Hello everyone! As we have with the last bunch of meetings, we're excited to tell you about all the new discussions taking place in TC39 meetings and how we try to contribute to them. However, this specific meeting has an even more special place in our hearts since Igalia had the privilege of organising it in our headquarters in A Coruña, Galicia. It was an absolute honor to host all the amazing delegates in our home city. We would like to thank everyone involved and look forward to hosting it again!
Let's delve together into some of the most exciting updates.
Array.from, which takes a synchronous iterable and dumps it into a new array, is one of Array's most frequently used built-in methods, especially for unit tests or CLI interfaces. However, there was no way to do the equivalent with an asynchronous iterator. Array.fromAsync solves this problem, being to Array.from as for await is to for. This proposal has now been shipping in all JS engines for at least a year (which means it's Baseline 2024), and it has been highly requested by developers.
From a bureaucratic point of view however, the proposal was never really stage 3. In September 2022 it advanced to stage 3 with the condition that all three of the ECMAScript spec editors signed off on the spec text; and the editors requested that a pull request was opened against the spec with the actual changes. However, this PR was not opened until recently. So in this TC39 meeting, the proposal advanced to stage 4, conditional on this editors actually reviewing it.
The Explicit Resource Management proposal introduces implicit cleanup callbacks for objects based on lexical scope. This is enabled through the new using x = declaration:
{ using myFile =open(fileURL); const someBytes = myFile.read();
// myFile will be automatically closed, and the // associated resources released, here at the // end of the block. }
The proposal is now shipped in Chrome, Node.js and Deno, and it's behind a flag in Firefox. As such, Ron Buckton asked for (and obtained!) consensus to approve it for Stage 4 during the meeting.
Similarly to Array.fromAsync, it's not quite Stage 4 yet, as there is still something missing before including it in the ECMAScript standard: test262 tests need to be merged, and the ECMAScript spec editors need to approve the proposed specification text.
The Error.isError(objectToCheck) method provides a reliable way to check whether a given value is a real instance of Error. This proposal was originally presented by Jordan Harband in 2015, to address concerns about it being impossible to detect whether a given JavaScript value is actually an error object or not (did you know that you can throw anything, including numbers and booleans!?). It finally became part of the ECMAScript standard during this meeting.
Intl.Locale objects represent Unicode Locale identifiers; i.e., a combination of language, script, region, and preferences for things like collation or calendar type.
For example, de-DE-1901-u-co-phonebk means "the German language as spoken in Germany with the traditional German orthography from 1901, using the phonebook collation". They are composed of a language optionally followed by:
a script (i.e. an alphabet)
a region
one or more variants (such as "the traditional German orthography from 1901")
a list of additional modifiers (such as collation)
Intl.Locale objects already had accessors for querying multiple properties about the underlying locale but was missing one for the variants due to an oversight, and the committee reached consensus on also exposing them in the same way.
The Intl.Locale Info Stage 3 proposal allows JavaScript applications to query some metadata specific to individual locales. For example, it's useful to answer the question: "what days are considered weekend in the ms-BN locale?".
The committee reached consensus on a change regarding information about text direction: in some locales text is written left-to-right, in others it's right-to-left, and for some of them it's unknown. The proposal now returns undefined for unknown directions, rather than falling back to left-to-right.
Our colleague Philip Chimento presented a regular status update on Temporal, the upcoming proposal for better date and time support in JS. The biggest news is that Temporal is now available in the latest Firefox release! The Ladybird, Graal, and Boa JS engines all have mostly-complete implementations. The committee agreed to make a minor change to the proposal, to the interpretation of the seconds (:00) component of UTC offsets in strings. (Did you know that there has been a time zone that shifted its UTC offset by just 20 seconds?)
The Immutable ArrayBuffer proposal allows creating ArrayBuffers in JS from read-only data, and in some cases allows zero-copy optimizations. After last time, the champions hoped they could get the tests ready for this plenary and ask for stage 3, but they did not manage to finish that on time. However, they did make a very robust testing plan, which should make this proposal "the most well-tested part of the standard library that we've seen thus far". The champions will ask to advance to stage 3 once all of the tests outlined in the plan have been written.
The iterator sequencing Stage 2.7 proposal introduces a new Iterator.concat method that takes a list of iterators and returns an iterator yielding all of their elements. It's the iterator equivalent of Array.prototype.concat, except that it's a static method.
Michael Ficarra, the proposal's champion, was originally planning to ask for consensus on advancing the proposal to Stage 3: test262 tests had been written, and on paper the proposal was ready. However, that was not possible because the committe discussed some changes about re-using "iterator result" objects that require some changes to the proposal itself (i.e. should Iterator.concat(x).next() return the same object as x.next(), or should it re-create it?).
The iterator chunking Stage 2 proposal introduces two new Iterator.prototype.* methods: chunks(size), which splits the iterator into non-overlapping chunks, and windows(size), which generates overlapping chunks offset by 1 element:
[1,2,3,4].values().chunks(2);// [1,2] and [3,4] [1,2,3,4].values().windows(2);// [1,2], [2,3] and [3,4]
The proposal champion was planning to ask for Stage 2.7, but that was not possible due to some changes about the .windows behaviour requested by the committee: what should happen when requesting windows of size n out of an iterator that has less than n elements? We considered multiple options:
Do not yield any array, as it's impossible to create a window of size n
Yield an array with some padding (undefined?) at the end to get it to the expected length
Yield an array with fewer than n elements
The committee concluded that there are valid use cases both for (1) and for (2). As such, the proposal will be updated to split .windows() into two separate methods.
AsyncContext is a proposal that allows having state persisted across async flows of control -- like thread-local storage, but for asynchronicity in JS. The champions of the proposal believe async flows of control should not only flow through await, but also through setTimeout and other web features, such as APIs (like xhr.send()) that asynchronously fire events. However, the proposal was stalled due to concerns from browser engineers about the implementation complexity of it.
In this TC39 session, we brainstormed about removing some of the integration points with web APIs: in particular, context propagation through events caused asynchronously. This would work fine for web frameworks, but not for tracing tools, which is the other main use case for AsyncContext in the web. It was pointed out that if the context isn't propagated implicitly through events, developers using tracing libraries might be forced to snapshot contexts even when they're not needed, which would lead to userland memory leaks. In general, the room seemed to agree that the context should be propagated through events, at the very least in the cases in which this is feasible to implement.
This TC39 discussion didn't do much move the proposal along, and we weren't expecting it to do so -- browser representatives in TC39 are mostly engineers working on the core JS engines (such as SpiderMonkey, or V8), while the concerns were coming from engineers working on web APIs. However, the week after this TC39 plenary, Igalia organized the Web Engines Hackfest, also in A Coruña, where we could resume this conversation with the relevant people in the room. As a result, we've had positive discussions with Mozilla engineers about a possible path forward for the proposal that did propagate the context through events, analyzing more in detail the complexity of some specific APIs where we expect the propagation to be more complex.
The Math.clamp proposal adds a method to clamp a numeric value between two endpoints of a range. This proposal reached stage 1 last February, and in this plenary we discussed and resolved some of the open issues it had:
One of them was whether the method should be a static method Math.clamp(min, value, max), or whether it should be a method on Number.prototype so you could do value.clamp(min, max). We opted for the latter, since in the former the order of the arguments might not be clear.
Another was whether the proposal should support BigInt as well. Since we're making clamp a method of Number, we opted to only support the JS number type. A follow-up proposal might add this on BigInt.prototype as well.
Finally, there was some discussion about whether clamp should throw an exception if min is not lower or equal to max; and in particular, how this should work with positive and negative zeros. The committee agreed that this can be decided during Stage 2.
With this, the Math.clamp (or rather, Number.prototype.clamp) proposal advanced to stage 2. The champion was originally hoping to get to Stage 2.7, but they ended up not proposing it due to the pending planned changes to the proposed specification text.
As it stands, JavaScript's built-in functionality for generating (pseudo-)random numbers does not accept a seed, a piece of data that anchors the generation of random numbers at a fixed place, ensuring that repeated calls to Math.random, for example, produce a fixed sequence of values. There are various use cases for such numbers, such as testing (how can I lock down the behavior of a function that calls Math.random for testing purposes if I don't know what it will produce?). This proposal seeks to add a new top-level Object, Random, that will permit seeding of random number generation. It was generally well received and advanced to stage 2.
Tab Atkins-Bittner, who presented the Seeded PRNG proposal, continued in a similar vein with "More random functions". The idea is to settle on a set of functions that frequently arise in all sorts of settings, such as shuffling an array, generating a random number in an interval, generating a random boolean, and so on. There are a lot of fun ideas that can be imagined here, and the committee was happy to advance this proposal to stage 1 for further exploration.
Eemeli Aro of Mozilla proposed a neat bugfix for two parts of JavaScript's internationalization API that handle numbers. At the moment, when a digit string, such as "123.456" is given to the Intl.PluralRules and Intl.NumberFormat APIs, the string is converted to a Number. This is generally fine, but what about digit strings that contain trailing zeroes, such as "123.4560"? At the moment, that trailing zero gets removed and cannot be recovered. Eemeli suggest that we keep such digits. They make a difference when formatting numbers and in using them for pluralizing words, such as "1.0 stars". This proposal advanced to stage 1, with the understanding that some work needs to be done to clarify how some some already-existing options in the NumberFormat and PluralRules APIs are to be understood when handling such strings. Eemeli's proposal is now at stage 1!
We shared the latest developments on the Decimal proposal and its potential integration with Intl, focusing on the concept of amounts. These are lightweight wrapper classes designed to pair a decimal number with an integer "precision", representing either the number of significant digits or the number of fractional digits, depending on context. The discussion was a natural follow-on to the earlier discussion of keeping trailing zeroes in Intl.NumberFormat and Intl.PluralRules. In discussions about decimal, we floated the idea of a string-based version of amounts, as opposed to one backed by a decimal, but this was a new, work-in-progress idea. It seems that the committee is generally happy with the underlying decimal proposal but not yet convinced about the need for a notion of an amount, at least as it was presented. Decimal stays at stage 1.
Many JS environments today provide some sort of assertion functions. (For example, console.assert, Node.js's node:assert module, the chai package on NPM.) The committee discussed a new proposal presented by Jacob Smith, Comparisons, which explores whether this kind of functionality should be part of the ECMAScript standard. The proposal reached stage 1, so the investigation and scoping will continue: should it cover rich equality comparisons, should there be some sort of test suite integration, should there be separate debug and production modes? These questions will be explored in future meetings.
If you look at the specifications for HTML, the DOM, and other web platform features, you can't miss the Web IDL snippets in there. This IDL is used to describe all of the interfaces available in web browser JS environments, and how each function argument is processed and validated.
IDL does not only apply to the specifications! The IDL code is also copied directly into web browsers' code bases, sometimes with slight modifications, and used to generate C++ code.
Tooru Fujisawa (Arai) from Mozilla brought this proposal back to the committee after a long hiatus, and presented a vision of how the same thing might be done in the ECMAScript specification, gradually. This would lower maintenance costs for any JS engine, not just web browsers. However, the way that function arguments are generally handled differs sufficiently between web platform APIs and the ECMAScript specification that it wouldn't be possible to just use the same Web IDL directly.
Tooru presented some possible paths to squaring this circle: adding new annotations to the existing Web IDL or defining new syntax to support the ECMAScript style of operations.
The May 2025 plenary was packed with exciting progress across the JavaScript language and internationalization features. It was also a special moment for us at Igalia as proud hosts of the meeting in our hometown of A Coruña.
We saw long-awaited proposals like Array.fromAsync, Error.isError, and Explicit Resource Management reach Stage 4, while others continued to evolve through thoughtful discussion and iteration.
We’ll continue sharing updates as the work evolves, until then, thanks for reading, and see you at the next meeting!
Update on what happened in WebKit in the week from June 24 to July 1.
This was a slow week, where the main highlight are new development
releases of WPE WebKit and WebKitGTK.
Cross-Port 🐱
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Made some further progress bringing the 32-bit version of OMG closer to the 64-bit one
Releases 📦️
WebKitGTK 2.49.3 and WPE WebKit 2.49.3 have been released. These are development snapshots intended to allow those interested to test the new features and improvement which will be part of the next stable release series. As usual, bug reports are welcome in the WebKit Bugzilla.
Back in September 2024 I wrote a piece about the history of attempts at standardizing some kind of Micropayments going back to the late 90s. Like a lot of things I write, it's the outcome of looking at history and background for things that I'm actively thinking about. An announcement the other day made me think that perhaps now is a good time for a follow up post.
As you probably already know if you're reading this, I write and think a lot about the health of the web ecosystem. We've even got a whole playlist of videos (lots of podcast episodes) on the topic on YouTube. Today, that's nearly all paid for, on all sides, by advertising. In several important respects, it's safe to say that the status quo is under many threats. In several ways it's also worth questioning if the status quo is even good.
When Ted Nelson first imagined Micropayments in the 1960s, he was imaging a fair economic model for digital publishing. We've had many ideas and proposals since then. Web Monetization is one idea which isn't dead yet. Its main ideas involve embedding a declarative link to a "payment pointer" (like a wallet address) where payments can be sent via Interledger. I say "sent", but "streamed" might be more accurate. Interledger is a novel idea which treats money as "packets" and routes small amounts around. Full disclosure: Igalia has been working on some prototype work in Chromium to help see what a native implementation would look like, what its architecture would be and what options this opens (or closes). Our work has been funded by the Interledger Foundation. It does not amount to an endorsement, and it does not mean something will ship. That said, it doesn't mean the opposite either.
You might know that Brave, another Chromium-based browser, has system for creators too. In their model, publishers/creators sign up and verify their domain (or social accounts!), and people browsing those with Brave browsers sort of keep track of that locally, and at the end of the month Brave can batch up and settle accounts of Basic Attention Tokens ("BAT") which they can then pay out to creators in lump sums. As of the time of this writing, Brave has 88 million monthly active users (source) who could be paying its 1.67 million plus content creators and publishers (source).
Finally, in India, UPI offers most transactions free of charge and can also be used for micro payments - it's being used in $240 billion USD / month worth of transactions!
But there's also some "adjacent" stuff that doesn't claim to be micro transactions but somehow are similar:
If you've ever used Microsoft's Bing search engine, they also give you "points" (I like to call them "Bing Bucks") which you can trade in for other stuff (the payment is going in a different direction!). There was also Scroll, years ago, which was aimed to be a kind of universal service you could pay into to remove ads on many properties (it was bought by Twitter and shut down.)
Enter: Offerwall
Just the other day, Google Ad Manager gave a new idea a potentially really signficant boost. I think it's worth looking at: Offerwall. Offerwall lets sites provide potentially a few ways to monetize content, and for users to choose the one that they prefer. For example, a publisher can set up to allow reading their site in exchange for watching an ad (similar to YouTube's model). That's pretty interesting, but far more interesting to me, is that it integrates with a third-party service called Supertab. Supertab lets people provide their own subscriptions - including a tiny fee for this page, or access to the site for some timed pass - 4 hours, 24 hours, a week, etc. It does this with pretty friction-less wallet integration and by 'pooling' the funds until it makes sense to do a real, regular transaction. Perhaps the easiest thing is to look at some of their own examples.
Offerwall also allows other integrations, so maybe we'll see some of these begin to come together somehow too.
It's a very interesting way to split the difference and address a few complaints of micro transaction critics and generally people skeptical that something could gain significant traction. More than that even, it seems to me that by integrating with Google Ad manager it's got about as much advantage as anyone could get (the vast majority of ads are already served with Google Ad manager and this actually tries to expand that).
I'm very keen to see how this all plays out! What do you think will happen? Share your thoughts with me on social media.
Multiple MediaRecorder-related improvements landed in main recently (1, 2, 3, 4), and also in GStreamer.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
JSC saw some fixes in i31 reference types when using Wasm GC.
WPE WebKit 📟
WPE now has support for analog gamepad buttons when using libwpe. Since version 1.16.2 libwpe has the capability to handle analog gamepad button events, but the support on the WPE side was missing. It has now been added, and will be enabled when the appropriate versions of libwpe are used.
I've been kicking the tires on various LLMs lately, and like many have been
quite taken by the pace of new releases especially of models with weights
distributed under open licenses, always with impressive benchmark results. I
don't have local GPUs so trialling different models necessarily requires using
an external host. There are various configuration parameters you can set when
sending a query that affect generation and many vendors document
recommended settings on the model card or associated documentation. For my own
purposes I wanted to collect these together in one place, and also confirm in
which cases common serving software like
vLLM will use defaults provided
alongside the model.
Main conclusions
If accessing a model via a hosted API you typically don't have much insight
into their serving setup, so explicitly setting parameters client-side is
probably your best bet if you want to try out a model and ensure any
recommended parameters are applied to generation.
Although recent versions of vLLM will take preferred parameters from
generation_config.json, not all models provide that file or if they do,
they may not include their documented recommendations in it.
Some model providers have very strong and clear recommendations about which
parameters to set to which values, for others it's impossible to find any
guidance one way or another (or even what sampling setup was used for their
benchmark results).
Sadly there doesn't seem to be a good alternative to trawling through the
model descriptions and associated documentation right now (though hopefully
this page helps!).
Even if every model starts consistently setting preferred parameters in
generation_config.json (and inference API providers respect this), and/or
a standard like model.yaml is adopted containing
these parameters, some attention may still be required if a model has
different recommendations for different use cases / modes (as Qwen3 does).
And of course there's a non-conclusion on how much this really matters. I
don't know. Clearly for some models it's deemed very important, for the
other's it's not always clear whether it just doesn't matter much, or if the
model producer has done a poor job of documenting it.
Overview of parameters
The parameters supported by vLLM are documented
here,
though not all are supported in the HTTP API provided by different vendors.
For instance, the subset of parameters supported by models on
Parasail (an inference API provider I've been
kicking the tires on recently) is documented
here
I cover just that subset below:
temperature: controls the randomness of sampling of tokens. Lower values are
more deterministic, higher values are more random. This is one the
parameters you'll see spoken about the most.
top_p: limits the tokens that are considered. If set to e.g. 0.5 then only
consider the top most probable tokens whose summed probability doesn't
exceed 50%.
top_k: also limits the tokens that are considered, such that only the top
k tokens are considered.
frequency_penalty: penalises new tokens based on their frequency in the
generated text. It's possible to set a negative value to encourage
repetition.
presence_penalty: penalises new tokens if they appear in the generated text
so far. It's possible to set a negative value to encourage repetition.
repetition_penalty: This is documented as being a parameter that penalises
new tokens based on whether they've appeared so far in the generated text or
prompt.
Based on that description it's not totally obvious how it differs from the
frequency or presence penalties, but given the description talks about
values less than 1 penalising repeated tokens and less than 1 encouraging
repeated tokens we can infer this is applied as a multiplication on
rather than an addition.
We can confirm this implementation by tracing through where penalties are
applied in vllm's
sampler.py,
which in turn calls the apply_penalties helper
function.
This confirms how the frequency and presence penalties are applied based
only on the output, unlike the repetition penalty is applied taking the
prompt into account as well. Following the call-stack down to an
implementation of the repetition
penalty
shows that if the
logit
is positive, it divides by the penalty and otherwise multiplies by it.
This was a pointless sidequest as this is a vllm-specific parameter that
none of the models I've seen has a specific recommendation for.
Default vLLM behaviour
The above settings are typically exposed via the API, but what if you don't
explicitly set them? vllm
documents
that it will by default apply settings from generation_config.json
distributed with the model on HuggingFace if it exists (overriding its own
defaults), but you can ignore generation_config.json to just use vllm's own
defaults by setting --generation-config vllm when launching the server. This
behaviour was introduced in a PR that landed in early March this
year. We'll explore below
which models actually have a generation_config.json with their recommended
settings, but what about parameters not set in that file, or if that file
isn't present? As far as I can see, that's where
_DEFAULT_SAMPLING_PARAMS
comes in and we get temperature=1.0 and repetition_penalty, top_p, top_k and
min_p set to values that have no effect on the sampler.
Although Parasail use vllm for serving most (all?) of their hosted models,
it's not clear if they're running with a configuration that allows defaults to
be taken from generation_config.json. I'll update this post if that is
clarified.
Recommended parameters from model vendors
As all of these models are distributed with benchmark results front and
center, it should be easy to at least find what settings were used for these
results, even if it's not an explicit recommendation on which parameters to
use - right? Let's find out. I've decided to step through models groups by
their level of openness.
Recommendation: temperature=0.3 (specified on model card)
generation_config.json with recommended parameters: No.
Notes:
This model card is what made me pay more attention to these parameters -
DeepSeek went as far as to map a temperature of 1.0 via the API to
their recommended
0.3
(temperatures between 0 and 1 are multiplied by 0.7, and they subtract
0.7 for temperatures between 1 and 2). So clearly they're keen to
override clients that default to setting temperture=1.0.
There's no generation_config.json and the V3 technical
report indicates they used
temperature=0.7 for for some benchmarks. They also state "Benchmarks
containing fewer than 1000 samples are tested multiple times using varying
temperature settings to derive robust final results" (not totally clear if
results are averaged, or the best result is taken). There's no
recommendation I can see for other generation parameters, and to add some
extra confusion the DeepSeek API docs have a page on the temperature
parameter
with specific recommendations for different use cases and it's not totally
clear if these apply equally to V3 (after its temperature scaling) and R1.
Recommendation: temperature=0.6, top_p=0.95 (specified on model
card)
generation_config.json with recommended parameters: Yes.
