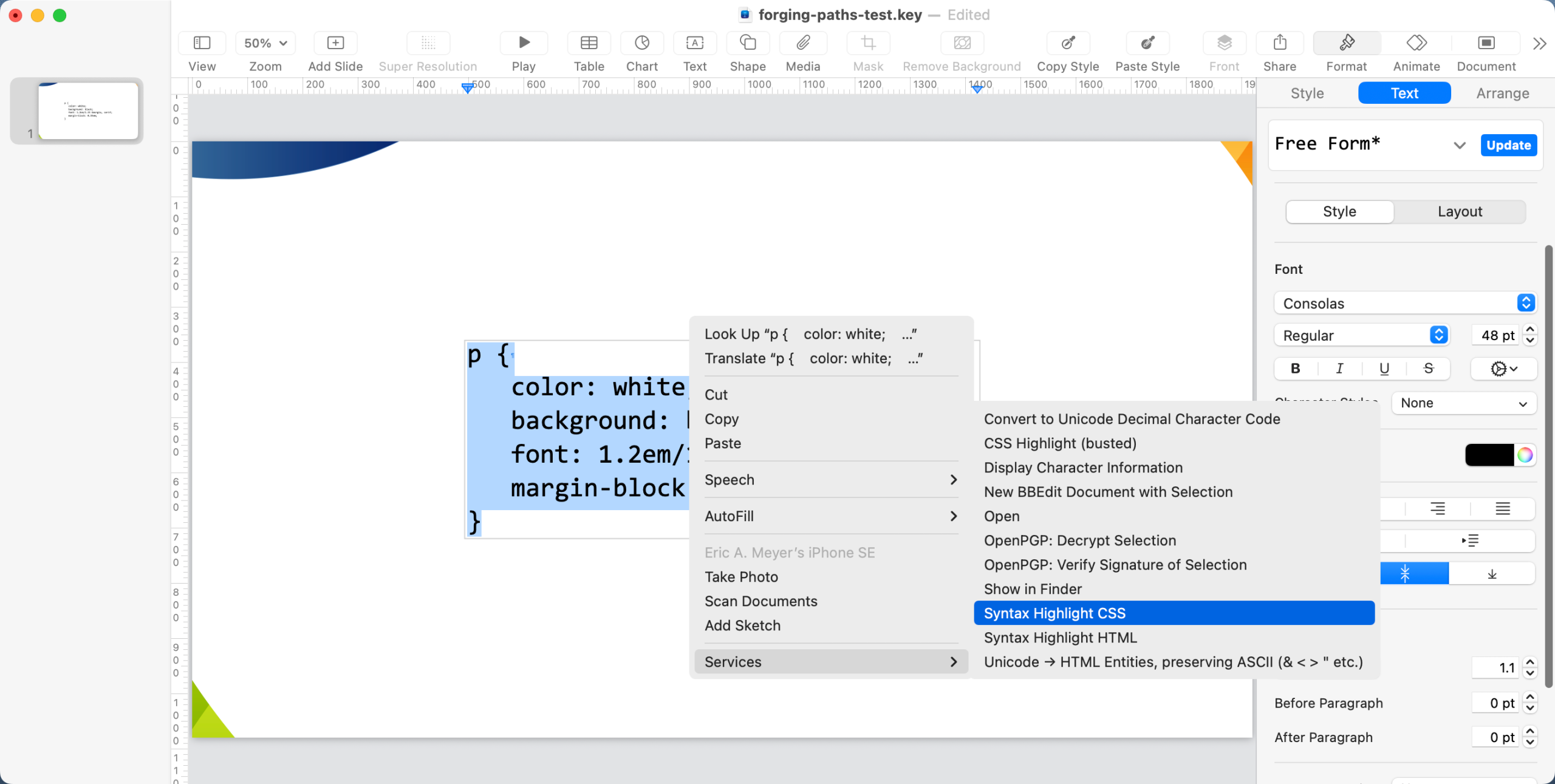