Notes: They report using temperature=0.6 and top_p=0.95 for their
benchmarks (this is stated both on the model card and the
paper) and state that temperature=0.6
is the value used for the web chatbot interface. They do have a
generation_config.json that includes that
setting.
Notes: I saw that one of Mistral's API
methods
for their hosted models returns the default_model_temperature. Executing
curl --location "https://api.mistral.ai/v1/models" --header "Authorization: Bearer $MISTRAL_API_KEY" | jq -r '.data[] | "\(.name): \(.default_model_temperature)"' | sort gives some confusing results. The
mistral-small-2506 version isn't yet available on the API. But the older
mistral-small-2501 is, with a default temperature of 0.3 (differing
from the recommendation on the model
card.
mistral-small-2503 has null for its default temperature. Go figure.
generation_config.json with recommended parameters: No.
Notes: This is a fine-tune of Mistral-Small-3.1. There is no explicit
recommendation for temperature on the model card, but the example code
does use temperature=0.15. However, this isn't set in
generation_config.json
(which doesn't set any default parameters) and Mistral's API indicates a
default temperature of 0.0.
Recommendation: temperature=0.7, top_p=0.95 (specified on model
card)
generation_config.json with recommended parameters:
No (file exists, but parameters missing).
Notes: The model card has a very clear recommendation to use
temperature=0.7 and top_p=0.95 and this default temperature is also reflected
in Mistral's API mentioned above.
qwen3
family
including Qwen/Qwen3-235B-A22B, Qwen/Qwen3-30B-A3B, Qwen/Qwen3-32B, and
more.
Recommendation: temperature=0.6, top_p=0.95, top_k=20, min_p=0 for thinking mode
and for non-thinking mode temperature=0.7, top_p=0.8, top_k=20min_p=0 (specified on model card)
generation_config.json with recommended parameters: Yes, e.g. for
Qwen3-32B
(uses the "thinking mode" recommendations). (All the ones I've checked
have this at least).
Notes: Unlike many others, there is a very clear recommendation under
the best practices section of each model
card, which for all
models in the family that I've checked makes the same recommendation. They
also suggest setting the presence_penalty between 0 and 2 to reduce
endless repetitions. The Qwen 3 technical
report notes the same parameters but
also states that for the non-thinking mode they set presence_penalty=1.5
and applied the same setting for thinking mode for the Creative Writing v3
and WritingBench benchmarks.
generation_config.json with recommended parameters:
Yes
(temperature=1.0 should be the vllm default anyway, so it shouldn't
matter it isn't specified).
Notes: It was surprising to not see more clarity on this in the model
card or technical
report,
neither of which have an explicit recommendation. As noted above, the
generation_config.json does set top_k and top_p and the Unsloth
folks apparently had confirmation from the Gemma team on recommended
temperature though I couldn't find a public comment directly from
the Gemma team.
generation_config.json with recommended parameters:
Yes.
Notes: There was no discussion of recommended parameters in the model
card itself. I accessed generation_config.json via a third-party mirror
as providing name and DoB to view it on HuggingFace (as required by
Llama's restrictive access policy) seems ridiculous.
model.yaml
As it happens, while writing this blog post I saw Simon Willison blogged
about model.yaml.
Model.yaml is an initiative from the LM Studio folks
to provide a definition of a model and its sources that can be used with
multiple local inference tools. This includes the ability to specify preset
options for the model. It doesn't appear to be used by anyone else though, and
looking at the LM Studio model catalog, taking
qwen/qwen3-32b as an example:
although the Qwen3 series have very strongly recommended default settings, the
model.yaml only sets top_k and min_p, leaving temperature and top_p
unset.
The DRM GPU scheduler is a shared Direct Rendering Manager (DRM) Linux Kernel level component used by a number of GPU drivers for managing job submissions from multiple rendering contexts to the hardware. Some of the basic functions it can provide are dependency resolving, timeout detection, and most importantly for this article, scheduling algorithms whose essential purpose is picking the next queued unit of work to execute once there is capacity on the GPU.
Different kernel drivers use the scheduler in slightly different ways - some simply need the dependency resolving and timeout detection part, while the actual scheduling happens in the proprietary firmware, while others rely on the scheduler’s algorithms for choosing what to run next. The latter ones is what the work described here is suggesting to improve.
More details about the other functionality provided by the scheduler, including some low level implementation details, are available in the generated kernel documentation repository[1].
Three DRM scheduler data structures (or objects) are relevant for this topic: the scheduler, scheduling entities and jobs.
First we have a scheduler itself, which usually corresponds with some hardware unit which can execute certain types of work. For example, the render engine can often be single hardware instance in a GPU and needs arbitration for multiple clients to be able to use it simultaneously.
Then there are scheduling entities, or in short entities, which broadly speaking correspond with userspace rendering contexts. Typically when an userspace client opens a render node, one such rendering context is created. Some drivers also allow userspace to create multiple contexts per open file.
Finally there are jobs which represent units of work submitted from userspace into the kernel. These are typically created as a result of userspace doing an ioctl(2) operation, which are specific to the driver in question.
Jobs are usually associated with entities and entities are then executed by schedulers. Each scheduler instance will have a list of runnable entities (entities with least one queued job) and when the GPU is available to execute something it will need to pick one of them.
Typically every userspace client will submit at least one such job per rendered frame and the desktop compositor may issue one or more to render the final screen image. Hence, on a busy graphical desktop, we can find dozens of active entities submitting multiple GPU jobs, sixty or more times per second.
In order to select the next entity to run, the scheduler defaults to the First In First Out (FIFO) mode of operation where selection criteria is the job submit time.
The FIFO algorithm in general has some well known disadvantages around the areas of fairness and latency, and also because selection criteria is based on job submit time, it couples the selection with the CPU scheduler, which is also not desirable because it creates an artifical coupling between different schedulers, different sets of tasks (CPU processes and GPU tasks), and different hardware blocks.
This is further amplified by the lack of guarantee that clients are submitting jobs with equal pacing (not all clients may be synchronised to the display refresh rate, or not all may be able to maintain it), the fact their per frame submissions may consist of unequal number of jobs, and last but not least the lack of preemption support. The latter is true both for the DRM scheduler itself, but also for many GPUs in their hardware capabilities.
Apart from uneven GPU time distribution, the end result of the FIFO algorithm picking the sub-optimal entity can be dropped frames and choppy rendering.
Apart from the default FIFO scheduling algorithm, the scheduler also implements the round-robin (RR) strategy, which can be selected as an alternative at kernel boot time via a kernel argument. Round-robin, however, suffers from its own set of problems.
Whereas round-robin is typically considered a fair algorithm when used in systems with preemption support and ability to assign fixed execution quanta, in the context of GPU scheduling this fairness property does not hold. Here quanta are defined by userspace job submissions and, as mentioned before, the number of submitted jobs per rendered frame can also differ between different clients.
The final result can again be unfair distribution of GPU time and missed deadlines.
In fact, round-robin was the initial and only algorithm until FIFO was added to resolve some of these issue. More can be read in the relevant kernel commit. [2]
Another issue in the current scheduler design are the priority queues and the strict priority order execution.
Priority queues serve the purpose of implementing support for entity priority, which usually maps to userspace constructs such as VK_EXT_global_priority and similar. If we look at the wording for this specific Vulkan extension, it is described like this[3]:
The driver implementation *will attempt* to skew hardware resource allocation in favour of the higher-priority task. Therefore, higher-priority work *may retain similar* latency and throughput characteristics even if the system is congested with lower priority work.
As emphasised, the wording is giving implementations leeway to not be entirely strict, while the current scheduler implementation only executes lower priorities when the higher priority queues are all empty. This over strictness can lead to complete starvation of the lower priorities.
To solve both the issue of the weak scheduling algorithm and the issue of priority starvation we tried an algorithm inspired by the Linux kernel’s original Completely Fair Scheduler (CFS)[4].
With this algorithm the next entity to run will be the one with least virtual GPU time spent so far, where virtual GPU time is calculated from the the real GPU time scaled by a factor based on the entity priority.
Since the scheduler already manages a rbtree[5] of entities, sorted by the job submit timestamp, we were able to simply replace that timestamp with the calculated virtual GPU time.
When an entity has nothing more to run it gets removed from the tree and we store the delta between its virtual GPU time and the top of the queue. And when the entity re-enters the tree with a fresh submission, this delta is used to give it a new relative position considering the current head of the queue.
Because the scheduler does not currently track GPU time spent per entity this is something that we needed to add to make this possible. It however did not pose a significant challenge, apart having a slight weakness with the up to date utilisation potentially lagging slightly behind the actual numbers due some DRM scheduler internal design choices. But that is a different and wider topic which is out of the intended scope for this write-up.
The virtual GPU time selection criteria largely decouples the scheduling decisions from job submission times, to an extent from submission patterns too, and allows for more fair GPU time distribution. With a caveat that it is still not entirely fair because, as mentioned before, neither the DRM scheduler nor many GPUs support preemption, which would be required for more fairness.
Because priority is now consolidated into a single entity selection criteria we were also able to remove the per priority queues and eliminate priority based starvation. All entities are now in a single run queue, sorted by the virtual GPU time, and the relative distribution of GPU time between entities of different priorities is controlled by the scaling factor which converts the real GPU time into virtual GPU time.
Another benefit of being able to remove per priority run queues is a code base simplification. Going further than that, if we are able to establish that the fair scheduling algorithm has no regressions compared to FIFO and RR, we can also remove those two which further consolidates the scheduler. So far no regressions have indeed been identified.
As an first example we set up three demanding graphical clients, one of which was set to run with low priority (VK_QUEUE_GLOBAL_PRIORITY_LOW_EXT).
One client is the Unigine Heaven benchmark[6] which is simulating a game, while the other two are two instances of the deferredmultisampling Vulkan demo from Sascha Willems[7], modified to support running with the user specified global priority. Those two are simulating very heavy GPU load running simultaneouosly with the game.
All tests are run on a Valve Steam Deck OLED with an AMD integrated GPU.
First we try the current FIFO based scheduler and we monitor the GPU utilisation using the gputop[8] tool. We can observe two things:
That the distribution of GPU time between the normal priority clients is not equal.
That the low priority client is not getting any GPU time.
Switching to the CFS inspired (fair) scheduler the situation changes drastically:
GPU time distribution between normal priority clients is much closer together.
Low priority client is not starved, but receiving a small share of the GPU.
Note that the absolute numbers are not static but represent a trend.
This proves that the new algorithm can make the low priority useful for running heavy GPU tasks in the background, similar to what can be done on the CPU side of things using the nice(1) process priorities.
Apart from experimenting with real world workloads, another functionality we implemented in the scope of this work is a collection of simulated workloads implemented as kernel unit tests based on the recently merged DRM scheduler mock scheduler unit test framework[9][10]. The idea behind those is to make it easy for developers to check for scheduling regressions when modifying the code, without the need to set up sometimes complicated testing environments.
Let us look at a few examples on how the new scheduler compares with FIFO when using those simulated workloads.
First an easy, albeit exaggerated, illustration of priority starvation improvements.
Here we have a normal priority client and a low priority client submitting many jobs asynchronously (only waiting for the submission to finish after having submitted the last job). We look at the number of outstanding jobs (queue depth - qd) on the Y axis and the passage of time on the X axis. With the FIFO scheduler (blue) we see that the low priority client is not making any progress whatsoever, all until the all submission of the normal client have been completed. Switching to the CFS inspired scheduler (red) this improves dramatically and we can see the low priority client making slow but steady progress from the start.
Second example is about fairness where two clients are of equal priority:
Here the interesting observation is that the new scheduler graphed lines are much more straight. This means that the GPU time distribution is more equal, or fair, because the selection criteria is decoupled from the job submission time but based on each client’s GPU time utilisation.
For the final set of test workloads we will look at the rate of progress (aka frames per second, or fps) between different clients.
In both cases we have one client representing a heavy graphical load, and one representing an interactive, lightweight client. They are running in parallel but we will only look at the interactive client in the graphs. Because the goal is to look at what frame rate the interactive client can achieve when competing for the GPU. In other words we use that as a proxy for assessing user experience of using the desktop while there is simultaneous heavy GPU usage from another client.
The interactive client is set up to spend 1ms of GPU time in every 10ms period, resulting in an effective GPU load of 10%.
First test is with a heavy client wanting to utilise 75% of the GPU by submitting three 2.5ms jobs back to back, repeating that cycle every 10ms.
We can see that the average frame rate the interactive client achieves with the new scheduler is much higher than under the current FIFO algorithm.
For the second test we made the heavy GPU load client even more demanding by making it want to completely monopolise the GPU. It is now submitting four 50ms jobs back to back, and only backing off for 1us before repeating the loop.
Again the new scheduler is able to give significantly more GPU time to the interactive client compared to what FIFO is able to do.
From all the above it appears that the experiment was successful. We were able to simplify the code base, solve the priority starvation and improve scheduling fairness and GPU time allocation for interactive clients. No scheduling regressions have been identified to date.
The complete patch series implementing these changes is available at[11].
Because this work has simplified the scheduler code base and introduced entity GPU time tracking, it also opens up the possibilities for future experimenting with other modern algorithms. One example could be an EEVDF[12] inspired scheduler, given that algorithm has recently improved upon the kernel’s CPU scheduler and is looking potentially promising for it is combining fairness and latency in one algorithm.
Connection with the DRM scheduling cgroup controller proposal #
Another interesting angle is that, as this work implements scheduling based on virtual GPU time, which as a reminder is calculated by scaling the real time by a factor based on entity priority, it can be tied really elegantly to the previously proposed DRM scheduling cgroup controller.
There we had group weights already which can now be used when scaling the virtual time and lead to a simple but effective cgroup controller. This has already been prototyped[13], but more on that in a following blog post.
Update on what happened in WebKit in the week from May 27 to June 16.
After a short hiatus coinciding with this year's edition of the Web Engines
Hackfest, this issue covers a mixed bag of new API features, releases,
multimedia, and graphics work.
Cross-Port 🐱
A new WebKitWebView::theme-color property has
beenadded to the public API, along with a
corresponding webkit_web_view_get_theme_color() getter. Its value follows
that of the theme-color metadata
attribute
declared by pages loaded in the web view. Although applications may use the
theme color in any way they see fit, the expectation is that it will be used to
adapt their user interface (as in this
example) to
complement the Web content being displayed.
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
Damage propagation has been toggled for the GTK
port: for now only a single rectangle
is passed to the UI process, which then is used to let GTK know which part of a
WebKitWebView has received changes since the last repaint. This is a first
step to get damage tracking code widely tested, with further improvements to be
enabled later when considered appropriate.
Adaptation of WPE WebKit targeting the Android operating system.
WPE-Android 0.2.0
has been released. The main change in this version is the update to WPE WebKit
2.48.3, which is the first that can be built for Android out of the box,
without needing any additional patching. Thanks to this, we expect that the WPE
WebKit version used will receive more frequent updates going forward. The
prebuilt packages available at the Maven Central
repository
have been updated accordingly.
Releases 📦️
WebKitGTK
2.49.2 and
WPE WebKit 2.49.2 have
been released. These are development snapshots and are intended to let those
interested test out upcoming features and improvements, and as usual issue
reports are welcome in Bugzilla.
The Yocto project has well-established OS update mechanisms available via third-party layers. But, did you know that recent releases of Yocto already come with a simple update mechanism?
The goal of this blog post is to present an alternative that doesn’t require a third-party layer and explain how it can be integrated with your Yocto-based image.
Enter systemd-sysupdate: a mechanism capable of automatically discovering, downloading, and installing A/B-style OS updates. In a nutshell, it provides:
Atomic updates for a collection of different resources (files, directories or partitions).
Updates from remote and local sources (HTTP/HTTPS and directories).
Parallel installed versions A/B/C/… style.
Relative small footprint (~10 MiB or roughly 5% increase in our demo image).
Basic features are available since systemd 251 (released in May 2022).
Optional built-in services for updating and rebooting.
Optional DBus interface for applications integration.
Optional grouping of resources to be enabled together as features.
Together with automatic boot assessment, systemd-boot, and other tools, we can turn this OS update mechanism into a comprehensive alternative for common scenarios.
In order for sysupdate to determine the current version of the OS, it looks for the os-release file and inspects it for an IMAGE_VERSION field. Therefore, the image version must be included.
Resources that require updating must also be versioned with the image version. Following our previous assumptions:
The UKI filename is suffixed with the image version (e.g., uki_0.efi where 0 is the image version).
The rootfs partition is also versioned by suffixing the image version in its partition name (e.g., rootfs_0 could be the initial name of the partition).
To implement these changes in your Yocto-based image, the following recipes should be added or overridden:
Note that the value of IMAGE_VERSION can be hardcoded, provided by the continuous integration pipeline or determined at build-time (e.g., the current date and time).
In the above recipes, we’re adding the suffix to the UKI filename and partition name, and we’re also coupling our UKI directly to its correspondent rootfs partition.
By default, sysupdate is disabled in Yocto’s systemd recipe and there are no “default” transfer files for sysupdate. Therefore you must:
Override systemd build configuration options and dependencies.
Write transfer files for each resource that needs to be updated.
Extend the partitions kickstart file with an additional partition that must mirror the original rootfs partition. This is to support an A/B OS update scheme.
To implement these changes in your Yocto-based image, the following recipes should be added or modified:
Updates can be served locally via regular directories or remotely via a regular HTTP/HTTPS web server. For Over-the-air (OTA) updates, HTTP/HTTPS is the correct option. Any web server can be used.
When using HTTP/HTTPS, sysupdate will request a SHA256SUMS checksum file. This file acts as the update server’s “manifest”, describing what updated resources are available.
Over the past few months I had the chance to spend some time looking at an
interesting new FUSE feature. This feature, merged into the Linux kernel 6.14
release, has introduced the ability to perform the communication between the
user-space server (or FUSE server) and the kernel using io_uring. This means
that file systems implemented in user-space will get a performance improvement
simply by enabling this new feature.
But let's start with the beginning:
What is FUSE?
Traditionally, file systems in *nix operating systems have been implemented
within their (monolithic) kernels. From the BSDs to Linux, file systems were
all developed in the kernel. Obviously, the exceptions already existed since
the beginning as well. Micro-kernels, for example, could be executed in ring0,
while their file systems would run as servers with lower privileged levels. But
these were the exceptions.
There are, however, several advantages in implementing them in user-space
instead. Here are just a few of the most obvious ones:
It's probably easier to find people experienced in writing user-space code
than kernel code.
It is easier, generally speaking, to develop, debug, and test user-space
applications. Not because kernel is necessarily more complex, but because
kernel development cycle is slower, requiring specialised tools and knowledge.
There are more tools and libraries available in user-space. It's way easier
to just pick an already existing compression library to add compression in
your file system than having it re-implemented in the kernel. Sure, nowadays
the Linux kernel is already very rich in all sorts of library-like subsystems,
but still.
Security, of course! Code in user-space can be isolated, while in the kernel
it would be running in ring0.
And, obviously, porting a file system into a different operating systems is
much easier if it's written in user-space.
And this is where FUSE can help: FUSE is a framework that provides the necessary
infrastructure to make it possible to implement file systems in user-space.
FUSE includes two main components: a kernel-space module, and a user-space
server. The kernel-space fuse module is responsible for getting all the
requests from the virtual file system layer (VFS), and redirect them to
user-space FUSE server. The communication between the kernel and the FUSE
server is done through the /dev/fuse device.
There's also a third optional component: libfuse. This is a user-space
library that makes life easier for developers implementing a file system as it
hides most of the details of the FUSE protocol used to communicate between user-
and kernel-space.
The diagram below helps understanding the interaction between all these
components.
FUSE diagram
As the diagram shows, when an application wants to execute an operation on a
FUSE file system (for example, reading a few bytes from an open file), the
workflow is as follows:
The application executes a system call (e.g., read() to read data from an
open file) and enters kernel space.
The kernel VFS layer routes the operation to the appropriate file system
implementation, the FUSE kernel module in this case. However, if the
read() is done on a file that has been recently accessed, the data may
already be in the page cache. In this case the VFS may serve the request
directly and return the data immediately to the application without calling
into the FUSE module.
FUSE will create a new request to be sent to the user-space server, and
queues it. At this point, the application performing the read() is
blocked, waiting for the operation to complete.
The user-space FUSE file system server gets the new request from /dev/fuse
and starts processing it. This may include, for example, network
communication in the case of a network file system.
Once the request is processed, the user-space FUSE server writes the reply
back into /dev/fuse.
The FUSE kernel module will get that reply, return it to VFS and the
user-space application will finally get its data.
As we can seen, there are a lot of blocking operations and context switches
between user- and kernel- spaces.
What's io_uring
io_uring is an API for performing asynchronous I/O, meant to replace, for
example, the old POSIX API (aio_read(), aio_write(), etc). io_uring can be
used instead of read() and write(), but also for a lot of other I/O
operations, such as fsync, poll. Or even for network-related operations
such as the socket sendmsg() and recvmsg(). An application using this
interface will prepare a set of requests (Submit Queue Entries or SQE), add
them to Submission Queue Ring (SQR), and notify the kernel about these
operations. The kernel will eventually pick these entries, executed them and
add completion entries to the Completion Queue Ring (CQR). It's a simple
producer-consumer model, as shown in the diagram bellow.
io_uring diagram
What's FUSE over io_uring
As mentioned above, the usage of /dev/fuse for communication between the FUSE
server and the kernel is one of the performance bottlenecks when using
user-space file systems. Thus, replacing this mechanism by a block of memory
(ring buffers) shared between the user-space server and the kernel was expected
to result in performance improvements.
The implementation of FUSE over io_uring that was merged into the 6.14 kernel
includes a set of SQR/CQR queues per CPU core and, even if not all the low-level
FUSE operations are available through io_uring1, the performance
improvements are quite visible. Note that, in the future, this design of having
a set of rings per CPU may change and may become customisable. For example, it
may be desirable to have a set of CPUs dedicated for doing I/O on a FUSE file
system, keep other CPUs for other purposes.
Using FUSE over io_uring
One awesome thing about the way this feature was implemented is that there is no
need to add any specific support to the user-space server implementations: as
long as the FUSE server uses libfuse, all the details are totally transparent
to the server.
In order to use this new feature one simply needs to enable it through a fuse
kernel module parameter, for example by doing:
echo 1 > /sys/module/fuse/parameters/enable_uring
And then, when a new FUSE file system is mounted, io_uring will be used. Note
that the above command needs to be executed before the file system is mounted,
otherwise it will keep using the traditional /dev/fuse device.
Unfortunately, as of today, the libfuse library support for this feature
hasn't been released yet. Thus, it is necessary to compile a version of this
library that is still under review. It can be obtained in the maintainer git
tree, branch uring.
After compiling this branch, it's easy to test io_uring using one of the
passthrough file system examples distributed with the library. For example,
one could use the following set of commands to mount a passthrough file system
that uses io_uring:
The graphics below show the results of running some very basic read() and
write() tests, using a simple setup with the passthrough_hp example file
system. The workload used was the standard I/O generator fio.
The graphics on the left are for read() operations, and the ones on the right
for write() operations; on the top the graphics are for buffered I/O and on
the bottom for direct I/O.
All of them show the I/O bandwidth on the Y axis and the number of jobs
(processes doing I/O) on the X axis. The test system used had 8 CPUs, and the
tests used 1, 2, 4 and 8 jobs. Also, for each operation different block sizes
were used. In these graphics only 4k and 32k block sizes are shown.
Reads
Writes
The graphics show clearly that the io_uring performance is better than when
using the FUSE /dev/fuse device. For the reads, the 4k block size io_uring
tests are even better than the 32k tests for the traditional FUSE device. That
doesn't happen in the writes, but io_uring are still better.
Conclusion
To summarise, today is already possible to improve the performance of FUSE file
systems simply by explicitly enabling the io_uring communication between the
kernel and the FUSE server. libfuse still needs to be manually compiled, but
this should change very soon, once this library is released with support for
this new feature. And this proves once again that user-space file systems
are not necessarily "toy" file systems developed by "misguided" people.
Good evening, hackfolk. A quick note this evening to record a waypoint
in my efforts to improve Guile’s memory manager.
So, I got Guile running on top of the
Whippet API. This API can be
implemented by a number of concrete garbage collector implementations.
The implementation backed by the Boehm collector is fine, as expected.
The implementation that uses the bump-pointer-allocation-into-holes
strategy
is less good. The minor reason is heap sizing heuristics; I still get
it wrong about when to grow the heap and when not to do so. But the
major reason is that non-moving Immix collectors appear to have
pathological fragmentation characteristics.
Fragmentation, for our purposes, is memory under the control of the GC
which was free after the previous collection, but which the current cycle failed to use for allocation. I have the feeling
that for the non-moving Immix-family collector implementations,
fragmentation is much higher than for size-segregated freelist-based mark-sweep
collectors. For an allocation of, say, 1024 bytes, the collector might
have to scan over many smaller holes until you find a hole that is big
enough. This wastes free memory. Fragmentation memory is not gone—it
is still available for allocation!—but it won’t be allocatable until
after the current cycle when we visit all holes again. In Immix, fragmentation wastes allocatable memory during a cycle, hastening collection and causing more frequent whole-heap traversals.
The value proposition of Immix is that if there is too much
fragmentation, you can just go into evacuating mode, and probably
improve things. I still buy it. However I don’t think that non-moving
Immix is a winner. I still need to do more science to know for sure. I
need to fix Guile to support the stack-conservative, heap-precise
version of the Immix-family collector which will allow for evacuation.
So that’s where I’m at: a load of gnarly Guile refactors to allow for
precise tracing of the heap. I probably have another couple weeks left until I can run some tests. Fingers crossed; we’ll see!
Last month the Embedded Recipes conference was held in Nice, France.
Igalia was sponsoring the event, and my colleague Martín and myself were attending.
In addition we both delivered a talk to a highly technical and engaged audience.
My presentation, unlike most other talks, was a high-level overview of how Igalia engineers contribute to SteamOS to shape the future of gaming on Linux, through our contracting work with Valve. Having joined the project recently, this was a challenge (the good kind) to me: it allowed me to gain a much better understanding of what all my colleagues who work on SteamOS do, through conversations I had with them when preparing the presentation.
The talk was well received and the feedback I got was overall very positive, and it was followed up by several interesting conversations.
I was apprehensive about the questions from the audience, as most of the work I presented wasn’t mine, and indeed some of them had to remain unanswered.
Martín delivered a lightning talk on how to implement OTA updates with systemd-sysupdate on Yocto-based distributions.
It was also well received, and followed up by conversations in the Yocto workshop that took place the following day.
I found the selection of presentations overall quite interesting and relevant, and there were plenty of opportunities for networking during lunch, coffee breaks that were splendidly supplied with croissants, fruit juice, cheese and coffee, and a dinner at a beach restaurant.
Many thanks to Kevin and all the folks at BayLibre for a top-notch organization in a relaxed and beautiful setting, to fellow speakers for bringing us these talks, and to everyone I talked to in the hallway track for the enriching conversations.
The Web Engines Hackfest 2025 is kicking off next Monday in A Coruña and among
all the interesting talks and
sessions about
different engines, there are a few that can be interesting to people involved
one way or another with WebKitGTK and WPE:
“Multimedia in
WebKit”, by Philippe
Normand (Tuesday 3rd at 12:00 CEST), will focus on the current status and
future plans for the multimedia stack in WebKit.
All talks will be live streamed and a Jitsi Meet link will be available for
those interested in participating remotely. You can find all the details at
webengineshackfest.org.
The release of GStreamer
1.26, last March, delivered
new features, optimization and improvements.
Igalia played its role as long
standing contributor, with 382 commits (194 merge requests) from a total of 2666
of commits merged in this release.This blog post takes a closer look on those contributions.
GstValidate
is a tool to check if elements are behaving as expected.
Added support for HTTP Testing.
Scenario fixes such as reset pipelines on expected errors to avoid
inconsistent states, improved error logging, and async action handling to
prevent busy loops.
GStreamer Base Plugins is a well-groomed and well-maintained collection of
plugins. It also contains helper libraries and base classes useful for writing
elements.
audiorate: respect tolerance property to avoid unnecessary sample
adjustments for minor gaps.
audioconvert: support reordering of unpositioned input channels.
videoconvertscale: improve aspect ratio handling.
glcolorconvert: added I422_10XX, I422_12XX, Y444_10XX, and Y444_16XX
color formats, and fixed caps negotiation for DMABuf.
glvideomixer: handle mouse events.
pbutils: added VVC/H.266 codec support
encodebasebin: parser fixes.
oggdemux: fixed seek to the end of files.
rtp: fixed precision for UNIX timestamp.
sdp: enhanced debugging messages.
parsebin: improved caps negotiation.
decodebin3: added missing locks to prevent race conditions.
GStreamer Bad Plug+ins is a set of plugins that aren’t up to par compared to the
rest. They might be close to being good quality, but they’re missing something,
be it a good code review, some documentation, a set of tests, etc.
dashsink: a lot of improvements and cleanups, such as unit tests, state
and event management.
h266parse: enabled vvc1 and vvi1 stream formats, improved code data
parsing and negotiatios, along with cleanups and fixes.
mpegtsmux and tsdemux: added support for VVC/H.266 codec.
vulkan:
Added compatibility for timeline semaphores and barriers.
Initial support of multiple GPU and dynamic element registering.
Vulkan image buffer pool improvements.
vulkanh264dec: support interlaced streams.
vulkanencoding: rate control and quality level adjustments, update
SPS/PPS, support layered DPBs.
webrtcbin:
Resolved duplicate payload types in SDP offers with RTX and multiple codecs.
Transceivers are now created earlier during negotiation to avoid linkage
issues.
Allow session level in setup attribute in SDP answer.
wpevideosrc:
code cleanups
cached SHM buffers are cleared after caps renegotiation.
handle latency queries and post progress messages on bus.
srtdec: fixes
jpegparse: handle avi1 tag for progressive images
va: improve encoders configuration when properties change in run+time,
specially rate control.
Earlier this month, Alex presented "Improvements to RISC-V vector code
generation in LLVM" at the RISC-V Summit Europe in Paris. This blog post
summarises that talk.
So RISC-V, vectorisation, the complexities of the LLVM toolchain and just 15
minutes to cover it in front of an audience with varying specialisations. I
was a little worried when first scoping this talk but the thing with compiler
optimisations is that the objective is often pretty clear and easy to
understand, even if the implementation can be challenging. I'm going to be
exploiting that heavily in this talk by trying to focus on the high level
objective and problems encountered.
Where are we today in terms of the implementation of optimisation of RISC-V
vector codegen? I'm oversimplifying the state of affairs here, but the list in
the slide above isn't a bad mental model. Basic enablement is done, it's been
validated to the point it's enabled by default, we've had a round of
additional extension implementation, and a large portion of ongoing work is on
performance analysis and tuning. I don't think I'll be surprising any of you
if I say this is a huge task. We're never going to be "finished" in the sense
that there's always more compiler performance tuning to be done, but there's
certainly phases of catching the more obvious cases and then more of a long
tail.
What is the compiler trying to do here? There are multiple metrics, but
typically we're focused primarily on performance of generated code. This isn't
something we do at all costs -- in a general purpose compiler you can't for
instance spend 10hrs optimising a particular input. So we need a lot of
heuristics that help us arrive at a reasonable answer without exhaustively
testing all possibilities.
The kind of considerations for the compiler during compilation includes:
Profitability. If you're transforming your code then for sure you want the
new version to perform better than the old one! Given the complexity of the
transformations from scalar to vector code and costs incurred by moving
values between scalar and vector registers, it can be harder than you might
think to figure out at the right time whether the vector route vs the scalar
route might be better. You're typically estimating the cost of either choice
before you've gone and actually applied a bunch of additional optimisations
and transformations that might further alter the trade-off.
More specific to RISC-V vectors, it's been described before as effectively
being a wider than 32-bit instruction width but with the excess encoded in
control status registers. If you're too naive about it, you risk switching
the vtype CSR more than necessary, adding unwanted overhead.
Spilling is when we load and store values to the stack. Minimising this is a
standard objective for any target, but the lack of callee saved vector
registers in the standard ABI poses a challenge, and this is more subtle but
the fact we don't have immediate offsets for some vector instructions can
put more pressure on scalar register allocation.
Or otherwise just ensuring that we're using the instructions available
whenever we can. One of the questions I had was whether I'm going to be
talking just about autovectorisation, or vector codegen where it's explicit
in the input (e.g. vector datatypes, intrinsics). I'd make the point they're
not fully independent, in fact all these kind of considerations are
inter-related. If the compiler is doing cost modelling that's telling it
vectorisation isn't profitable. Sometimes that's true, sometimes the model
isn't detailed enough, or sometimes it's true for the compiler right now
because it could be doing a better job of choosing instructions. If I solve
the issue of suboptimal instruction selection then it benefits both
autovectorisation (as it's more likely to be profitable, or will be more
profitable) and potentially the more explicit path (as explicit uses of
vectors benefit from the improved lowering).
Just one final point of order I'll say once to avoid repeating myself again
and again. I'm giving a summary of improvements made by all LLVM contributors
across many companies, rather than just those by my colleagues at Igalia.
The intuition behind both this improvement and the one on the next slide is
actually exactly the same. Cast your minds back to 2015 or so when Krste was
presenting the vector extension. Some details have changed, but if you look at
the slides (or any RVV summary since then) you see code examples with simple
minimal loops even for irregularly sized vectors or where the length of a
vector isn't fixed at compile time. The headline is that the compiler now
generates output that looks a lot more like that handwritten code that better
exploits the features of RISC-V vector.
For non-power-of-two vectorisation, I'm talking about the case here where you
have a fixed known-at-compile time length. In LLVM this is handled usually by
what we call the SLP or Superword Level Parallelism
vectorizer. It needed
to be taught to handle non-power-of-two sizes like we support in RVV. Other
SIMD ISAs don't have the notion of vl and so generating non-power-of-two
vector types isn't as easy.
The example I show here has pixels with rgb values. Before it would do a very
narrow two-wide vector operation then handle the one remaining item with
scalar code. Now we directly operate on a 3-element vector.
We are of course using simple code examples for illustration here. If you want
to brighten an image as efficiently as possible sticking the per-pixel
operation in a separate function like this perhaps isn't how you'd do it!
Often when operating on a loop, you have an input of a certain length and you
process it in chunks of some reasonable size. RISC-V vector gives us a lot
more flexibility about doing this. If our input vector isn't an exact multiple
of our vectorization factor ("chunk size") - which is the calculated vector
length used per iteration - we can still process that in RVV using the same
vector code path. While for other architectures, as you see with the old code
has a vector loop, then may branch to a scalar version for the tail for any
remainder elements. Now that's not necessary, LLVM's loop
vectorizer can
handle these cases properly and we get a single vectorised loop body. This
results in performance improvements on benchmarks like x264 where the scalar
tail is executed frequently, and improves code size even in cases where there
is no direct performance impact.
This one is a little bit simpler. It's common for the compiler to synthesise
its own version of memcpy/memset when it sees it can generate a more
specialised version based on information about alignment or size of the
operands. Of course when the vector extension is available the compiler
should be able to use it to implement these operations, and now it can.
This example shows how a small number of instructions expanded inline might be
used to implement memcpy and memcmp. I also note there is a RISC-V vector
specific consideration in favour of inlining operations in this case - as the
standard calling convention doesn't have any callee-saved vector registers,
avoiding the function call may avoid spilling vector registers.
Sometimes of course it's a matter of a new extension letting us do something
we couldn't before. We need to teach the compiler how to select instructions
in that case, and to estimate the cost. Half precision and bf16 floating point
is an interesting example where you introduce a small number of instructions
for the values of that type, but otherwise rely on widening to 32-bit. This is
of course better than falling back to a libcall or scalarising to use Zfh
instruction, but someone needs to be put in the work to convince the compiler
of that!
The slide above has a sampling of other improvements. If you'd like to know
more about the VL optimizer, my colleague's presentation at EuroLLVM earlier
this year is now up on YouTube.
Another fun highlight is
llvm-exegesis, this
is a tool for detecting microarchitectural implementation details via probing,
e.g. latency and throughput of different operations that will help you write a
scheduling model. It now supports RVV which is a bit helpful for the one piece
of RVV 1.0 hardware we have readily available, but should be a lot more
helpful once more hardware reaches the market.
So, it's time to show the numbers. Here I'm looking at execution time for SPEC
CPU 2017 benchmarks (run using LLVM's harness) on at SpacemiT X60 and compiled
with the options mentioned above. As you can see, 12 out of 16 benchmarks
improved by 5% or more, 7 out of 16 by 10% or more. These are meaningful
improvements a bit under 9% geomean when compared to Clang as of March this
year to Clang from 18 months prior.
There's more work going in as we speak, such as the optimisation work done by
my colleague Mikhail and written up on the RISE
blog.
Benchmarking done for that work comparing Clang vs GCC showed today's LLVM is
faster than GCC in 11 of the 16 tested SPEC benchmarks, slower in 3, and about
equal for the other two.
Are we done? Goodness no! But we're making great progress. As I say for all of
these presentations, even if you're not directly contributing compiler
engineering resources I really appreciate anyone able to contribute by
reporting any cases when they compiler their code of interest and don't get
the optimisation expected. The more you can break it down and produce minimised
examples the better, and it means us compiler engineers can spend more time
writing compiler patches rather than doing workload analysis to figure out the
next priority.
Adding all these new optimisations is great, but we want to make sure the
generated code works and continues to work as these new code generation
features are iterated on. It's been really important to have CI coverage for
some of these new features including when they're behind flags and not enabled
by default. Thank you to RISE for supporting my work here, we have a nice
dashboard providing an easy view of just the RISC-V
builders.
Here's some directions of potential future work or areas we're already
looking. Regarding the default scheduling model, Mikhail's recent work on the
Spacemit X60 scheduling model shows how having at least a basic scheduling
model can have a big impact (partly as various code paths are pessimised in
LLVM if you don't at least have something). Other backends like AArch64 pick a
reasonable in-order core design on the basis that scheduling helps a lot for
such designs, and it's not harmful for more aggressive OoO designs.
To underline again, I've walked through progress made by a whole community of
contributors not just Igalia. That includes at least the companies mentioned
above, but more as well. I really see upstream LLVM as a success story for
cross-company collaboration within the RISC-V ecosystem. For sure it could be
better, there are companies doing a lot with RISC-V who aren't doing much with
the compiler they rely on, but a huge amount has been achieved by a
contributor community that spans many RISC-V vendors. If you're working on the
RISC-V backend downstream and looking to participate in the upstream
community, we run biweekly contributor calls (details on the RISC-V category
on LLVM's Discourse
that may be a helpful way to get started.
Update on what happened in WebKit in the week from May 19 to May 26.
This week saw updates on the Android version of WPE, the introduction
of a new mechanism to support memory-mappable buffers which can lead
to better performance, a new gamepad API to WPE, and other improvements.
Cross-Port 🐱
Implemented support for the new 'request-close' command for dialog elements.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Added support for using the GDB JIT API when dynamically generating code in JSC.
Graphics 🖼️
Added support for memory-mappable GPU buffers. This mechanism allows to allocate linear textures that can be used from OpenGL, and memory-mapped into CPU-accessible memory. This allows to update the pixel data directly, bypassing the usual glCopyTexSubImage2D logic that may introduce implicit synchronization / perform staging copies / etc. (driver-dependant).
WPE WebKit 📟
WPE Platform API 🧩
New, modern platform API that supersedes usage of libwpe and WPE backends.
Landed a patch to add a gamepads API to WPE Platform with an optional default implementation using libmanette.
The Linux 6.15 has just been released, bringing a lot of new features:
nova-core, the “base” driver for the new NVIDIA GPU driver, written in Rust. nova project will eventually replace Nouveau driver for all GSP-based GPUs.
RISC-V gained support for some extensions: BFloat16 floating-point, Zaamo, Zalrsc and ZBKB.
The fwctl subsystem has been merged. This new family of drivers acts as a transport layer between userspace and complex firmware. To understand more about its controversies and how it got merged, check out this LWN article.
Support for MacBook touch bars, both as a DRM driver and input source.
Support for Adreno 623 GPU.
As always, I suggest to have a look at the Kernel Newbies summary. Now, let’s have a look at Igalia’s contributions.
DRM wedged events
In 3D graphics APIs such Vulkan and OpenGL, there are some mechanisms that applications can rely to check if the GPU had reset (you can read more about this in the kernel documentation). However, there was no generic mechanism to inform userspace that a GPU reset has happened. This is useful because in some cases the reset affected not only the app involved in the reset, but the whole graphic stack and thus needs some action to recover, like doing a module rebind or even bus reset to recovery the hardware. For this release, we helped to add an userspace event for this, so a daemon or the compositor can listen to it and trigger some recovery measure after the GPU has reset. Read more in the kernel docs.
DRM scheduler work
In the DRM scheduler area, in preparation for the future scheduling improvements, we worked on cleaning up the code base, better separation of the internal and external interfaces, and adding formal interfaces at places where individual drivers had too much knowledge of the scheduler internals.
General GPU/DRM stack
In the wider GPU stack area we optimised the most frequent dma-fence single fence merge operation to avoid memory allocations and array sorting. This should slightly reduce the CPU utilisation with workloads which use the DRM sync objects heavily, such as the modern composited desktops using Vulkan explicit sync.
Some releases ago, we helped to enable async page flips in the atomic DRM uAPI. So far, this feature was only enabled for the primary plane. In this release, we added a mechanism for the driver to decide which plane can perform async flips. We used this to enable overlay planes to do async flips in AMDGPU driver.
We also fixed a bug in the DRM fdinfo common layer which could cause use after free after driver unbind.
Intel Xe driver improvements
On the Intel GPU specific front we worked on adding better Alderlake-P support to the new Intel Xe driver by identifying and adding missing hardware workarounds, fixed the workaround application in general and also made some other smaller improvements.
sched_ext
When developing and optimizing a sched_ext-based scheduler, it is important to understand the interactions between the BPF scheduler and the in-kernel sched_ext core. If there is a mismatch between what the BPF scheduler developer expects and how the sched_ext core actually works, such a mismatch could often be the source of bugs or performance issues.
To address such a problem, we added a mechanism to count and report the internal events of the sched_ext core. This significantly improves the visibility of subtle edge cases, which might easily slip off. So far, eight events have been added, and the events can be monitored through a BPF program, sysfs, and a tracepoint.
A few less bugs
As usual, as part of our work on diverse projects, we keep an eye on automated test results to look for potential security and stability issues in different kernel areas. We’re happy to have contributed to making this release a bit more robust by fixing bugs in memory management, network (SCTP), ext4, suspend/resume and other subsystems.