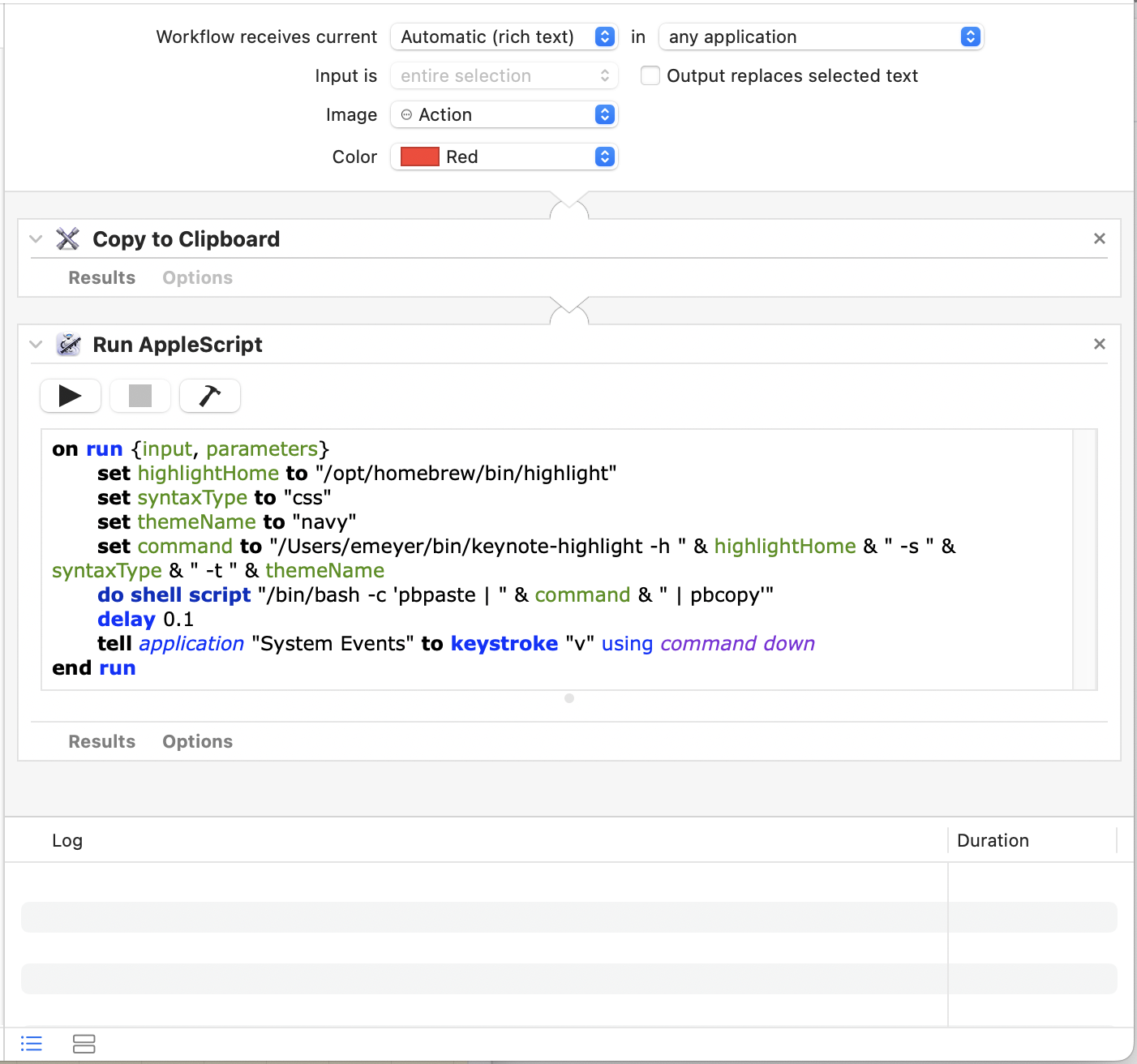


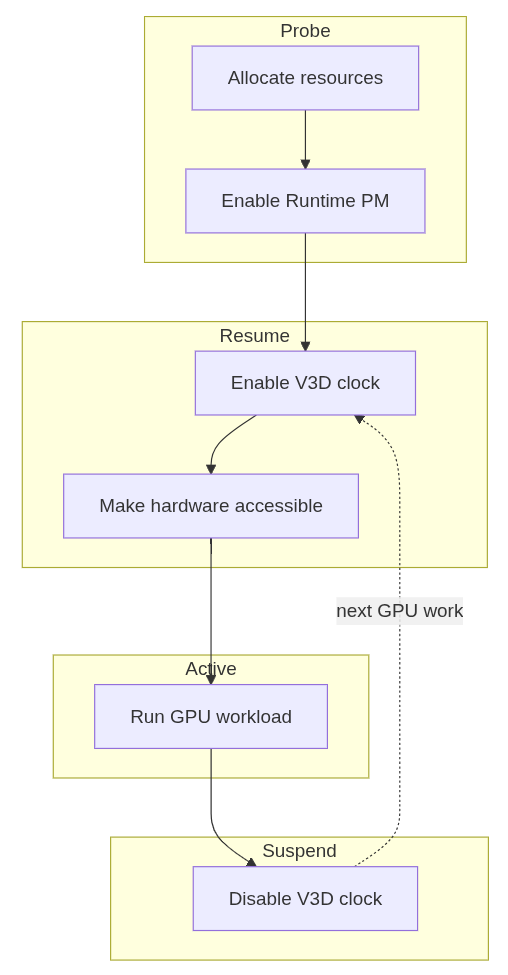