This is the complete list of Igalia’s contributions for this release:
It was a pleasant surprise how easy it was to switch—from the user’s
point of view, you just pass --with-gc=heap-conservative-parallel-mmc
to Guile’s build (on the wip-whippet branch); when developing I also pass --with-gc-debug, and I
had a couple bugs to fix—but, but, there are still some issues. Today’s
note thinks through the ones related to heap sizing heuristics.
growable heaps
Whippet has three heap sizing
strategies:
fixed, growable, and adaptive
(MemBalancer). The adaptive policy
is the one I would like in the long term; it will grow the heap for processes with a high allocation rate, and shrink when they go
idle. However I won’t really be able to test heap shrinking until I get
precise tracing of heap edges, which will allow me to evacuate sparse
blocks.
So for now, Guile uses the growable policy, which attempts to size the
heap so it is at least as large as the live data size, times some
multiplier. The multiplier currently defaults to 1.75×, but can be set
on the command line via the GUILE_GC_OPTIONS environment variable.
For example to set an initial heap size of 10 megabytes and a 4×
multiplier, you would set
GUILE_GC_OPTIONS=heap-size-multiplier=4,heap-size=10M.
Anyway, I have run into problems! The fundamental issue is
fragmentation. Consider a 10MB growable heap with a 2× multiplier,
consisting of a sequence of 16-byte objects followed by 16-byte holes.
You go to allocate a 32-byte object. This is a small object (8192 bytes
or less), and so it goes in the Nofl space. A Nofl mutator holds on to
a block from the list of sweepable blocks, and will sequentially scan
that block to find holes. However, each hole is only 16 bytes, so we
can’t fit our 32-byte object: we finish with the current block, grab
another one, repeat until no blocks are left and we cause GC. GC runs,
and after collection we have an opportunity to grow the heap: but the
heap size is already twice the live object size, so the heuristics say
we’re all good, no resize needed, leading to the same sweep again,
leading to a livelock.
I actually ran into this case during Guile’s bootstrap, while allocating
a 7072-byte vector. So it’s a thing that needs fixing!
observations
The root of the problem is fragmentation. One way to solve the problem
is to remove fragmentation; using a semi-space collector comprehensively
resolves the issue,
modulo
any block-level fragmentation.
However, let’s say you have to live with fragmentation, for example
because your heap has ambiguous edges that need to be traced conservatively. What can we do?
Raising the heap multiplier is an effective mitigation, as it increases
the average hole size, but for it to be a comprehensive solution in
e.g. the case of 16-byte live objects equally interspersed with holes,
you would need a multiplier of 512× to ensure that the largest 8192-byte
“small” objects will find a hole. I could live with 2× or something,
but 512× is too much.
We could consider changing the heap organization entirely. For example,
most mark-sweep collectors (BDW-GC included) partition the heap into
blocks whose allocations are of the same size, so you might have some
blocks that only hold 16-byte allocations. It is theoretically possible
to run into the same issue, though, if each block only has one live
object, and the necessary multiplier that would “allow” for more empty
blocks to be allocated is of the same order (256× for 4096-byte blocks
each with a single 16-byte allocation, or even 4096× if your blocks are
page-sized and you have 64kB pages).
My conclusion is that practically speaking, if you can’t deal with
fragmentation, then it is impossible to just rely on a heap multiplier
to size your heap. It is certainly an error to live-lock the process,
hoping that some other thread mutates the graph in such a way to free up
a suitable hole. At the same time, if you have configured your heap to
be growable at run-time, it would be bad policy to fail an allocation,
just because you calculated that the heap is big enough already.
It’s a shame, because we lose a mooring on reality: “how big will my
heap get” becomes an unanswerable question because the heap might grow
in response to fragmentation, which is not deterministic if there are
threads around, and so we can’t reliably compare performance between
different configurations. Ah well. If reliability is a goal, I think
one needs to allow for evacuation, one way or another.
for nofl?
In this concrete case, I am still working on a solution. It’s going to
be heuristic, which is a bit of a disappointment, but here we are.
My initial thought has two parts. Firstly, if the heap is growable but
cannot defragment, then we need to reserve some empty blocks after each
collection, even if reserving them would grow the heap beyond the
configured heap size multiplier. In that way we will always be able to
allocate into the Nofl space after a collection, because there will
always be some empty blocks. How many empties? Who knows. Currently
Nofl blocks are 64 kB, and the largest “small object” is 8kB. I’ll
probably try some constant multiplier of the heap size.
The second thought is that searching through the entire heap for a hole
is a silly way for the mutator to spend its time. Immix will reserve a
block for overflow allocation: if a medium-sized allocation (more than
256B and less than 8192B) fails because no hole in the current block is
big enough—note that Immix’s holes have 128B granularity—then the
allocation goes to a dedicated overflow block, which is taken from the
empty block set. This reduces fragmentation (holes which were not used
for allocation because they were too small).
Nofl should probably do the same, but given its finer granularity, it
might be better to sweep over a variable number of blocks, for example
based on the logarithm of the allocation size; one could instead sweep
over clz(min-size)–clz(size) blocks before taking from the empty block list, which would at least bound the
sweeping work of any given allocation.
fin
Welp, just wanted to get this out of my head. So far, my experience
with this Nofl-based heap configuration is mostly colored by live-locks,
and otherwise its implementation of a growable heap sizing policy seems
to be more tight-fisted regarding memory allocation than BDW-GC’s
implementation. I am optimistic though that I will be able to get
precise tracing sometime soon, as measured in development time; the
problem as always is fragmentation, in that I don’t have a hole in my
calendar at the moment. Until then, sweep on Wayne, cons on Garth,
onwards and upwards!
There’s a layout type that web designers have been using for a long time now, and yet can’t be easily done with CSS: “masonry” layout, sometimes called “you know, like Pinterest does it” layout. Masonry sits sort of halfway between flexbox and grid layout, which is a big part of why it’s been so hard to formalize. There are those who think of it as an extension of flexbox, and others who think it’s an extension of grid, and both schools of thought have pretty solid cases.
But then, maybe you don’t actually need to explore the two sides of the debate, because there’s a new proposal in town. It’s currently being called Item Flow (which I can’t stop hearing sung by Eddie Vedder, please send help) and is explained in some detail in a blog post from the WebKit team. The short summary is that it takes the flow and packing capabilities from flex and grid and puts them into their own set of properties, along with some new capabilities.
As an example, here’s a thing you can currently do with flexbox:
Now you might be thinking, okay, this just renames some flex properties to talk about items instead and you also get a shorthand property; big deal. It actually is a big deal, though, because these item-* properties would apply in grid settingsas well. In other words, you would be able to say:
display: grid;
item-flow: wrap column;
Hold up. Item wrapping… in grid?!? Isn’t that just the same as what grid already does? Which is an excellent question, and not one that’s actually settled.
However, let’s invert the wrapping in grid contexts to consider an example given in the WebKit article linked earlier, which is that you could specify a single row of grid items that equally divide up the row’s width to size themselves, like so:
In that case, a row of five items would size each item to be one-fifth the width of the row, whereas a row of three items would have each item be one-third the row’s width. That’s a new thing, and quite interesting to ponder.
The proposal includes the properties item-pack and item-slack, the latter of which makes me grin a little like J.R. “Bob” Dobbs but the former of which I find a lot more interesting. Consider:
This would act with flex items much the way text-wrap: balance acts with words. If you have six flex items of roughly equal size, they’ll balance between two rows to three-and-three rather than five-and-one. Even if your flex items are of very different sizes, item-pack: balance would do always automatically its best to get the row lengths as close to equal as possible, whether that’s two rows, three rows, four rows, or however many rows. Or columns! This works just as well either way.
There are still debates to be had and details to be worked out, but this new direction does feel fairly promising to me. It covers all of the current behaviors that flex and grid flowing already permit, plus it solves some longstanding gripes about each layout approach and while also opening some new doors.
The prime example of a new door is the aforementioned masonry layout. In fact, the previous code example is essentially a true masonry layout (because it resembles the way irregular bricks are laid in a wall). If we wanted that same behavior, only vertically like Pinterest does it, we could try:
display: flex;
item-direction: column; /* could also be `flex-direction` */
item-wrap: wrap; /* could also be `flex-wrap` */
item-pack: balance;
That would be harder to manage, though, since for most writing modes on the web, the width is constrained and the height is not. In other words, to make that work with flexbox, we’d have to set an explicit height. We also wouldn’t be able to nail down the number of columns. Furthermore, that would cause the source order to flow down columns and then jump back to the top of the next column. So, instead, maybe we’d be able to say:
If I’ve read the WebKit article correctly, that would allow Pinterest-style layout with the items actually going across the columns in terms of source order, but being laid out in packed columns (sometimes called “waterfall” layout, which is to say, “masonry” but rotated 90 degrees).
That said, it’s possible I’m wrong in some of the particulars here, and even if I’m not, the proposal is still very much in flux. Even the property names could change, so values and behaviors are definitely up for debate.
As I pondered that last example, the waterfall/Pinterest layout, I thought: isn’t this visual result essentially what multicolumn layout does? Not in terms of source order, since multicolumn elements run down one column before starting again at the top of the next. But that seems an easy enough thing to recreate like so:
That’s a balanced set of three equally wide columns, just like in multicol. I can use gap for the column gaps, so that’s handled. I wouldn’t be able to set up column rules — at least, not right now, though that may be coming thanks to the Edge team’s gap decorations proposal. But what I would be able to do, that I can’t now, is vary the width of my multiple columns. Thus:
Is that useful? I dunno! It’s certainly not a thing we can do in CSS now, though, and if there’s one thing I’ve learned in the past almost three decades, it’s that a lot of great new ideas come out of adding new layout capabilities.
So, if you’ve made it this far, thanks for reading and I strongly encourage you to go read the WebKit team’s post if you haven’t already (it has more detail and a lovely summary matrix near the end) and think about what this could do for you, or what it looks like it might fall short of making possible for you.
As I’ve said, this feels promising to me, as it enables what we thought was a third layout mode (masonry/waterfall) by enriching and extending the layout modes we already have (flex/grid). It also feels like this could eventually lead to a Grand Unified Layout Platform — a GULP, if you will — where we don’t even have to say whether a given layout’s display is flex or grid, but instead specify the exact behaviors we want using various item-* properties to get just the right ratio of flexible and grid-like qualities for a given situation.
…or, maybe, it’s already there. It almost feels like it is, but I haven’t thought about it in enough detail yet to know if there are things it’s missing, and if so, what those might be. All I can say is, my Web-Sense is tingling, so I’m definitely going to be digging more at this to see what might turn up. I’d love to hear from all y’all in the comments about what you think!
In April, many colleagues from Igalia participated in a TC39 meeting organized remotely to discuss proposed features for the JavaScript standard alongside delegates from various other organizations.
Let's delve together into some of the most exciting updates!
In 2020, the Intl.NumberFormat Unified API proposal added a plethora of new features to Intl.NumberFormat, including compact and other non-standard notations. It was planned that Intl.PluralRules would be updated to work with the notation option to make the two complement each other. This normative change achieved this by adding a notation option to the PluralRules constructor.
Given the very small size of this Intl change, it didn't go through the staging process for proposals and was instead directly approved to be merged into the ECMA-402 specification.
Our colleague Philip Chimento presented a regular status update on Temporal, the upcoming proposal for better date and time support in JS.
Firefox is at ~100% conformance with just a handful of open questions. The next most conformant implementation, in the Ladybird browser, dropped from 97% to 96% since February — not because they broke anything, but just because we added more tests for tricky cases in the meantime. GraalJS at 91% and Boa at 85% have been catching up.
Completing the Firefox implementation has raised a few interoperability questions which we plan to solve with the Intl Era and Month Code proposal soon.
Dan Minor of Mozilla reported on a tricky case with the proposed using keyword for certain resources. The feature is essentially completely implemented in SpiderMonkey, but Dan highlighted an ambiguity about using the new keyword in switch statements. The committee agreed on a resolution of the issue suggested by Dan, including those implementers who have already shipped this stage 3 feature.
The JavaScript iterator and async iterator protocols power all modern iteration methods in the language, from for of and for await of to the rest and spread operators, to the modern iterator helpers proposals...
One less-well-known part of these protocols, however, is the optional .throw() and .return() methods, which can be used to influence the iteration itself. In particular, .return() indicates to the iterator that the iteration is finished, so it can perform any cleanup actions. For example, this is called in for of/for await of when the iteration stops early (due to a break, for example).
When using for await of with a sync iterator/iterable, such as an array of promises, each value coming from the sync iterator is awaited. However, a bug was found recently where if one of those promises coming from the sync iterator rejects, the iteration would stop, but the original sync iterator's .return() method would never be called. (Note that in for of with sync iterators, .return() is always called after .next() throws).
In the January TC39 plenary we decided to make it so that such a rejection would close the original sync iterator. In this plenary, we decided that since Array.fromAsync (which is currently stage 3) uses the same underlying spec machinery for this, it also would affect that API.
The Immutable ArrayBuffer proposal allows creating ArrayBuffers in JS from read-only data, and in some cases allows zero-copy optimizations. After advancing to stage 2.7 last time, there is work underway to write conformance tests. The committee considered advancing the proposal to stage 3 conditionally on the tests being reviewed, but decided to defer that to the next meeting.
Champions: Mark S. Miller, Peter Hoddie, Richard Gibson, Jack-Works
The notion of "upserting" a value into an object for a key is a great match for a common use case: is it possible to set a value for a property on an object, but, if the object already has that property, update the value in some way? To use CRUD terminology, it's a fusion of inserting and updating. This proposal is proceeding nicely; it just recently achieved stage 2, and achieved stage 2.7 at this plenary, since it has landed a number of test262 tests. This proposal is being worked on by Dan Minor with assistance from a number of students at the University of Bergen, illustrating a nice industry-academia collaboration.
JavaScript objects can be made non-extensible using Object.preventExtensions: the value of the properties of a non-extensible object can be changed, but you cannot add new properties to it.
"use strict";
let myObj ={x:2,y:3}; Object.preventExtensions(myObj); myObj.x =5;// ok myObj.z =4;// error!
However, this only applies to public properties: you can still install new private fields on the object thanks to the "return it from super() trick".
classAddPrivateFieldextendsfunction(x){return x }{ #foo =2; statichasFoo(obj){return #foo in obj;} }
let myObj ={x:2,y:3}; Object.preventExtension(myObj); AddPrivateField.hasFoo(obj);// false newAddPrivateField(obj); AddPrivateField.hasFoo(obj);// true
This new proposal, which went all the way to Stage 2.7 in a single meeting, attempts to make the new AddPrivateField(obj) throw when myObj is non-extensible.
The V8 team is currently investigating the web compatibility of this change.
Champions: Mark Miller, Shu-yu Guo, Chip Morningstar, Erik Marks
Records and Tuples was a proposal to support composite primitive types, similar to object and arrays, but that would be deeply immutable and with recursive equality. They also had similar syntax as objects and arrays, but prefixed by #:
The proposal reached stage 2 years ago, but then got stuck due to significant performance concerns from browsers:
changing the way === works would risk making every existing === usage a little bit slower
JavaScript developers were expecting === on these values to be fast, but in reality it would have required either a full traversal of the two records/tuples or complex interning mechanisms
Ashley Claymore, working at Bloomberg, presented a new simpler proposal that would solve one of the use cases of Records and Tuples: having Maps and Sets whose keys are composed of multiple values. The proposal introduces composites: some objects that Map and Set would handle specially for that purpose.
const myMap =newMap(); myMap.set(["foo","bar"],3); myMap.has(["foo","bar"]);// false, it's a different array with just the same contents
AsyncContext is a proposal that allows storing state which is local to an async flow of control (roughly the async equivalent of thread-local storage in other languages), which was impossible in browsers until now. We had previously opened a Mozilla standards position issue about AsyncContext, and it came back negative. One of the main issues they had is that AsyncContext has a niche use case: this feature would be mostly used by third-party libraries, especially for telemetry and instrumentation, rather than by most developers. And Mozilla reasoned that making those authors' lives slightly easier was not worth the additional complexity to the web platform.
However, we should have put more focus on the facts that AsyncContext would enable libraries to improve the UX for their users, and that AsyncContext is also incredibly useful in many front-end frameworks. Not having access to AsyncContext leads to confusing and hard-to-debug behavior in some frameworks, and forces other frameworks to transpile all user code. We interviewed the maintainers for a number of frameworks to see their use cases, which you can read here.
Mozilla was also worried about the potential for memory leaks, since in a previous version of this proposal, calling .addEventListener would store the current context (that is, a copy of the value for every single AsyncContext.Variable), which would only be released in the corresponding .removeEventListener call -- which almost never happens. As a response we changed our model so that .addEventListener would not store the context. (You can read more about the memory aspects of the proposal here.)
A related concern is developer complexity, because in a previous model some APIs and events used the "registration context" (for events, the context in which .addEventListener is called) while others used the "dispatch context" (for events, the context that directly caused the event). We explained that in our newer model, we always use the dispatch context, and that this model would match the context you'd get if the API was internally implemented in JS using promises -- but that for most APIs other than events, those two contexts are the same. (You can read more about the web integration of AsyncContext here.)
After the presentation, Mozilla still had concerns about how the web integration might end up being a large amount of work to implement, and it might still not be worth it, even when the use cases were clarified. They pointed out that the frameworks do have use cases for the core of the proposal, but that they don't seem to need the web integration.
In a post Temporal JavaScript, non-Gregorian calendars can be utilized beyond just Internationalization with a much higher level of detail. Some of this work is relatively uncharted and therefore needs standardization. One of these small but highly significant details is the string IDs for era and months for various calendars. This stage 2 update brought the committee up to speed on some of the design directions of the effort and justified the rationale behind certain tradeoffs including favoring human-readable era codes and removing the requirement of them to be globally unique as well as some of the challenges we have faced with standardizing and programmatically implementing Hijri calendars.
Originally created as part of the import defer proposal, deferred re-exports allow, well... deferring re-export declarations.
The goal of the proposal is to reduce the cost of unused export ... from statements, as well as providing a minimum basis for tree-shaking behavior that everybody must implement and can be relied upon.
Now, when users do import { add } from "./my-library.js", my-library/sets.js will not be loaded and executed: the decision whether it should actually be imported or not has been deferred to my-library's user, who decided to only import what was necessary for the add function.
In the AsyncContext proposal, you can't set the value of an AsyncContext.Variable. Instead, you have the .run method, which takes a callback, runs it with the updated state, and restores the previous value before returning. This offers strong encapsulation, making sure that no mutations can be leaked out of the scope. However, this also adds inflexibility in some cases, such as when refactoring a scope inside a function.
The disposable AsyncContext.Variable proposal extends the AsyncContext proposal by adding a way to set a variable without entering a new function scope, which builds on top of the explicit resource management proposal and its using keyword:
const asyncVar =newAsyncContext.Variable();
function*gen(){ // This code with `.run` would need heavy refactoring, // since you can't yield from an inner function scope. using _ = asyncVar.withValue(createSpan()); yieldcomputeResult(); yieldcomputeResult2(); // The scope of `_` ends here, so `asyncVar` is restored // to its previous value. }
One issue with this is that if the return value of .withValue is not used with a using declaration, the context will never be reset at the end of the scope; so when the current function returns, its caller will see an unexpected context (the context inside the function would leak to the outside). The strict enforcement of using proposal (currently stage 1) would prevent this from happening accidentally, but deliberately leaking the context would still be possible by calling Symbol.enter but not Symbol.dispose. (Note that context leaks are not memory leaks.)
The champions of this proposal explored how to deal with context leaks, and whether it's worth it, since preventing them would require changing the internal using machinery and would make composition of disposables non-intuitive. These leaks are not "unsafe" since you can only observe them with access to the same AsyncContext.Variable, but they are unexpected and hard to debug, and the champions do not know of any genuine use case for them.
The committee resolved on advancing this proposal to stage 1, indicating that it is worth spending time on, but the exact semantics and behaviors still need to be decided.
We presented the results of recent discussions in the overlap between the measure and decimal proposals having to do with what we call an Amount: a container for a number (a Decimal, a Number, a BigInt, a digit string) together with precision. The goal is to be able to represent a number that knows how precise it is. The presentation focused on how the notion of an Amount can solve the internationalization needs of the decimal proposal while, at the same time, serving as a building block on which the measure proposal can build by slotting in a unit (or currency). The committee was not quite convinced by this suggestion, but neither did they reject the idea. We have an active biweekly champions call dedicated to the topic of JS numerics, where we will iterate on these ideas and, in all likelihood, present them again to committee at the next TC39 plenary in May at Igalia headquarters in A Coruña. Stay tuned!
Champions: Jesse Alama, Jirka Maršík, Andrew Paprocki
String encoding in programming languages has come a long way since the Olden Times, when anything not 7-bit ASCII was implementation-defined. Now we have Unicode. 32 bits per character is a lot though, so there are various ways to encode Unicode strings that use less space. Common ones include UTF-8 and UTF-16.
You can tell that JavaScript encodes strings as UTF-16 by the fact that string indexing s[0] returns the first 2-byte code unit. Iterators, on the other hand, iterate through Unicode characters ("code points"). Explained in terms of pizza:
>'🍕'[0]// code unit indexing '\ud83c' >'🍕'.length // length in 2-byte code units 2 >[...'🍕'][0]// code point indexing (by using iteration) '🍕' >[...'🍕'].length // length in code points 1
It's currently possible to compare JavaScript strings by code units (the < and > operators and the array sort() method) but there's no facility to compare strings by code points. It requires writing complicated code yourself. This is unfortunate for interoperability with non-JS software such as databases, where comparisons are almost always by code point. Additionally, the problem is unique to UTF-16 encoding: with UTF-8 it doesn't matter if you compare by unit or point, because the results are the same.
This is a completely new proposal and the committee decided to move it to stage 1. There's no proposed API yet, just a consensus to explore the problem space.
Champions: Mathieu Hofman, Mark S. Miller, Christopher Hiller
This proposal discusses a taxonomy of possible errors that can occur when a JavaScript host runs out of memory (OOM) or space (OOS). It generated much discussion about how much can be reasonably expected of a JS host, especially when under such pressure. This question is particularly important for JS engines that are, by design, working with rather limited memory and space, such as embedded devices. There was no request for stage advancement, so the proposal stays at stage 1. A wide variety of options and ways in which to specify JS engine behavior under these extreme conditions were presented, so we can expect the proposal champions to iterate on the feedback they received and come back to plenary with a more refined proposal.
Champions: Mark S. Miller, Peter Hoddie, Zbyszek Tenerowicz, Christopher Hiller
Enums have been a staple of TypeScript for a long time, providing a type that represents a finite domain of named constant values. The reason to propose enums in JavaScript after all this time is that some modes of compilation, such as the "type stripping" mode used by default in Node.js, can't support enums unless they're also part of JS.
enum Numbers { zero =0, one =1, two =2, alsoTwo = two,// self-reference twoAgain = Numbers.two,// also self-reference }
console.log(Numbers.zero);// 0
One notable difference with TS is that all members of the enum must have a provided initializer, since automatic numbering can easily cause accidental breaking changes. Having auto-initializers seems to be highly desirable, though, so some ways to extend the syntax to allow them are being considered.
Update on what happened in WebKit in the week from May 12 to May 19.
This week focused on infrastructure improvements, new releases that
include security fixes, and featured external projects that use the
GTK and WPE ports.
Cross-Port 🐱
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
Fixed
a reference cycle in the mediastreamsrc element, which prevented its disposal.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Added an internal class that will be
used to represent Temporal Duration objects in a way that allows for more
precise calculations. This is not a user-visible change, but will enable future
PRs to advance Temporal support in JSC towards completion.
WPE WebKit 📟
WPE Platform API 🧩
New, modern platform API that supersedes usage of libwpe and WPE backends.
Added
an initial demo application to the GTK4 WPEPlatform implementation.
Releases 📦️
WebKitGTK
2.48.2 and
WPE WebKit 2.48.2 have
been released. These are paired with a security advisory (WSA-2025-0004:
GTK,
WPE), and therefore it is
advised to update.
On top of security fixes, these release also include correctness fixes, and
support for CSS Overscroll
Behaviour
is now enabled by default.
Community & Events 🤝
GNOME Web has
gained a
preferences page that allows toggling WebKit features at run-time. Tech Preview
builds of the browser will show the settings page by default, while in regular
releases it is hidden and may be enabled with the following command:
gsettings set org.gnome.Epiphany.ui webkit-features-page true
This should allow frontend developers to test upcoming features more easily. Note that the settings for WebKit features are not persistent, and they will be reset to their default state on every launch.
Infrastructure 🏗️
Landed an improvement to error
reporting in the script within WebKit that runs test262 JavaScript tests.
The WebKit Test Runner (WKTR) will no longer
crash if invalid UTF-8 sequences
are written to the standard error stream, (e.g. from 3rd party libraries'
debugging options.
Experimentation is ongoing to un-inline String::find(), which saves ~50 KiB
in the resulting binary size worth of repeated implementations of SIMD “find
character in UTF-16” and “find character in UTF-32” algorithms. Notably, the
algorithm for “find character in ASCII string” was not even part of the
inlining.
Added the LLVM
repository to the
WebKit container SDK. Now it is possible to easily install Clang 20.x with
wkdev-setup-default-clang --version=20.
Figured out that a performance bug related to jump threading optimization in
Clang 18 resulted in a bottleneck adding up to five minutes of build time in
the container SDK. This may be fixed by updating to Clang 20.x.
This week, I reviewed the last available version of the Linux KMS Color
API.
Specifically, I explored the proposed API by Harry Wentland and Alex Hung
(AMD), their implementation for the AMD display driver and tracked the parallel
efforts of Uma Shankar and Chaitanya Kumar Borah
(Intel)
in bringing this plane color management to life. With this API in place,
compositors will be able to provide better HDR support and advanced color
management for Linux users.
To get a hands-on feel for the API’s potential, I developed a fork of
drm_info compatible with the new color properties. This allowed me to
visualize the display hardware color management capabilities being exposed. If
you’re curious and want to peek behind the curtain, you can find my exploratory
work on the
drm_info/kms_color branch.
The README there will guide you through the simple compilation and installation
process.
Note: You will need to update libdrm to match the proposed API. You can find
an updated version in my personal repository
here. To avoid
potential conflicts with your official libdrm installation, you can compile
and install it in a local directory. Then, use the following command: export
LD_LIBRARY_PATH="/usr/local/lib/"
In this post, I invite you to familiarize yourself with the new API that is
about to be released. You can start doing as I did below: just deploy a custom
kernel with the necessary patches and visualize the interface with the help of
drm_info. Or, better yet, if you are a userspace developer, you can start
developing user cases by experimenting with it.
The more eyes the better.
KMS Color API on AMD
The great news is that AMD’s driver implementation for plane color operations
is being developed right alongside their Linux KMS Color API proposal, so it’s
easy to apply to your kernel branch and check it out. You can find details of
their progress in
the AMD’s series.
I just needed to compile a custom kernel with this series applied,
intentionally leaving out the AMD_PRIVATE_COLOR flag. The
AMD_PRIVATE_COLOR flag guards driver-specific color plane properties, which
experimentally expose hardware capabilities while we don’t have the generic KMS
plane color management interface available.
If you don’t know or don’t remember the details of AMD driver specific color
properties, you can learn more about this work in my blog posts
[1][2][3].
As driver-specific color properties and KMS colorops are redundant, the driver
only advertises one of them, as you can see in
AMD workaround patch 24.
So, with the custom kernel image ready, I installed it on a system powered by
AMD DCN3 hardware (i.e. my Steam Deck). Using
my custom drm_info,
I could clearly see the Plane Color Pipeline with eight color operations as
below:
Note that Gamescope is currently using
AMD driver-specific color properties
implemented by me, Autumn Ashton and Harry Wentland. It doesn’t use this KMS
Color API, and therefore COLOR_PIPELINE is set to Bypass. Once the API is
accepted upstream, all users of the driver-specific API (including Gamescope)
should switch to the KMS generic API, as this will be the official plane color
management interface of the Linux kernel.
KMS Color API on Intel
On the Intel side, the driver implementation available upstream was built upon
an earlier iteration of the API. This meant I had to apply a few tweaks to
bring it in line with the latest specifications. You can explore their latest
work
here.
For a more simplified handling, combining the V9 of the Linux Color API,
Intel’s contributions, and my necessary adjustments, check out
my dedicated branch.
I then compiled a kernel from this integrated branch and deployed it on a
system featuring Intel TigerLake GT2 graphics. Running
my custom drm_info
revealed a Plane Color Pipeline with three color operations as follows:
Observe that Intel’s approach introduces additional properties like “HW_CAPS”
at the color operation level, along with two new color operation types: 1D LUT
with Multiple Segments and 3x3 Matrix. It’s important to remember that this
implementation is based on an earlier stage of the KMS Color API and is
awaiting review.
A Shout-Out to Those Who Made This Happen
I’m impressed by the solid implementation and clear direction of the V9 of the
KMS Color API. It aligns with the many insightful discussions we’ve had over
the past years. A huge thank you to Harry Wentland and Alex Hung for their
dedication in bringing this to fruition!
Beyond their efforts, I deeply appreciate Uma and Chaitanya’s commitment to
updating Intel’s driver implementation to align with the freshest version of
the KMS Color API. The collaborative spirit of the AMD and Intel developers in
sharing their color pipeline work upstream is invaluable. We’re now gaining a
much clearer picture of the color capabilities embedded in modern display
hardware, all thanks to their hard work, comprehensive documentation, and
engaging discussions.
Finally, thanks all the userspace developers, color science experts, and kernel
developers from various vendors who actively participate in the upstream
discussions, meetings, workshops, each iteration of this API and the crucial
code review process. I’m happy to be part of the final stages of this long
kernel journey, but I know that when it comes to colors, one step is completed
for new challenges to be unlocked.
Looking forward to meeting you in this year Linux Display Next hackfest,
organized by AMD in Toronto, to further discuss HDR, advanced color management,
and other display trends.
In this tutorial I’m using a Raspberry Pi 5 with a
Camera Module 3. Be careful to use the
right cable as the default white cable shipped with the camera is
for older models of the Raspberry Pi.
In order to not have to switch keyboard, mouse, screen, any cables between the device and the development machine, the
idea is to do the whole development remotely. Obviously, you can also follow the whole tutorial by developping directly
on the Raspberry Pi itself as, once configured, local or remote development is totally transparent.
In my own configuration I only have the Raspberry Pi connected to its power cable and to my local Wifi network.
I’m using Visual Studio Code with the
Remote-SSH extension on the
development machine. In reality the device may be located anywhere in the world as Visual Studio Code is using a SSH
tunnel to manage the remote connection in a secure way.
Basically, once the Raspberry Pi OS installed and the device connected to the
network, you can install the needed development tools (clang or gcc, git, meson, ninja, etc…) and that’s all.
Everything else is done from the development machine where you will install Visual Studio Code and the Remote-SSH
extension. The first time the IDE is connecting to the device through SSH, it will automatically install the tools
required. The detailed installation process is described here.
Once the IDE is connected to the device you can chose which extensions to install locally on the device (like the
C/C++ or
Meson extensions).
Some useful tricks:
Append your public SSH key content (situated by default in ~/.ssh/id_rsa.pub) to the device
~/.ssh/authorized_keys file. It will allow you to connect to the device through ssh without having to enter each
time a password.
Configure your ssh client (in the ~/.ssh/config file) to forward the ssh agent. It will allow to use securely your
local ssh keys to access remote git repositories from the remote device. A typical configuration block would be
something like:
Host berry [the friendly name that will appear in Visual Studio Code]
HostName berry.local [the device hostname or IP address]
User cam [the username used to access the device with ssh]
ForwardAgent yes
With those simple tricks, just executing ssh berry is enough to connect to the device without any password and then
you can access any git repository locally just like if you were on the development machine itself.
You should also change, in the Meson extension configuration in Visual Studio Code, the build directory name and
replace the default builddir by just build because if you are not using
IntelliSense but another extension like
clangd, it will not find
the compile_commands.json file automatically. To update it directly, add this entry to the
~/.config/Code/User/settings.json file:
And the basic main.cpp file with the libcamera initialization code:
#include<libcamera/libcamera.h>usingnamespace libcamera;intmain(){// Initialize the camera manager.auto camManager = std::make_unique<CameraManager>();
camManager->start();return0;}
You can configure and build the project by calling:
meson setup build
ninja -C build
or by using the tools integrated into Visual Studio Code through the Meson extension.
In order to debug the executable inside the IDE, add a .vscode/launch.json file with this content:
{"version":"0.2.0","configurations":[{"name":"Debug","type":"cppdbg","request":"launch","program":"${workspaceFolder}/build/cam-and-berry","cwd":"${workspaceFolder}","stopAtEntry":false,"externalConsole":false,"MIMode":"gdb","preLaunchTask":"Meson: Build all targets"}]}
Now, just pressing F5 will build the project and start the debug session on the device while being driven remotely from
the development machine.
If everything has worked well so far, you should see the libcamera logs on stderr, something like:
[5:10:53.005657356][4366] ERROR IPAModule ipa_module.cpp:171 Symbol ipaModuleInfo not found
[5:10:53.005916466][4366] ERROR IPAModule ipa_module.cpp:291 v4l2-compat.so: IPA module has no valid info
[5:10:53.005942225][4366] INFO Camera camera_manager.cpp:327 libcamera v0.4.0+53-29156679
[5:10:53.013988595][4371] INFO RPI pisp.cpp:720 libpisp version v1.1.0 e7974a156008 27-01-2025 (21:50:51)[5:10:53.035006731][4371] INFO RPI pisp.cpp:1179 Registered camera /base/axi/pcie@120000/rp1/i2c@88000/imx708@1a to CFE device /dev/media0 and ISP device /dev/media1 using PiSP variant BCM2712_D0
You can disable those logs by adding this line at the beginning of the main function:
While running (after calling start()) the
libcamera::CameraManager initializes and then
maintains up-to-date a vector of libcamera::Camera
instances each time a physical camera is connected to or removed from the system. In our case we can consider that the
Camera Module 3 will always be present as it is connected to the Raspberry internal connector.
We can list the available cameras at any moment by calling:
...intmain(){...// List camerasfor(constauto& camera : camManager->cameras()){
std::cout <<"Camera found: "<< camera->id()<< std::endl;}return0;}
This should give an output like:
Camera found: /base/axi/pcie@120000/rp1/i2c@88000/imx708@1a
Each retrieved camera has a list of specific properties and controls (which can be different for every model of
camera). This information can be listed using the camera properties() and controls() getters.
The idMap() getter in the libcamera::ControlList
class returns a map associating each property ID to a property description defined in a
libcamera::ControlId instance. It allows to retrieve
the property name and global caracteristics.
Using this information we can now have a complete description of the camera properties, available controls and their
possible values:
We are now going to see how we can extract frames from the camera. The camera is not producing frames by itself, the
extraction process works on demand: you first need to send a request to the camera to ask for a new frame.
The libcamera library provides a queue to process all those requests. So, basically, you need to create some requests
and push them to this queue. When the camera is ready to take an image, it will pop out the next request from the queue
and fill its associated buffer with the image content. Once the image is ready, the camera sends a signal to the
application to inform that the request has been completed.
If you want to take a simple photo you only need to send one request, but if you want to display or stream some live
video you will need to recycle and re-queue the requests once the corresponding frame has been processed. In the
following code this is what we are going to do as it will be easy to adapt the code to only take one photo.
flowchart TB
A(Acquire camera) --> B(Choose configuration)
B --> C(Allocate buffers and requests)
C --> D(Start camera)
D --> E
subgraph L [Frames extraction loop]
E(Push request) -->|Frame produced| F(("Request completed
callback"))
F --> G(Process frame)
G --> E
end
L --> H(Stop camera)
H --> I(Free buffers and requests)
I --> J(Release camera)
In all cases, there are some steps to follow before sending requests to the camera.
Let’s consider that we have a camera available and we selected it during the former cameras listing. Our selected
camera is called: selectedCamera and it’s a std::shared_ptr<Camera>.
We just have to call: selectedCamera->acquire(); to get an exclusive access to this camera. When we have finished
with it, we can release it by calling selectedCamera->release();.
Once the camera acquired for an exclusive access, we need to configure it. In particular, we need to choose the frames
resolution and pixel format. This is done by creating a camera configuration that will be tweaked, validated and
applied to the camera.
// Lock the selected camera and choose a configuration for video display.
selectedCamera->acquire();auto camConfig = selectedCamera->generateConfiguration({StreamRole::Viewfinder});if(camConfig->empty()){
std::cerr <<"No suitable configuration found for the selected camera"<< std::endl;return-2;}
The libcamera::StreamRole
allows to pre-configure the returned stream configurations depending on the intended usage: taking photos (in raw mode
or not), doing some video capture for streaming or recording (may provide encoded streams if the camera is able to do
it) or doing some video capture for local display.
It returns the default camera configurations for each stream role required.
The default configuration returned may be tweaked with user values. Once modified the configuration must be validated.
The camera may refuse those changes or adjust them to fit the device limits. Once validated, the configuration is
applied to the selected camera.
auto& streamConfig = camConfig->at(0);
std::cout <<"Default camera configuration is: "<< streamConfig.toString()<< std::endl;
streamConfig.size.width =1920;
streamConfig.size.height =1080;
streamConfig.pixelFormat = formats::RGB888;if(camConfig->validate()== CameraConfiguration::Invalid){
std::cerr <<"Invalid camera configuration"<< std::endl;return-3;}
std::cout <<"Targeted camera configuration is: "<< streamConfig.toString()<< std::endl;if(selectedCamera->configure(camConfig.get())!=0){
std::cerr <<"Failed to update the camera configuration"<< std::endl;return-4;}
std::cout <<"Camera configured successfully"<< std::endl;
Allocate the buffers and requests for frames extraction #
The memory for the frames buffers and requests is held by the user. Indeed, the frame content itself is allocated
through DMA buffers for which the
libcamera::FrameBuffer instance is holding the
file descriptors.
The frames buffers are allocated through a
libcamera::FrameBufferAllocator instance.
When this instance is deleted, all buffers in the internal pool are also deleted, including the associated DMA buffers.
So, the lifetime of the FrameBufferAllocator instance must be longer than the lifetime of all the requests associated
with buffers from its internal pool.
The same FrameBufferAllocator instance is used to allocate buffers pools for the different streams from the same
camera. In our case we are only using a single stream and so we will do the allocation only for this stream.
// Allocate the buffers pool used to fetch frames from the camera.
Stream* stream = streamConfig.stream();auto frameAllocator = std::make_unique<FrameBufferAllocator>(selectedCamera);if(frameAllocator->allocate(stream)<0){
std::cerr <<"Failed to allocate buffers for the selected camera stream"<< std::endl;return-5;}auto& buffersPool = frameAllocator->buffers(stream);
std::cout <<"Camera stream has a pool of "<< buffersPool.size()<<" buffers"<< std::endl;
Once we have the frames buffers allocated we can create the corresponding requests and associate each buffer with a
request. So when the camera receives the request it will fill the associated frame buffer with the next image content.
// Create the requests used to fetch the actual camera frames.
std::vector<std::unique_ptr<Request>> requests;for(auto& buffer : buffersPool){auto request = selectedCamera->createRequest();if(!request){
std::cerr <<"Failed to create a frame request for the selected camera"<< std::endl;return-6;}if(request->addBuffer(stream, buffer.get())!=0){
std::cerr <<"Failed to add a buffer to the frame request"<< std::endl;return-7;}
requests.push_back(std::move(request));}
If the camera supports multistream, additional buffers can be added to a single request (using
libcamera::Request::addBuffer)
to capture frames for the other streams. However, only one buffer per stream is allowed in the same request.
Now that we have a pool of requests, each one with its associated frame buffer, we can send them to the camera for
processing. Each time the camera has finished with a request, by filling the associated buffer with the actual image,
it calls a requestCompleted callback and then continues with the next request in the queue.
When we receive the requestCompleted signal, we can extract the image content from the request buffer and process it.
Once the image processing is finished, we recycle the buffer and push again the request in the queue for the next
frames. To take a single photo we would only need one buffer and one request, and we would queue this request only once.
// Connect the requests execution callback, it is called each time a frame// has been produced by the camera.
selectedCamera->requestCompleted.connect(selectedCamera.get(),[&selectedCamera](Request* request){if(request->status()== Request::RequestCancelled){return;}// We can directly take the first request buffer as we are managing// only one stream. In case of multiple streams, we should iterate// over the BufferMap entries or access the buffer by stream pointer.auto buffer = request->buffers().begin()->second;auto& metadata = buffer->metadata();if(metadata.status == FrameMetadata::FrameSuccess){// As we are using a RGB888 color format we have only one plane, but// in case of using a multiplanes color format (like YUV420) we// should iterate over all the planes.
std::cout <<"Frame #"<< std::setw(2)<< std::setfill('0')<< metadata.sequence
<<": time="<< metadata.timestamp <<"ns, size="<< metadata.planes().begin()->bytesused
<<", fd="<< buffer->planes().front().fd.get()<< std::endl;}else{
std::cerr <<"Invalid frame received"<< std::endl;}// Reuse the request buffer and re-queue the request.
request->reuse(Request::ReuseBuffers);
selectedCamera->queueRequest(request);});
Before queueing the first request we need to start the camera and we must stop it when we’ve finished with the frames
extraction. The lifetime of all the requests pushed to the camera must be longer than this start/stop loop. Once the
camera is stopped, we can delete the corresponding requests as they will not be used anymore.
This implies that the FrameBufferAllocator instance must also outlive this same start/stop loop. If you try to delete
the requests vector or the frameAllocator instance before stopping the camera, you will naturally trigger a
segmentation fault.
// Start the camera streaming loop and run it for a few seconds.
selectedCamera->start();for(constauto& request : requests){
selectedCamera->queueRequest(request.get());}
std::this_thread::sleep_for(1500ms);
selectedCamera->stop();
At the end we clean up the resources. Here it is not really needed as the destructors will do automatically the job.
But if you were building a more complex architecture and you need to explicitly free up the resources, that would be
the order to follow.
With the current code the only important point here is to explicitly stop the camera before getting out of the main
function (and to implicitly trigger the destructors calls), else the frameAllocator instance will be destroyed while
the camera is still processing the associated requests, which will lead to a segmentation fault.
// Cleanup the resources. In fact those resources are automatically released// when the corresponding destructors are called. The only compulsory call// to make is selectedCamera->stop() as the camera streaming loop MUST be// stopped before releasing the associated buffers pool.
frameAllocator.reset();
selectedCamera->release();
selectedCamera.reset();
camManager->stop();
If everything has worked well so far, you should see the following output:
In this part, we are going to display the extracted frames using a small OpenGL ES application. This application will
show a rotating cube with a metallic aspect displaying, on each face, the live video stream from the Raspberry Pi 5
camera with an orange/red shade, like in the following video:
For this, we need a little bit more code to initialize the window, the OpenGL context and manage the drawing. The full
code is available at the code repository or
you can download it here.
We are using the GLFW library to manage the
EGL and
OpenGL ES contexts and the GLM
library to manage the 3D vectors and matrices. Those libraries are included as Meson wraps in the subprojects folder.