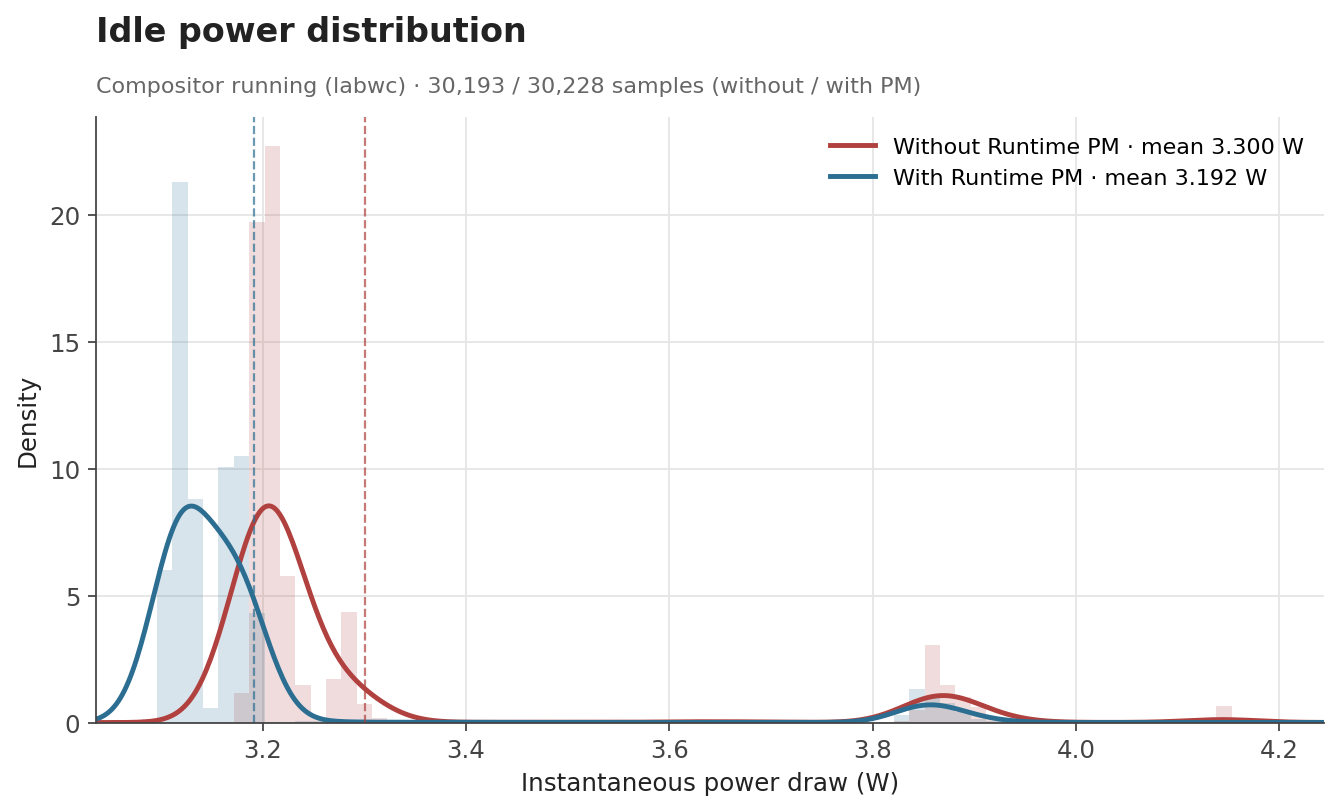