So, just like with the previous code, to build the project you only need to execute:
meson setup build
ninja -C build
All the 3D rendering part is out of the scope of this tutorial and the corresponding classes have been grouped in the
src/rendering subfolder to help focussing on the Camera and CameraTexture classes. If you are also interested in
3D rendering you can find a lot of interesting material on the Web and, in particular,
Anton’s OpenGL 4 Tutorials or Learn OpenGL.
The Camera class is basically a wrapper of the code explained in the previous parts. In this case we are configuring
the camera to use a pixel format aligned on 32 bits (XRGB8888) to be compatible with the hardware accelerated
rendering.
// We need to choose a pixel format with a stride aligned on 32 bits to be// compatible with the GLES renderer. We only need 2 buffers, while one// buffer is used by the GLES renderer, the other one is filled by the// camera next frame and then both buffers are swapped.
streamConfig.size.width = captureWidth;
streamConfig.size.height = captureHeight;
streamConfig.pixelFormat = libcamera::formats::XRGB8888;
streamConfig.bufferCount =2;
We are also using 2 buffers as one buffer will be rendered on screen while the other buffer will receive the next
camera frame, and then we’ll switch both buffers. We already know that when the
requestCompleted
signal is triggered, the corresponding buffer has finished being written with the next camera frame. This is our
synchronization point to send this buffer to the rendering.
On the rendering side, we know that when the OpenGL buffers are swapped, the displayed image has been fully rendered.
This is our synchronization point to recycle the buffer back the to camera rendering loop.
A specific wrapping class: Camera::Frame is used to exchange those buffers between the camera and the renderer. It is
passed through a std::unique_ptr to ensure an exclusive access from the camera or the renderer. When the instance is
destroyed, it automatically recycles the underlying buffer to make it available for the next camera frame.
When Camera::startCapturing is called, the camera starts producing frames continuously (like in the code from the
previous parts). Each new frame replaces the previous one which is automatically recycled during its destruction:
voidCamera::onRequestCompleted(libcamera::Request* request){if(request->status()== libcamera::Request::RequestCancelled){return;}// We can directly take the first request buffer as we are managing// only one stream. In case of multiple streams, we should iterate// over the BufferMap entries or access the buffer by stream pointer.auto buffer = request->buffers().begin()->second;if(buffer->metadata().status == libcamera::FrameMetadata::FrameSuccess){// As we are using a XRGB8888 color format we have only one plane, but// in case of using a multiplanes color format (like YUV420) we// should iterate over all the planes.
std::unique_ptr<Frame>frame(newFrame(this, request, buffer->cookie()));
std::lock_guard<std::mutex>lock(m_nextFrameMutex);
m_nextFrame = std::move(frame);}else{// Reuse the request buffer and re-queue the request.
request->reuse(libcamera::Request::ReuseBuffers);
m_selectedCamera->queueRequest(request);}}
Camera::Frame::~Frame(){auto camera = m_camera.lock();if(camera && m_request){
m_request->reuse(libcamera::Request::ReuseBuffers);
camera->m_selectedCamera->queueRequest(m_request);}}
At any moment the renderer can fetch this frame to render it:
voidonRender(double time)noexceptoverride{if(m_camera){// We are fetching the next camera produced frame that is ready to// be drawn. If there is no new frame available, we are just// keeping on drawing the same frame.auto cameraFrame = m_camera->getNextFrame();if(cameraFrame){// We need to keep a reference to the current drawn frame in// order to not have the Camera class recycle the underlying// dma-buf while the GLES renderer is still using it for// drawing. This is the Camera::Frame destructor which ensures// proper synchronization. When reaching this point, the// previous m_currentCameraFrame has been fully drawn (the GLES// buffers swap has just occurred on the previous onRender// call), when the unique_ptr is replaced the previous// Camera::Frame is destroyed which triggers the recycling of// its FrameBuffer (for the next camera frame capture), while// the new frame is locked for drawing until it is itself// replaced.
m_currentCameraFrame = std::move(cameraFrame);// We can directly fetch and bind the corresponding GLES// texture from the FrameBuffer cookie.auto textureIndex = m_currentCameraFrame->getCookie();
m_textures[textureIndex]->bind();// The texture mix value is only used to reuse the same shader// without and with a camera frame. Now that we have a frame to// draw we can show it.
m_shader->setCameraTextureMix(1.0f);}}glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glm::mat4 modelMatrix =
glm::rotate(glm::mat4(1.0f),1.5f*static_cast<float>(time), glm::vec3(0.8f,0.5f,0.4f));
m_shader->setModelMatrix(modelMatrix);
m_cube->draw();}
As we have only 2 buffers and the access to each buffer is exclusive, the camera and renderer speeds are going to
adjust each other. The underlying frame buffer is only recycled once destroyed, which only happens when replaced by the
next available buffer.
N.B. The Camera::onRequestCompleted callback is called from a libcamera capturing thread while the
AppRenderer::onRender is called on the application main thread. The call to
libcamera::Camera::queueRequest
is thread-safe, but the access to the std::unique_ptr must be protected by a mutex to be passed to the render
thread.
// Create an EGLImage from the camera FrameBuffer.// In our case we are using a packed color format (XRGB8888), so we// only need the first buffer plane. In case of using a multiplanar color// format (like YUV420 for example), we would need to iterate over all the// color planes in the buffer and fill the EGL_DMA_BUF_PLANE[i]_FD_EXT,// EGL_DMA_BUF_PLANE[i]_OFFSET_EXT and EGL_DMA_BUF_PLANE[i]_PITCH_EXT for// each plane.constauto& plane = buffer.planes().front();const EGLAttrib attrs[]={EGL_WIDTH,
streamConfiguration.size.width,
EGL_HEIGHT,
streamConfiguration.size.height,
EGL_LINUX_DRM_FOURCC_EXT,
streamConfiguration.pixelFormat.fourcc(),
EGL_DMA_BUF_PLANE0_FD_EXT,
plane.fd.get(),
EGL_DMA_BUF_PLANE0_OFFSET_EXT,(plane.offset != libcamera::FrameBuffer::Plane::kInvalidOffset)? plane.offset :0,
EGL_DMA_BUF_PLANE0_PITCH_EXT,
streamConfiguration.stride,
EGL_NONE};
EGLImage eglImage =eglCreateImage(eglDisplay, EGL_NO_CONTEXT, EGL_LINUX_DMA_BUF_EXT,nullptr, attrs);if(!eglImage){returnnullptr;}
N.B. It is important to use a pixel format compatible with the rendering device, else the eglCreateImage
function will fail with eglGetError()
returning EGL_BAD_MATCH.
Then, the EGLImage can be attached to an external OpenGL ES texture using the
OES_EGL_image_external OpenGL
extension:
// Create the GLES texture and attach the EGLImage to it.glGenTextures(1,&texture->m_texture);glBindTexture(GL_TEXTURE_EXTERNAL_OES, texture->m_texture);glTexParameteri(GL_TEXTURE_EXTERNAL_OES, GL_TEXTURE_MIN_FILTER, GL_LINEAR);glTexParameteri(GL_TEXTURE_EXTERNAL_OES, GL_TEXTURE_MAG_FILTER, GL_LINEAR);glTexParameteri(GL_TEXTURE_EXTERNAL_OES, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);glTexParameteri(GL_TEXTURE_EXTERNAL_OES, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);glEGLImageTargetTexture2DOES(GL_TEXTURE_EXTERNAL_OES, eglImage);glBindTexture(GL_TEXTURE_EXTERNAL_OES,0);// Now that the EGLImage is attached to the texture, we can destroy it. The// underlying dma-buf will be released when the texture is deleted.eglDestroyImage(eglDisplay, eglImage);
The corresponding texture can be used like any other kind of texture by binding it to the GL_TEXTURE_EXTERNAL_OES
target. Still, the shader will need to use the same extension and a specific sampler to use this external texture
target:
Although the dma-buf is wrapped by two layers (EGLImage and Texture), its content is never copied or transferred to the
system CPU memory (RAM). This is the same memory space, allocated in a dedicated hardware memory, that is used to
receive the camera frame content and display it on screen, allowing the kernel to optimize the corresponding resources.
The libcamera library is allocating the dma-bufs needed to store the captured frames content when calling
libcamera::FrameBufferAllocator:allocate.
So, we can create the corresponding external textures right after the Camera instance creation:
m_camera =Camera::create(m_width, m_height);if(m_camera){// Create one texture per available camera buffer.for(constauto& request : m_camera->getRequests()){// We know that we are only using one stream and one buffer per// request. If we were using multiple streams at once, we// should iterate on the request BufferMap.auto[stream, buffer]=*request->buffers().begin();auto texture =CameraTexture::create(eglDisplay, stream->configuration(),*buffer);if(!texture){
std::cerr <<"Failed to create a camera texture"<< std::endl;
m_textures.clear();
m_camera.reset();
m_shader.reset();
m_cube.reset();returnfalse;}// We are using the associated buffer cookie to store the// corresponding texture index in the internal vector. This way// it will be easy to fetch the right texture when a frame// buffer is ready to be drawn.
m_textures.push_back(std::move(texture));
buffer->setCookie(m_textures.size()-1);}
m_camera->startCapturing();}
We’re happy to have released gst-dots-viewer, a new development tool that makes it easier to visualize and debug GStreamer pipelines. This tool, included in GStreamer 1.26, provides a web-based interface for viewing pipeline graphs in real-time as your application runs and allows to easily request all pipelines to be dumped at any time.
What is gst-dots-viewer?
gst-dots-viewer is a server application that monitors a directory for .dot files generated by GStreamer’s pipeline visualization system and displays them in your web browser. It automatically updates the visualization whenever new .dot files are created, making it simpler to debug complex applications and understand the evolution of the pipelines at runtime.
Key Features
Real-time Updates: Watch your pipelines evolve as your application runs
Interactive Visualization:
Click nodes to highlight pipeline elements
Use Shift-Ctrl-scroll or w/s keys to zoom
Drag-scroll support for easy navigation
Easily deployable in cloud based environments
How to Use It
Start the viewer server:
gst-dots-viewer
Open your browser at http://localhost:3000
Enable the dots tracer in your GStreamer application:
GST_TRACERS=dots your-gstreamer-application
The web page will automatically update whenever new pipeline are dumped, and you will be able to dump all pipelines from the web page.
New Dots Tracer
As part of this release, we’ve also introduced a new dots tracer that replaces the previous manual approach to specify where to dump pipelines. The tracer can be activated simply by setting the GST_TRACERS=dots environment variable.
Interactive Pipeline Dumps
The dots tracer integrates with the pipeline-snapshot tracer to provide real-time pipeline visualization control. Through a WebSocket connection, the web interface allows you to trigger pipeline dumps. This means you can dump pipelines exactly when you need them during debugging or development, from your browser.
Future Improvements
We plan on adding more feature and have this list of possibilities:
Additional interactive features in the web interface
Enhanced visualization options
Integration with more GStreamer tracers to provide comprehensive debugging information. For example, we could integrate the newly released memory-tracer and queue-level tracers so to plot graphs about memory usage at any time.
This could transform gst-dots-viewer into a more complete debugging and monitoring dashboard for GStreamer applications.
Hey all, just a lab notebook entry today. I’ve been working on the
Whippet GC library for about three
years now, learning a lot on the way. The goal has always been to
replace Guile’s use of the Boehm-Demers-Weiser
collector
with something more modern and maintainable. Last year I finally got to
the point that I felt Whippet was
feature-complete,
and taking into account the old adage about long arses and brief videos,
I think that wasn’t too far off. I carved out some time this spring and for the
last month have been integrating Whippet into Guile in anger, on the
wip-whippet
branch.
the haps
Well, today I removed the last direct usage of the BDW collector’s API
by Guile! Instead, Guile uses Whippet’s API any time it needs to
allocate an object, add or remove a thread from the active set, identify
the set of roots for a collection, and so on. Most tracing is still
conservative, but this will move to be more precise over time. I
haven’t had the temerity to actually try one of the Nofl-based
collectors yet, but that will come soon.
Code-wise, the initial import of Whippet added some 18K lines to Guile’s
repository, as counted by git diff --stat, which includes
documentation and other files. There was an unspeakable amount of autotomfoolery to get Whippet in Guile’s ancient build system. Changes to Whippet during the course of
integration added another 500 lines or so. Integration of Whippet
removed around 3K lines of C from Guile. It’s not a pure experiment, as
my branch is also a major version bump and so has the freedom to
refactor and simplify some things.
Things are better but not perfect. Notably, I switched to build weak
hash tables in terms of buckets and chains where the links are
ephemerons, which give me concurrent lock-free reads and writes but not
resizable tables. I would like to somehow resize these tables in
response to GC, but haven’t wired it up yet.
Accessibility in the free and open source world is somewhat of a sensitive topic.
Given the principles of free software, one would think it would be the best possible place to advocate for accessibility. After all, there’s a collection of ideologically motivated individuals trying to craft desktops to themselves and other fellow humans. And yet, when you look at the current state of accessibility on the Linux desktop, you couldn’t possibly call it good, not even sufficient.
It’s a tough situation that’s forcing people who need assistive technologies out of these spaces.
I think accessibility on the Linux desktop is in a particularly difficult position due to a combination of poor incentives and historical factors:
The dysfunctional state of accessibility on Linux makes it so that the people who need it the most cannot even contribute to it.
There is very little financial incentive for companies to invest in accessibility technologies. Often, and historically, companies invest just enough to tick some boxes on government checklists, then forget about it.
Volunteers, especially those who contribute for fun and self enjoyment, often don’t go out of their ways to make the particular projects they’re working on accessible. Or to check if their contributions regress the accessibility of the app.
The nature of accessibility makes it such that the “functional progression” is not linear. If only 50% of the stack is working, that’s practically a 0%. Accessibility requires that almost every part of the stack to be functional for even the most basic use cases.
There’s almost nobody contributing to this area anymore. Expertise and domain knowledge are almost entirely lost.
In addition to that, I feel like work on accessibility is invisible. In the sense that most people are simply apathetic to the work and contributions done on this area. Maybe due to the dynamics of social media that often favor negative engagement? I don’t know. But it sure feels unrewarding. Compare:
Now, I think if I stopped writing here, you dear reader might feel that the situation is mostly gloomy, maybe even get angry at it. However, against all odds, and fighting a fight that seems impossible, there are people working on accessibility. Often without any kind of reward, doing this out of principle. It’s just so easy to overlook their effort!
So as we prepare for the Global Accessibility Awareness Day, I thought it would be an excellent opportunity to highlight these fantastic contributors and their excellent work, and also to talk about some ongoing work on GNOME.
If you consider this kind of work important and relevant, and/or if you need accessibility features yourself, I urge you: please donate to the people mentioned here. Grab these people a coffee. Better yet, grab them a monthly coffee! Contributors who accept donations have a button beneath their avatars. Go help them.
Calendar
GNOME Calendar, the default calendaring app for GNOME, has slowly but surely progressing towards being minimally accessible. This is mostly thanks to the amazing work from Hari Rana and Jeff Fortin Tam!
Back when I was working on fixing accessibility on WebKitGTK, I found the lack of modern tools to inspect the AT-SPI bus a bit off-putting, so I wrote a little app to help me through. Didn’t think much of it, really.
Of course, almost nothing I’ve mentioned so far would be possible if the toolkit itself didn’t have support for accessibility. Thanks to Emmanuele Bassi GTK4 received an entirely new accessibility backend.
Over time, more people picked up on it, and continued improving it and filling in the gaps. Matthias Clasen and Emmanuele continue to review contributions and keep things moving.
One particular contributor is Lukáš Tyrychtr, who has implemented the Text interface of AT-SPI in GTK. Lukáš contributes to various other parts of the accessibility stack as well!
On the design side, one person in particular stands out for a series of contributions on the Accessibility panel of GNOME Settings: Sam Hewitt. Sam introduced the first mockups of this panel in GitLab, then kept on updating it. More recently, Sam introduced mockups for text-to-speech (okay technically these are in the System panel, but that’s in the accessibility mockups folder!).
Please join me in thanking Sam for these contributions!
Having apps and toolkits exposing the proper amount of accessibility information is a necessary first step, but it would be useless if there was nothing to expose to.
Thanks to Mike Gorse and others, the AT-SPI project keeps on living. AT-SPI is the service that receives and manages the accessibility information from apps. It’s the heart of accessibility in the Linux desktop! As far as my knowledge about it goes, AT-SPI is really old, dating back to Sun days.
Samuel Thibault continues to maintain speech-dispatcher and Accerciser. Speech dispatcher is the de facto text-to-speech service for Linux as of now. Accerciser is a venerable tool to inspect AT-SPI trees.
Eitan Isaacson is shaking up the speech synthesis world with libspiel, a speech framework for the desktop. Orca has experimental support for it. Eitan is now working on a desktop portal so that sandboxed apps can benefit from speech synthesis seamlessly!
One of the most common screen readers for Linux is Orca. Orca maintainers have been keeping it up an running for a very long time. Here I’d like to point out that we at Igalia significantly fund Orca development.
I would like to invite the community to share a thank you for all of them!
I tried to reach out to everyone nominally mentioned in this blog post. Some people preferred not to be mentioned. I’m pretty sure I’ve never got to learn about others that are involved in related projects.
I guess what I’m trying to say is, this list is not exhaustive. There are more people involved. If you know some of them, please let me encourage you to pay them a tea, a lunch, a boat trip in Venice, whatever you feel like; or even just reach out to them and thank them for their work.
If you contribute or know someone who contributes to desktop accessibility, and wishes to be here, please let me know. Also, please let me know if this webpage itself is properly accessible!
A Look Into The Future
Shortly after I started to write this blog post, I thought to myself: “well, this is nice and all, but it isn’t exactly robust.” Hm. If only there was a more structured, reliable way to keep investing on this.
Coincidentally, at the same time, we were introduced to our new executive director Steven. With such a blast of an introduction, and seeing Steven hanging around in various rooms, I couldn’t resist asking about it. To my great surprise and joy, Steven swiftly responded to my inquiries and we started discussing some ideas!
Conversations are still ongoing, and I don’t want to create any sort of hype in case things end up not working, but… maaaaaaybe keep in mind that there might be an announcement soon!
Huge thanks to the people above, and to everyone who helped me write this blog post
¹ – Jeff doesn’t accept donations for himself, but welcomes marketing-related business
Update on what happened in WebKit in the week from May 5 to May 12.
This week saw one more feature enabled by default, additional support to
track memory allocations, continued work on multimedia and WebAssembly.
Cross-Port 🐱
The Media Capabilities API is now enabled by default. It was previously available as a run-time option in the WPE/WebKitGTK API (WebKitSettings:enable-media-capabilities), so this is just a default tweak.
Landed a change that integrates malloc heap breakdown functionality with non-Apple ports. It works similarly to Apple's one yet in case of non-Apple ports the per-heap memory allocation statistics are printed to stdout periodically for now. In the future this functionality will be integrated with Sysprof.
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
Support for WebRTC RTP header extensions was improved, a RTP header extension for video orientation metadata handling was introduced and several simulcast tests are now passing
Progress is ongoing on resumable player suspension, which will eventually allow us to handle websites with lots of simultaneous media elements better in the GStreamer ports, but this is a complex task.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
The in-place Wasm interpreter (IPInt) port to 32-bits has seen some more work.
Fixed a bug in OMG caused by divergence with the 64-bit version. Further syncing is underway.
Releases 📦️
Michael Catanzaro has published a writeup on his blog about how the WebKitGTK API versions have changed over time.
Infrastructure 🏗️
Landed some improvements in the WebKit container SDK for Linux, particularly in error handling.
In my work on RISC-V LLVM, I end up working with the llvm-test-suite a lot,
especially as I put more effort into performance analysis, testing, and
regression hunting.
suite-helper is a
Python script that helps with some of the repetitive tasks when setting up,
building, and analysing LLVM test
suite builds. (Worth nothing for
those who aren't LLVM regulars: llvm-test-suite is a separate repository to
LLVM and includes execution tests and benchmarks, which is different to the
targeted unit tests including in the LLVM monorepo).
As always, it scratches an itch for me. The design target is to provide a
starting point that is hopefully good enough for many use cases, but it's easy
to modify (e.g. by editing the generated scripts or emitted command lines) if
doing something that isn't directly supported.
The main motivation for putting this script together came from my habit of
writing fairly detailed "lab notes" for most of my work. This typically
includes a listing of commands run, but I've found such listings rather
verbose and annoying to work with. This presented a good opportunity for
factoring out common tasks into a script, resulting in suite-helper.
Functionality overview
suite-helper has the following subtools:
create
Checkout llvm-test-suite to the given directory. Use the --reference
argument to reference git objects from an existing local checkout.
add-config
Add a build configuration using either the "cross" or "native" template.
See suite-helper add-config --help for a listing of available options.
For a build configuration 'foo', a _rebuild-foo.sh file will be created
that can be used to build it within the build.foo subdirectory.
status
Gives a listing of suite-helper managed build configurations that were
detected, attempting to indicate if they are up to date or not (e.g.
spotting if the hash of the compiler has changed).
run
Run the given build configuration using llvm-lit, with any additional
options passed on to lit.
match-tool
A helper that is used by suite-helper reduce-ll but may be useful in
your own reduction scripts. When looking at generated assembly or
disassembly of an object file/binary and an area of interest, your natural
inclination may well be to try to carefully craft logic to match something
that has equivalent/similar properties. Credit to Philip Reames for
underlining to me just how unresonably effective it is to completely
ignore that inclination and just write something that naively matches a
precise or near-precise assembly sequence. The resulting IR might include
some extraneous stuff, but it's a lot easier to cut down after this
initial minimisation stage, and a lot of the time it's good enough. The
match-tool helper takes a multiline sequence of glob patterns as its
argument, and will attempt to find a match for them (a sequential set of
lines) on stdin. It also normalises whitespace.
get-ll
Query ninja nad process its output to try to produce and execute a
compiler command that will emit a .ll for the given input file (e.g. a .c
file). This is a common first step for llvm-reduce, or for starting to
inspect the compilation of a file with debug options enabled.
reduce-ll
For me, it's fairly common to want to produce a minimised .ll file that
produces a certain assembly pattern, based on compiling a given source
input. This subtool automates that process, using get-ll to retrieve the
ll, then llvm-reduce and match-tool to match the assembly.
Usage example
suite-helper isn't intended to avoid the need to understand how to build the
LLVM test suite using CMake and run it using lit, rather it aims to
streamline the flow. As such, a good starting point might be to work through
some llvm-test-suite builds yourself and then look here to see if anything
makes your use case easier or not.
All of the notes above may seem rather abstract, so here is an example of
using the helper to while investigating some poorly canonicalised
instructions and testing my work-in-progress patch to address them.
suite-helper create llvmts-redundancies --reference ~/llvm-test-suite
for CONFIG in baseline trial; do
suite-helper add-config cross $CONFIG\
--cc=~/llvm-project/build/$CONFIG/bin/clang \
--target=riscv64-linux-gnu \
--sysroot=~/rvsysroot \
--cflags="-march=rva22u64 -save-temps=obj"\
--spec2017-dir=~/cpu2017 \
--extra-cmake-args="-DTEST_SUITE_COLLECT_CODE_SIZE=OFF -DTEST_SUITE_COLLECT_COMPILE_TIME=OFF"
./_rebuild-$CONFIG.sh
done# Test suite builds are now available in build.baseline and build.trial, and# can be compared with e.g. ./utils/tdiff.py.# A separate script had found a suspect instruction sequence in sqlite3.c, so# let's get a minimal reproducer.
suite-helper reduce build.baseline ./MultiSource/Applications/sqlite3/sqlite3.c \'add.uw a0, zero, a2 subw a4, a4, zero'\
--reduce-bin=~/llvm-project/build/baseline/bin/llvm-reduce \
--llc-bin=~/llvm-project/build/baseline/bin/llc \
--llc-args=-O3
Hey peoples! Tonight, some meta-words. As you know I am fascinated by
compilers and language implementations, and I just want to know all the
things and implement all the fun stuff: intermediate representations,
flow-sensitive source-to-source optimization passes, register
allocation, instruction selection, garbage collection, all of that.
It started long ago with a combination of curiosity and a hubris to satisfy
that curiosity. The usual way to slake such a thirst is structured
higher education followed by industry apprenticeship, but for whatever
reason my path sent me through a nuclear engineering bachelor’s program
instead of computer science, and continuing that path was so distasteful
that I noped out all the way to rural Namibia for a couple years.
Fast-forward, after 20 years in the programming industry, and having
picked up some language implementation experience, a few years ago I
returned to garbage collection. I have a good level of language
implementation chops but never wrote a memory manager, and Guile’s
performance was limited by its use of the Boehm collector. I had been
on the lookout for something that could help, and when I learned of
Immix it seemed to me that the only thing missing was an appropriate
implementation for Guile, and hey I could do that!
whippet
I started with the idea of an MMTk-style
interface to a memory manager that was abstract enough to be implemented
by a variety of different collection algorithms. This kind of
abstraction is important, because in this domain it’s easy to convince
oneself that a given algorithm is amazing, just based on vibes; to stay
grounded, I find I always need to compare what I am doing to some fixed
point of reference. This GC implementation effort grew into
Whippet, but as it did so a funny
thing happened: the mark-sweep collector that I
prototyped
as a direct replacement for the Boehm collector maintained mark bits in
a side table, which I realized was a suitable substrate for
Immix-inspired bump-pointer allocation into holes. I ended up building
on that to develop an Immix collector, but without lines: instead each
granule of allocation (16 bytes for a 64-bit system) is its own line.
regions?
The Immix paper is
funny, because it defines itself as a new class of mark-region
collector, fundamentally different from the three other fundamental
algorithms (mark-sweep, mark-compact, and evacuation). Immix’s
regions are blocks (64kB coarse-grained heap divisions) and lines
(128B “fine-grained” divisions); the innovation (for me) is the
optimistic evacuation discipline by which one can potentially
defragment a block without a second pass over the heap, while also
allowing for bump-pointer allocation. See the papers for the deets!
However what, really, are the regions referred to by mark-region? If
they are blocks, then the concept is trivial: everyone has a
block-structured heap these days. If they are spans of lines, well, how
does one choose a line size? As I understand it, Immix’s choice of 128
bytes was to be fine-grained enough to not lose too much space to
fragmentation, while also being coarse enough to be eagerly swept during
the GC pause.
This constraint was odd, to me; all of the mark-sweep systems I have
ever dealt with have had lazy or concurrent sweeping, so the lower bound
on the line size to me had little meaning. Indeed, as one reads papers
in this domain, it is hard to know the real from the rhetorical; the
review process prizes novelty over nuance. Anyway. What if we cranked
the precision dial to 16 instead, and had a line per granule?
That was the process that led me to Nofl. It is a space in a collector
that came from mark-sweep with a side table, but instead uses the side
table for bump-pointer allocation. Or you could see it as an Immix
whose line size is 16 bytes; it’s certainly easier to explain it that
way, and that’s the tack I took in a recent paper submission to
ISMM’25.
paper??!?
Wait what! I have a fine job in industry and a blog, why write a paper?
Gosh I have meditated on this for a long time and the answers are very
silly. Firstly, one of my language communities is Scheme, which was a
research hotbed some 20-25 years ago, which means many
practitioners—people I would be pleased to call peers—came up
through the PhD factories and published many interesting results in
academic venues. These are the folks I like to hang out with! This is
also what academic conferences are, chances to shoot the shit with
far-flung fellows. In Scheme this is fine, my work on Guile is enough
to pay the intellectual cover charge, but I need more, and in the field
of GC I am not a proven player. So I did an atypical thing, which is to
cosplay at being an independent researcher without having first been a
dependent researcher, and just solo-submit a paper. Kids: if you see
yourself here, just go get a doctorate. It is not easy but I can only
think it is a much more direct path to goal.
And the result? Well, friends, it is this blog post :) I got the usual
assortment of review feedback, from the very sympathetic to the less so,
but ultimately people were confused by leading with a comparison to
Immix but ending without an evaluation against Immix. This is fair and
the paper does not mention that, you know, I don’t have an Immix lying
around. To my eyes it was a good paper, an 80%
paper, but, you know, just a
try. I’ll try again sometime.
In the meantime, I am driving towards getting Whippet into Guile. I am
hoping that sometime next week I will have excised all the uses of the
BDW (Boehm GC) API in Guile, which will finally allow for testing Nofl
in more than a laboratory environment. Onwards and upwards!
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
The GstWPE2 GStreamer plugin landed in GStreamer
main,
it makes use of the WPEPlatform API. It will ship in GStreamer 1.28. Compared
to GstWPE1 it provides the same features, but improved support for NVIDIA
GPUs. The main regression is lack of audio support, which is work-in-progress,
both on the WPE and GStreamer sides.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Work on enabling the in-place Wasm interpreter (IPInt) on 32-bits has progressednicely
The JSC tests runner can now guard against a pathological failure mode.
In JavaScriptCore's implementation of
Temporal,
Tim Chevalier fixed the parsing of RFC
9557 annotations in date
strings to work according to the standard. So now syntactically valid but
unknown annotations [foo=bar] are correctly ignored, and the ! flag in an
annotation is handled correctly. Philip Chimento expanded the test suite
around this feature and fixed a couple of crashes in Temporal.
Math.hypot(x, y, z) received a fix for a corner case.
WPE WebKit 📟
WPE now uses the new pasteboard API, aligning it with the GTK port, and enabling features that were previously disabled. Note that the new features work only with WPEPlatform, because libwpe-based backends are limited to access clipboard text items.
WPE Platform API 🧩
New, modern platform API that supersedes usage of libwpe and WPE backends.
Platform backends may add their own clipboard handling, with the Wayland one being the first one to, using wl_data_device_manager.
This continues the effort to close the feature gap between the “traditional” libwpe-based WPE backends and the new WPEPlatform ones.
Community & Events 🤝
Carlos García has published a blog post about the optimizations introduced in
the WPE and GTK WebKit
ports
since the introduction of Skia replacing Cairo for 2D rendering. Plus, there
are some hints about what is coming next.
Cast your mind back to the late 2000s and one thing you might remember is the
excitement about netbooks. You
sacrifice something in raw computational power, but get a lightweight, low
cost and ultra-portable system. Their popularity peaked and started wane maybe
15 years ago now, but I was pleased to discover that the idea lives on in the
form of the Chuwi MiniBook X
N150 and have
been using it as my daily driver for about a month now. Read on for some notes
and thoughts on the device as well as more information than you probably want
about configuring Linux on it.
The bottom line is that I enjoy it, I'd buy it again. But there are real
limitations to keep in mind if you're considering following suit.
Background
First a little detour. As many of my comments are made in reference to my
previous laptops it's probably worth fleshing out that history a little. The
first thing to understand is that my local computing needs are relatively
simple and minimal. I work on large C/C++ codebases (primarily LLVM) with
lengthy compile times, but I build and run tests on a remote machine. This
means I only need enough local compute to comfortably navigate codebases, do
whatever smaller local projects I want to do, and use any needed browser based
tools like videoconferencing or GDocs.
Looking back at my previous two laptops (oldest first):
Intel
N5000
processor, 4GiB RAM (huge weak point even then), 256GB SSD, 14" 1920x1080
matte screen.
Fanless and absolutely silent.
A big draw was the long battery life. Claimed 17h by the manufacturer,
tested at ~12h20m 'light websurfing' in one
review
which I found to be representative, with runtimes closer to 17h possible
if e.g. mostly doing text editing when traveling without WiFi.
Three USB-A ports, one USB-C port, 3.5mm audio jack, HDMI, SD card slot.
Charging via proprietary power plug.
1.30kg weight and 32.3cm x 22.8cm dimensions.
Took design stylings of rather more expensive devices, with a metal
chassis, the ability to fold flat, and a large touchpad.
Claimed battery life reduced to 15h. I found it very similar in practice.
But the battery has degraded significantly over time.
Two USB-A ports, one USB-C port, 3.5mm audio jack, HDMI. Charging via
proprietary power plug.
1.30kg weight and 32.3cm x 21.2cm dimensions.
Still a metal chassis, though sadly designed without the ability to fold
the screen completely flat and the size of the touchpad was downgraded.
I think you can see a pattern here.
As for the processors, the N5000 was part of Intel "Gemini
Lake"
which used the Goldmont Plus microarchitecture. This targets the same market
segment as earlier Atom branded processors (as used by many of those early
netbooks) but with substantially higher performance and a much more
complicated microarchitecture than the early Atom (which was dual issue, in
order with a 16 stage pipeline). The
best reference I can see for the microarchitectures used in the N5000 and
N6000 is AnandTech's Tremont microarchitecture
write-up
(matching the
N6000),
which makes copious reference to differences vs previous iterations. Both the
N5000 and N6000 have a TDP of 6W and 4 cores (no hyperthreading). Notably,
all these designs lack AVX support.
The successor to Tremont, was the Gracemont
microarchitecture,
this time featuring AVX2 and seeing much wider usage due to being used as the
"E-Core" design throughout Intel's chips pairing some number of more
performance-oriented P-Cores with energy efficiency optimised E-Cores. Low
TDP chips featuring just E-Cores were released such as the N100 serving
as a successor to the
N6000
and later the N150 added as a slightly higher clocked version. There have been
further iterations on the microarchitecture since Gracemont with
Crestmont and
Skymont,
but at the time of writing I don't believe these have made it into similar
E-Core only low TDP chips. I'd love to see competitive devices at similar
pricepoints using AMD or Arm chips (and one day RISC-V of course), but this
series of Intel chips seems to have really found a niche.
28.8Wh battery, seems to give 4-6h battery depending on what you're doing
(possibly more if offline and text editing, I've not tried to push to the
limits).
Two USB-C ports (both supporting charging via USB PD), 3.5mm audio jack.
0.92kg weight and 24.4cm x 16.6cm dimensions.
Display is touchscreen, and can fold all the way around for tablet-style
usage.
Just looking at the specs the key trade-offs are clear. There's a big drop in
battery life, but a newer faster processor and fun mini size.
Overall, it's a positive upgrade but there are definitely some downsides. Main
highlights:
Smol! Reasonably light. The 10" display works well at 125% zoom.
The keyboard is surprisingly pleasant to use. The trackpad is obviously
small given size constraints, but again it works just fine for me. It feels
like this is the smallest size where you can have a fairly normal experience
in terms of display and input.
With a metal chassis, the build quality feels good overall. Of course the
real test is how it lasts.
Charging via USB-C PD! I am so happy to be free of laptop power bricks.
The N150 is a nice upgrade vs the N5000 and N6000. AVX2 support means
we're much more likely to hit optimised codepaths for libraries that make
use of it.
But of course there's a long list of niggles or drawbacks. As I say, overall
it works for me, but if it didn't have these drawbacks I'd probably move
more towards actively recommending it without lots of caveats:
Battery life isn't fantastic. I'd be much happier with 10-12h. Though given
the USB-C PD support, it's not hard to reach this with an external battery.
I miss having a silent fanless machine. The fan doesn't come on frequently
in normal usage, but of course it's noticeable when it does. My unit also
suffers from some coil wine which is audible sometimes when scrolling.
Neither is particularly loud but there is a huge difference between never
being able to hear your computer vs sometimes being able to hear it.
Some tinkering needed for initial Linux setup. Depending on your mindset,
this might be a pro! Regardless, I've documented what I've done down below.
I should note that all the basic hardware does work including the
touchscreen, webcam, and microphone. The fact the display is rotated is
mostly an easy fix, but I haven't checked if the fact it shows as 1200x1920
rather than 1920x1080 causes problems for e.g. games.
In-built display is 50Hz rather than 60Hz and I haven't yet succeeded at
overriding this in Linux (although it seems possible in Windows).
It's unfortunate there's no ability to limit charging at e.g. 80% as
supported by some charge controllers as a way of extending battery lifetime.
It charges relatively slowly (~20W draw), which is a further incentive to
have an external battery if out and about.
It's a shame they went with the soldered on Intel AX101 WiFi module rather
than spending a few dollars more for a better module from Intel's line-up.
I totally understand why Chuwi don't/can't have different variants with
different keyboards, but I would sure love a version with a UK key layout!
Screen real estate is lost to the bezel. Additionally, the rounded corners
of the bezel cutting off the corner pixels is annoying.
Do beware that the laptop ships with a 12V/3A charger with a USB-C connection
that apparently will use that voltage without any negotiation. It's best not
to use it at all due to the risk of plugging in something that can't handle
12V input.
Conclusion: It's not perfect machine but I'm a huge fan of this form
factor. I really hope we get future iterations or competing products.
Appendix A: Accessories
YMMV, but I picked up the following with the most notable clearly being the
replacement SSD. Prices are the approximate amount paid including any
shipping.
Installation was trivial. Undo 8 screws on the MiniBook underside and it
comes off easily.
The spec is overkill for this laptop (PCIe Gen4 when the MiniBook only
supports Gen3 speeds). But the price was good meaning it wasn't very
attractive to spend a similar amount for a slower last-generation drive
with worse random read/write performance.
Unlike the MiniBook itself, charges very quickly. Also supports
pass-through charging so you can charge the battery while also charging
downstream devices, through a single wall socket.
Goes for a thin but wider squared shape vs many other batteries that are
quick thick, though narrower. For me this is more convenient in most
scenarios.
Despite being designed for the Steam Deck, this actually works really nicely
for holding it vertically. The part that holds the device is adjustable and
comfortably holds it without blocking the air vents. I use this at my work
desk and just need to plug in a single USB-C cable for power, monitor, and
peripherals (and additionally the 3.5mm audio jack if using speakers).
I'd wondered if I might have to instead find some below-desk setup to keep
cables out of the way, but placing this at the side of my desk and using
right-angled cables (or adapters) that go straight down off the side means
seems to work fairly well for keeping the spiders web of cables out of the
way.
Support 20V 1.75A when only a USB-C cable is connected, which is more than
enough for charging the MiniBook.
Given all my devices when traveling are USB, I was interested in
something compact that avoids the need for separate adapter plugs. This
seems to fit the bill.
Case: 11" Tablet
case (~£2.50 when
bought with some other things)
Took a gamble but this fits remarkably well, and has room for extra cables
/ adapters.
Appendix B: Arch Linux setup
As much for my future reference as for anything else, here are notes on
installing and configuring Arch Linux on the MiniBook X to my liking, and
working through as many niggles as I can. I'm grateful to Sonny Piers' GitHub
repo for some pointers on dealing
with initial challenges like screen rotation.
Initial install
Download an Arch Linux install image and
write to a USB drive. Enter the BIOS by pressing F2 while booting and disable
secure boot. I found I had to do this, then save and exit for
it to stick. Then enter BIOS again on a subsequent boot and select the option
to boot straight into it (under the "Save and Exit" menu).
In order to have the screen rotated correctly, we need to set the boot
parameter video=DSI-1:panel_orientation=right_side_up. Do this by pressing
e at the boot menu and manually adding.
Then connect to WiFi (iwctl then station wlan0 scan, station wlan0 get-networks, station wlan0 connect $NETWORK_NAME and enter the WiFi
password). It's likely more convenient to do the rest of the setup via ssh,
which can be done by setting a temporary root password with passwd and then
connecting with
ssh -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null root@archiso.
Set the SSD sector size to 4k:
# Confirm 4k sector sizes are available and supported.
nvme id-ns -H /dev/nvme0n1
# Shows:# LBA Format 0 : Metadata Size: 0 bytes - Data Size: 512 bytes - Relative Performance: 0x2 Good (in use)# LBA Format 1 : Metadata Size: 0 bytes - Data Size: 4096 bytes - Relative Performance: 0x1 Better
nvme format --lbaf=1 /dev/nvme0n1
Now partition disks and create filesystems (with encrypted rootfs):
The touchscreen input also needs to be rotated to work properly. See
here for guidance
on the transformation matrix for xinput and confirm the name to match with
xinput list.
git clone https://aur.archlinux.org/yay.git &&cd yay
makepkg -si
cd .. && rm -rf yay
yay xautolock
yay ps_mem
Use UK keymap and in X11 use caps lock as escape:
localectl set-keymap uk
localectl set-x11-keymap gb """" caps:escape
The device has a US keyboard layout which has one less key than than the UK
layout and
several keys in different places. As I regularly use a UK layout external
keyboard, rather than just get used to this I set a UK layout and use AltGr
keycodes for backslash (AltGr+-) and pipe
(AltGR+`).
For audio support, I didn't need to do anything other than get rid of
excessive microphone noise by opening alsamixer and turning "Interl Mic
Boost" down to zero.
Suspend rather than shutdown when pressing power button
It's too easy to accidentally hit the power button especially when
plugging/unplugging usb-c devices, so lets make it just suspend rather than
shutdown.
See the Arch
wiki
for a discussion. s2idle and deep are reported as supported from
/sys/power/mem_sleep, but the discharge rate leaving the laptop suspended
overnight feels higher than I'd like. Let's enable deep sleep in the hope it
reduces it.
Check last sleep mode used with sudo journalctl | grep "PM: suspend" | tail -2. And check the current sleep mode with cat /sys/power/mem_sleep.
Checking the latter after boot you're likely to be worried to see that s2idle
is still default. But try suspending and then checking the journal and you'll
see systemd switches it just prior to suspending. (i.e. the setting works as
expected, even if it's only applied lazily).
I haven't done a reasonably controlled test of the impact.
Changing DPI
The strategy is to use xsettingsd to
update applications on the fly that support it, and otherwuse update Xft.dpi
in Xresources. I've found a DPI of 120 works well for me. So add systemctl --user restart xsettingsd to .xinitrc as well as a call to this set_dpi
script with the desired DPI:
!/bin/sh
DPI="$1"if[ -z "$DPI"]; thenecho"Usage: $0 <dpi>"exit1fiCONFIG_FILE="$HOME/.config/xsettingsd/xsettingsd.conf"
mkdir -p "$(dirname "$CONFIG_FILE")"if ! [ -e "$CONFIG_FILE"]; then
touch "$CONFIG_FILE"fiif grep -q 'Xft/DPI'"$CONFIG_FILE"; then
sed -i "s|Xft/DPI.*|Xft/DPI $(($DPI*1024))|""$CONFIG_FILE"elseecho"Xft/DPI $(($DPI*1024))" >> "$CONFIG_FILE"fi
systemctl --user restart xsettingsd.service
echo"Xft.dpi: $DPI" | xrdb -merge
echo"DPI set to $DPI"
If attaching to an external display where a different DPI is desirable, just
call set_dpi as needed.