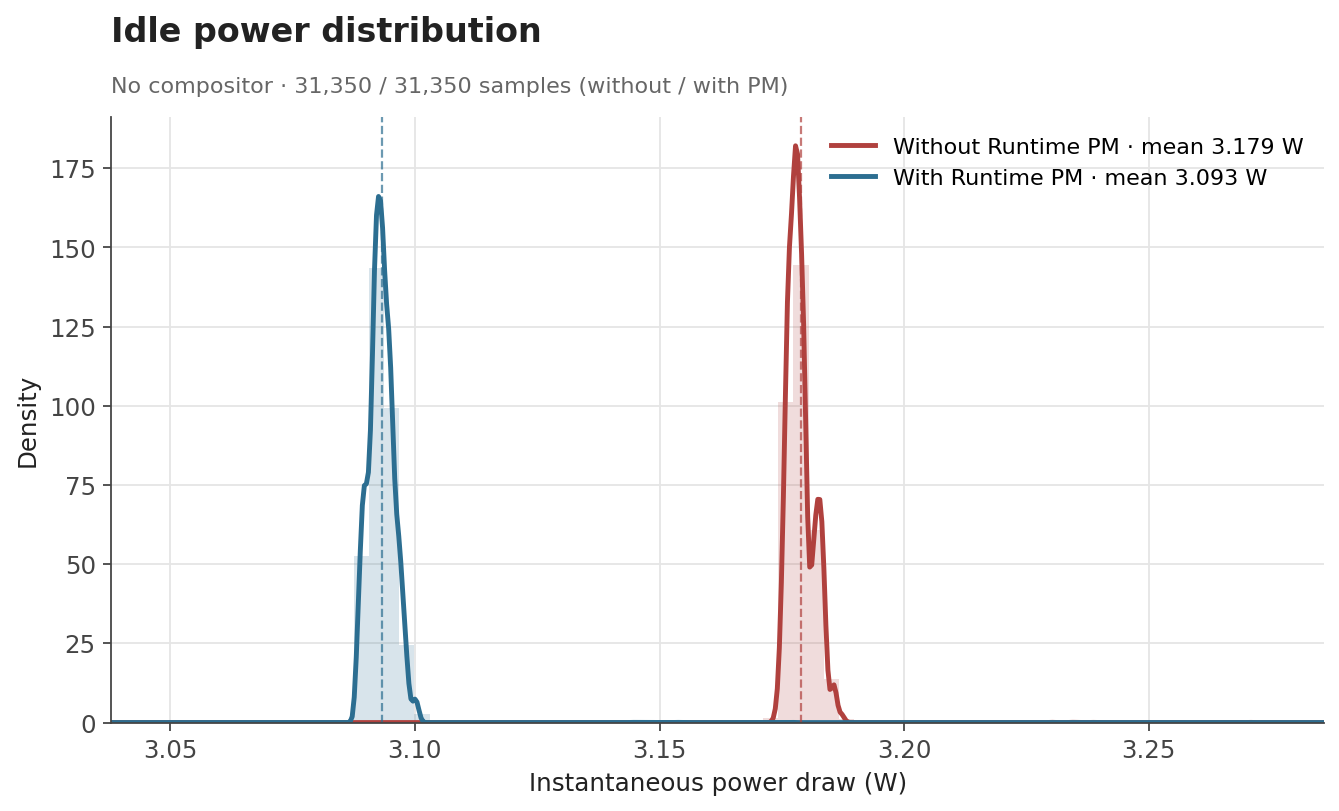
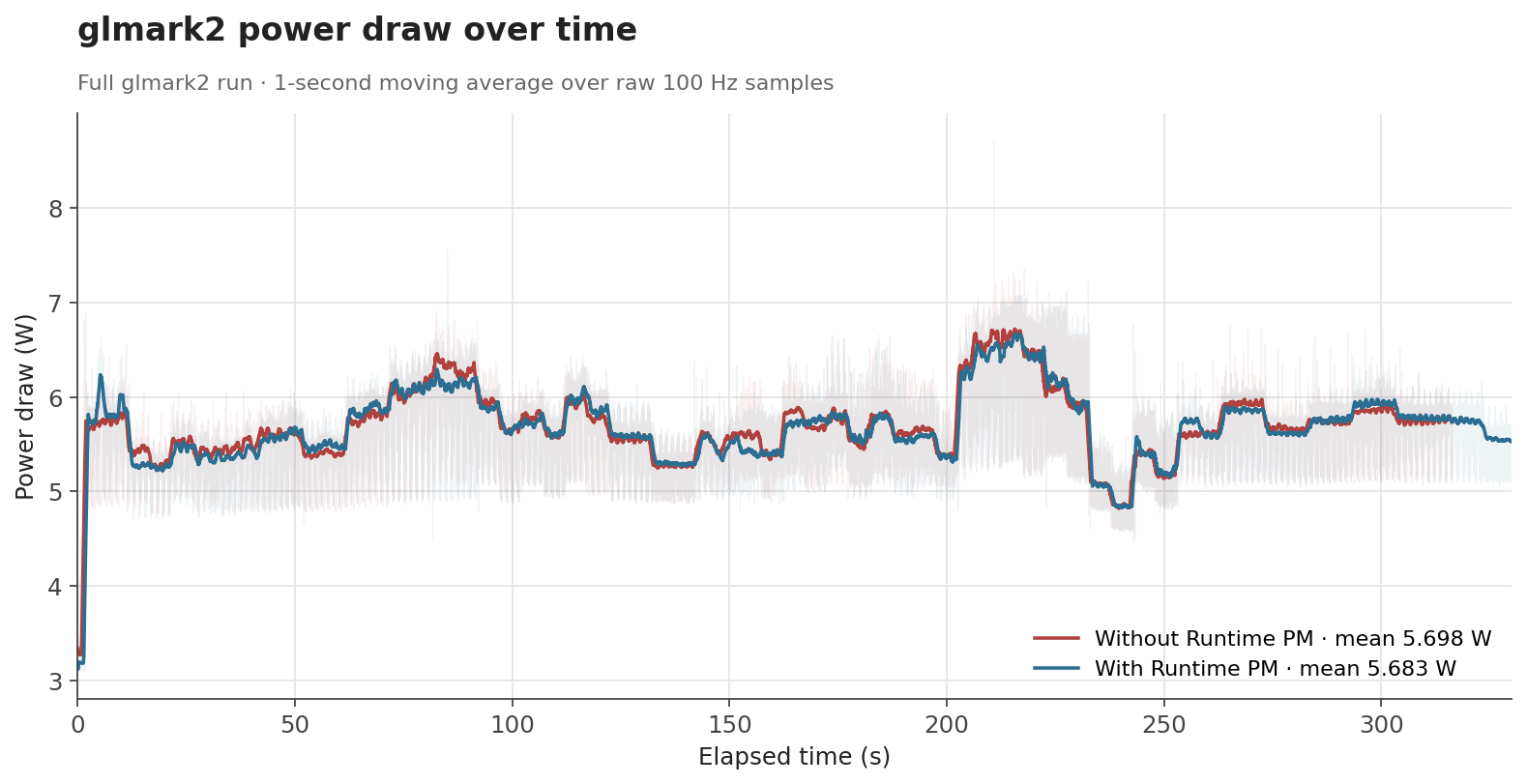










{kind=link}