Enabing Jabra bluetooth headset
sudo systemctl enable --now bluetooth.service
Follow instructions in https://wiki.archlinux.org/title/bluetooth_headset to
pair
Remember to do the 'trust' step so it automatically reconnects
Automatically enabling/disabling display outputs upon plugging in a monitor
The srandrd tool provides a handy way of
listening for changes in the plug/unplugged status of connections and
launching a shell script. First try it out with the following to observe
events:
yay srandrd
cat - <<'EOF' > /tmp/echo.sh
echo $SRANDRD_OUTPUT $SRANDRD_EVENT $SRANDRD_EDID
EOF
chmod +x /tmp/echo.sh
srandrd -n /tmp/echo.sh
# You should now see the events as you plug/unplug devices.
So this is simple - we just write a shell script that srandrd will invoke
which calls xrandr as desired when connect/disconnect of the device with the
target EDID happens? Almost. There are two problems I need to work around:
The monitor I use for work is fairly bad at picking up a 4k60Hz input
signal. As far as I can tell this is independent of the cable used or input
device. What does seem to reliably work is to output a 1080p signal, wait a
bit, and then reconfigure to 4k60Hz.
The USB-C cable I normally plug into in my sitting room is also connected
to the TV via HDMI (I often use this for my Steam Deck). I noticed occasional
graphical slowdowns and after more debugging found I could reliably see this
in hiccups / reduced measured frame rate in glxgears that correspond with
recurrent plug/unplug events. The issue disappears completely if video output
via the cable is configured once and then unconfigured again. Very weird, but
at least there's a way round it.
Solving both of the above can readily be addressed by producing a short
sequence of xrandr calls rather than just one. Except these xrandr calls
themselves trigger new events that cause srandrd to reinvoke the
script. So I add a mechanism to
have the script ignore events if received in short succession. We end up with
the following:
#!/usr/bin/shEVENT_STAMP=/tmp/display-change-stamp
# Recognised displays (as reported by $SRANDRD_EDID).WORK_MONITOR="720405518350B628"TELEVISION="6D1E82C501010101"
msg(){printf"display-change-handler: %s\n""$*" >&2}# Call xrandr, but refresh $EVENT_STAMP just before doing so. This causes# connect/disconnect events generated by the xrandr operation to be skipped at# the head of this script. Call xrefresh afterwards to ensure windows are# redrawn if necessary.
wrapped_xrandr(){
touch $EVENT_STAMP
xrandr "$@"
xrefresh
}
msg "received event '$SRANDRD_OUTPUT: $SRANDRD_EVENT$SRANDRD_EDID'"# Suppress event if within 2 seconds of the timestamp file being updated.if[ -f $EVENT_STAMP]; thencur_time=$(date +%s)file_time=$(stat -c %Y $EVENT_STAMP)if[$((cur_time-file_time)) -le 2]; then
msg "suppressing event (exiting)"exit0fifi
touch $EVENT_STAMP
is_output_outputting(){
xrandr --query | grep -q "^$1 connected.*[0-9]\+x[0-9]\++[0-9]\++[0-9]\+"}# When connecting the main 'docked' display, disable the internal screen. Undo# this when disconnecting.case"$SRANDRD_EVENT$SRANDRD_EDID"in"connected $WORK_MONITOR")
msg "enabling 1920x1080 output on $SRANDRD_OUTPUT, disabling laptop display, and sleeping for 10 seconds"
wrapped_xrandr --output DSI-1 --off --output $SRANDRD_OUTPUT --mode 1920x1080
sleep 10
msg "switching up to 4k output"
wrapped_xrandr --output DSI-1 --off --output $SRANDRD_OUTPUT --preferred
msg "done"exit
;;
"disconnected $WORK_MONITOR")
msg "re-enabling laptop display and disabling $SRANDRD_OUTPUT"
wrapped_xrandr --output DSI-1 --preferred --rotate right --output $SRANDRD_OUTPUT --off
msg "done"exit
;;
"connected $TELEVISION")# If we get the 'connected' event and a resolution is already configured# and being emitted, then do nothing as the event was likely generated by# a manual xrandr call from outside this script.if is_output_outputting $SRANDRD_OUTPUT; then
msg "doing nothing as manual reconfiguration suspected"exit0fi
msg "enabling then disabling output $SRANDRD_OUTPUT which seems to avoid subsequent disconnect/reconnects"
wrapped_xrandr --output $SRANDRD_OUTPUT --mode 1920x1080
sleep 1
wrapped_xrandr --output $SRANDRD_OUTPUT --off
msg "done"exit
;;
*)
msg "no handler for $SRANDRD_EVENT$SRANDRD_EDID"exit
;;
esac
Outputting to in-built screen at 60Hz (not yet solved)
The screen is unfortunately limited to 50Hz out of the box, but at least on
Windows it's possible to use Custom Resolution
Utility
to edit the EDID and add a 1200x1920 60Hz mode (reminder: the display is
rotated to the right which is why width x height is the opposite order to
normal). To add Custom Resolution utility:
Open CRU
Click to "add a detailed resolution"
Select "Exact reduced" and enter Active: 1200 horizontal pixels, Vertical
1920 lines, and Refresh rate: 60.000 Hz. This results in Horizontal:
117.000kHz and pixel clock 159.12MHz. Leave interlaced unticked.
I exported this to a file with the hope of reusing on Linux.
As is often the case, the Arch Linux wiki has some relevant
guidance
on configuring an EDID override on Linux. I tried to follow the guidance by:
Copying the exported EDID file to
/usr/lib/firmware/edid/minibook_x_60hz.bin.
Adding drm.edid_firmware=DSI-1:edid/minibook_x_60hz.bin (DSI-1 is the
internal display) to the kernel commandline using efibootmgr.
Confirming this shows up in the kernel command line in dmesg but there are
no DRM messages regarding EDID override or loading the file. I also verify
it shows up in cat /sys/module/drm/parameters/edid_firmware.
Attempt adding /usr/lib/firmware/edid/minibook_x_60hz.bin to FILES in
/etc/mkinitcpio.conf and regenerating the initramfs. No effect.
Over the past eight months, Igalia has been working through RISE on the LLVM compiler, focusing on its RISC-V target. The goal is to improve the performance of generated code for application-class RISC-V processors, especially where there are gaps between LLVM and GCC RISC-V.
The result? A set of improvements that reduces execution time by up to 15% on our SPEC CPU® 2017-based benchmark harness.
In this blog post, I’ll walk through the challenges, the work we did across different areas of LLVM (including instruction scheduling, vectorization, and late-stage optimizations), and the resulting performance gains that demonstrate the power of targeted compiler optimization for the RISC-V architecture on current RVA22U64+V and future RVA23 hardware.
First, to understand the work involved in optimizing the RISC-V performance, let’s briefly discuss the key components of this project: the RISC-V architecture itself, the LLVM compiler infrastructure, and the Banana Pi BPI-F3 board as our target platform.
RISC-V is a modern, open-standard instruction set architecture (ISA) built around simplicity and extensibility. Unlike proprietary ISAs, RISC-V’s modular design allows implementers to choose from base instruction sets (e.g., RV32I, RV64I) and optional extensions (e.g., vector ops, compressed instructions). This flexibility makes it ideal for everything from microcontrollers to high-performance cores, while avoiding the licensing hurdles of closed ISAs. However, this flexibility also creates complexity: without guidance, developers might struggle to choose the right combination of extensions for their hardware.
Enter RISC-V Profiles: standardized bundles of extensions that ensure software compatibility across implementations. For the BPI-F3’s CPU, the relevant profile is RVA22U64, which includes:
Mandatory: RV64GC (64-bit with general-purpose + compressed instructions), Zicsr (control registers), Zifencei (instruction-fetch sync), and more.
Optional: The Vector extension (V) v1.0 (for SIMD operations) and other accelerators.
We chose to focus our testing on two configurations: RVA22U64 (scalar) and RVA22U64+V (vector), since they cover a wide variety of hardware. It's also important to note that code generation for vector-capable systems (RVA22U64+V) differs significantly from scalar-only targets, making it crucial to optimize both paths carefully.
RVA23U64, which mandates the vector extension, was not chosen because the BPI-F3 doesn’t support it.
LLVM is a powerful and widely used open-source compiler infrastructure. It's not a single compiler but rather a collection of modular and reusable compiler and toolchain technologies. LLVM's strength lies in its flexible and well-defined architecture, which allows it to efficiently compile code written in various source languages (like C, C++, Rust, etc.) for a multitude of target architectures, including RISC-V. A key aspect of LLVM is its optimization pipeline. This series of analysis and transformation passes works to improve the generated machine code in various ways, such as reducing the number of instructions, improving data locality, and exploiting target-specific hardware features.
The Banana Pi BPI-F3 is a board featuring a SpacemiT K1 8-core RISC-V chip: PU integrates 2.0 TOPs AI computing power. 2/4/8/16G DDR and 8/16/32/128G eMMC onboard.2x GbE Ethernet port, 4x USB 3.0 and PCIe for M.2 interface, support HDMI and Dual MIPI-CSI Camera.
Most notably, the RISC-V CPU supports the RVA22U64 Profile and 256-bit RVV 1.0 standard.
Let's define the testing environment. We use the training dataset on SPEC CPU® 2017-based benchmark to measure the impact of changes to the LLVM codebase. We do not use the reference dataset for practical reasons, i.e., the training dataset finishes in hours instead of days.
The benchmarks were executed on the BPI-F3, running Arch Linux and Kernel 6.1.15. The configuration of each compiler invocation is as follows:
LLVM at the start of the project (commit cd0373e0): SPEC benchmarks built with optimization level 3 (-O3), and LTO enabled (-flto). We’ll show the results using both RVA22U64 (-march=rva22u64) and the RVA22U64+V profiles (-march=rva22u64_v).
LLVM today (commit b48c476f): SPEC benchmarks built with optimization level 3 (-O3), LTO enabled (-flto), tuned for the SpacemiT-X60 (-mcpu=spacemit-x60), and IPRA enabled (-mllvm -enable-ipra -Wl,-mllvm,-enable-ipra). We’ll also show the results using both RVA22U64 (-march=rva22u64) and the RVA22U64+V profile (-march=rva22u64_v).
GCC 14.2: SPEC benchmarks built with optimization level 3 (-O3), and LTO enabled (-flto). GCC 14.2 doesn't support profile names in -march, so a functionally equivalent ISA naming string was used (skipping the assortment of extensions that don't affect codegen and aren't recognised by GCC 14.2) for both RVA22U64 and RVA22U64+V.
The following graph shows the improvements in execution time of the SPEC benchmarks from the start of the project (light blue bar) to today (dark blue bar) using the RVA22U64 profile, on the BPI-F3. Note that these include not only my contributions but also the improvements of all other individuals working on the RISC-V backend. We also include the results of GCC 14.2 for comparison (orange bar). Our contributions will be discussed later.
The graph is sorted by the execution time improvements brought by the new scheduling model. We see improvements across almost all benchmarks, from small gains in 531.deepsjeng_r (3.63%) to considerable ones in 538.imagick_r (19.67%) and 508.namd_r (25.73%). There were small regressions in the execution time of 510.parest_r (-3.25%); however, 510.parest_r results vary greatly in daily tests, so it might be just noise. Five benchmarks are within 1% of previous results, so we assume there was no impact on their execution time.
When compared to GCC, LLVM today is faster in 11 out of the 16 tested benchmarks (up to 23.58% faster than GCC in 541.leela_r), while being slower in three benchmarks (up to 6.51% slower than GCC in 510.parest_r). Current LLVM and GCC are within 1% of each other in the other two benchmarks. Compared to the baseline of the project, GCC was faster in ten benchmarks (up to 26.83% in 508.namd_r) while being slower in only five.
Similarly, the following graph shows the improvements in the execution time of SPEC benchmarks from the start of the project (light blue bar) to today (dark blue bar) on the BPI-F3, but this time with the RVA22U64+V profile, i.e., the RVA22U64 plus the vector extension (V) enabled. Again, GCC results are included (orange bar), and the graph shows all improvements gained during the project.
The graph is sorted by the execution time improvements brought by the new scheduling model. The results for RVA22U64+V follow a similar trend, and we see improvements in almost all benchmarks. From 4.91% in 500.perlbench_r to (again) a considerable 25.26% improvement in 508.namd_r. Similar to the RVA22U64 results, we see a couple of regressions: 510.parest_r with (-3.74%) and 523.xalancbmk_r (-6.01%). Similar to the results on RVA22U64, 523.xalancbmk_r, and 510.parest_r vary greatly in daily tests on RVA22u64+V, so these regressions are likely noise. Four benchmarks are within 1% of previous results, so we assume there was no impact on their execution time.
When compared to GCC, LLVM today is faster in 10 out of the 16 tested benchmarks (up to 23.76% faster than GCC in 557.xz_r), while being slower in three benchmark (up to 5.58% slower in 538.imagick_r). LLVM today and GCC are within 1-2% of each other in the other three benchmarks. Compared to the baseline of the project, GCC was faster in eight benchmarks (up to 25.73% in 508.namd_r) while being slower in five.
Over the past eight months, our efforts have concentrated on several key areas within the LLVM compiler infrastructure to specifically target and improve the efficiency of RISC-V code generation. These contributions have involved delving into various stages of the compilation process, from instruction selection to instruction scheduling. Here, we'll focus on three major areas where substantial progress has been made:
Introducing a scheduling model for the hardware used for benchmarking (SpacemiT-X60): LLVM had no scheduling model for the SpacemiT-X60, leading to pessimistic and inefficient code generation. We added a model tailored to the X60’s pipeline, allowing LLVM to better schedule instructions and improve performance. Longer term, a more generic in-order model could be introduced in LLVM to help other RISC-V targets that currently lack scheduling information, similar to how it’s already done for other targets, e.g., Aarch64. This contribution alone brings up to 15.76% improvement on the execution time of SPEC benchmarks.
Improved Vectorization Efficiency: LLVM’s SLP vectorizer used to skip over entire basic blocks when calculating spill costs, leading to inaccurate estimations and suboptimal vectorization when functions were present in the skipped blocks. We addressed this by improving the backward traversal to consider all relevant blocks, ensuring spill costs were properly accounted for. The final solution, contributed by the SLP Vectorizer maintainer, was to fix the issue without impacting compile times, unlocking better vectorization decisions and performance. This contribution brings up to 11.87% improvement on the execution time of SPEC benchmarks.
Register Allocation with IPRA Support: enabling Inter-Procedural Register Allocation (IPRA) to the RISC-V backend. IPRA reduces save/restore overhead across function calls by tracking which registers are used. In the RISC-V backend, supporting IPRA required implementing a hook to report callee-saved registers and prevent miscompilation. This contribution brings up to 3.42% improvement on the execution time of SPEC benchmarks.
The biggest contribution so far is the scheduler modeling tailored for the SpacemiT-X60. This scheduler is integrated into LLVM's backend and is designed to optimize instruction ordering based on the specific characteristics of the X60 CPU.
The scheduler was introduced in PR 137343. It includes detailed scheduling models that account for the X60's pipeline structure, instruction latencies for all scalar instructions, and resource constraints. The current scheduler model does not include latencies for vector instructions, but it is a planned future work. By providing LLVM with accurate information about the target architecture, the scheduler enables more efficient instruction scheduling, reducing pipeline stalls and improving overall execution performance.
The graph is sorted by the execution time improvements brought by the new scheduling model. The introduction of a dedicated scheduler yielded substantial performance gains. Execution time improvements were observed across several benchmarks, ranging from 1.04% in 541.leela_r to 15.76% in 525.x264_r.
Additionally, the scheduler brings significant benefits even when vector extensions are enabled, as shown above. The graph is sorted by the execution time improvements brought by the new scheduling model. Execution time improvements range from 3.66% in 544.nab_r to 15.58% in 508.namd_r, with notable code size reductions as well, e.g., a 6.47% improvement in 519.lbm_r (due to decreased register spilling).
Finally, the previous graph shows the comparison between RVA22U64 vs RVA22U64+V, both with the X60 scheduling model enabled. The only difference is 525.x264_r: it is 17.48% faster on RVA22U64+V.
A key takeaway from these results is the critical importance of scheduling for in-order processors like the SpacemiT-X60. The new scheduler effectively closed the performance gap between the scalar (RVA22U64) and vector (RVA22U64+V) configurations, with the vector configuration now outperforming only in a single benchmark (525.x264_r). On out-of-order processors, the impact of scheduling would likely be smaller, and vectorization would be expected to deliver more noticeable gains.
SLP Vectorizer Spill Cost Fix + DAG Combiner Tuning #
One surprising outcome in early benchmarking was that scalar code sometimes outperformed vectorized code, despite RISC-V vector support being available. This result prompted a detailed investigation.
Using profiling data, we noticed increased cycle counts around loads and stores in vectorized functions; the extra cycles were due to register spilling, particularly around function call boundaries. Digging further, we found that the SLP Vectorizer was aggressively vectorizing regions without properly accounting for the cost of spilling vector registers across calls.
To understand how spill cost miscalculations led to poor vectorization decisions, consider this simplified function, and its graph representation:
This function loads two values from %p, conditionally calls @g() (in both foo and bar), and finally stores the values to %q. Previously, the SLP vectorizer only analyzed the entry and baz blocks, ignoring foo and bar entirely. As a result, it missed the fact that both branches contain a call, which increases the cost of spilling vector registers. This led LLVM to vectorize loads and stores here, introducing unprofitable spills across the calls to @g().
To address the issue, we first proposed PR 128620, which modified the SLP vectorizer to properly walk through all basic blocks when analyzing cost. This allowed the SLP vectorizer to correctly factor in function calls and estimate the spill overhead more accurately.
The results were promising: execution time dropped by 9.92% in 544.nab_r, and code size improved by 1.73% in 508.namd_r. However, the patch also increased compile time in some cases (e.g., +6.9% in 502.gcc_r), making it unsuitable for upstream merging.
Following discussions with the community, Alexey Bataev (SLP Vectorizer code owner) proposed a refined solution in PR 129258. His patch achieved the same performance improvements without any measurable compile-time overhead and was subsequently merged.
The graph shows execution time improvements from Alexey’s patch, ranging from 1.49% in 500.perlbench_r to 11.87% in 544.nab_r. Code size also improved modestly, with a 2.20% reduction in 508.namd_r.
RVA22U64 results are not shown since this is an optimization tailored to prevent the spill of vectors. Scalar code was not affected by this change.
Finally, PR 130430 addressed the same issue in the DAG Combiner by preventing stores from being merged across call boundaries. While this change had minimal impact on performance in the current benchmarks, it improves code correctness and consistency and may benefit other workloads in the future.
IPRA (Inter-Procedural Register Allocation) Support #
Inter-Procedural Register Allocation (IPRA) is a compiler optimization technique that aims to reduce the overhead of saving and restoring registers across function calls. By analyzing the entire program, IPRA determines which registers are used across function boundaries, allowing the compiler to avoid unnecessary save/restore operations.
In the context of the RISC-V backend in LLVM, enabling IPRA required implementing a hook in LLVM. This hook informs the compiler that callee-saved registers should always be saved in a function, ensuring that critical registers like the return address register (ra) are correctly preserved. Without this hook, enabling IPRA would lead to miscompilation issues, e.g., 508.namd_r would never finish running (probably stuck in an infinite loop).
To understand how IPRA works, consider the following program before IPRA. Let’s assume function foo uses s0 but doesn't touch s1:
# Function bar calls foo and conservatively saves all callee-saved registers.
bar:
addi sp, sp, -32
sd ra, 16(sp) # Save return address (missing before our PR)
sd s0, 8(sp)
sd s1, 0(sp) # Unnecessary spill (foo won't clobber s1)
call foo
ld s1, 0(sp) # Wasted reload
ld s0, 8(sp)
ld ra, 16(sp)
addi sp, sp, 32
ret
After IPRA (optimized spills):
# bar now knows foo preserves s1: no s1 spill/reload.
bar:
addi sp, sp, -16
sd ra, 8(sp) # Save return address (missing before our PR)
sd s0, 0(sp)
call foo
ld s0, 0(sp)
ld ra, 8(sp)
addi sp, sp, 16
ret
By enabling IPRA for RISC-V, we eliminated redundant spills and reloads of callee-saved registers across function boundaries. In our example, IPRA reduced stack usage and cut unnecessary memory accesses. Crucially, the optimization maintains correctness: preserving the return address (ra) while pruning spills for registers like s1 when provably unused. Other architectures like x86 already support IPRA in LLVM, and we enable IPRA for RISC-V PR 125586.
IPRA is not enabled by default due to a bug, described in issue 119556; however, it does not affect the SPEC benchmarks.
The graph shows the improvements achieved by this transformation alone, using the RVA22U64 profile. There were execution time improvements ranging from 1.57% in 505.mcf_r to 3.16% in 519.lbm_r.
The graph shows the improvements achieved by this transformation alone, using the RVA22U64+V profile. We see similar gains, with execution time improvements of 1.14% in 505.mcf_r and 3.42% in 531.deepsjeng_r.
While we initially looked at code size impact, the improvements were marginal. Given that save/restore sequences tend to be a small fraction of total size, this isn't surprising and not the main goal of this optimization.
Setting Up Reliable Performance Testing. A key part of this project was being able to measure the impact of our changes consistently and meaningfully. For that, we used LNT, LLVM’s performance testing tool, to automate test builds, runs, and result comparisons. Once set up, LNT allowed us to identify regressions early, track improvements over time, and visualize the impact of each patch through clear graphs.
Reducing Noise on the BPI-F3. Benchmarking is noisy by default, and it took considerable effort to reduce variability between runs. These steps helped:
Disabling ASLR: To ensure a more deterministic memory layout.
Running one benchmark at a time on the same core: This helped eliminate cross-run contention and improved result consistency.
Multiple samples per benchmark: We collected 3 samples to compute statistical confidence and reduce the impact of outliers.
These measures significantly reduced noise, allowing us to detect even small performance changes with confidence.
Interpreting Results and Debugging Regressions. Another challenge was interpreting performance regressions or unexpected results. Often, regressions weren't caused by the patch under test, but by unrelated interactions with the backend. This required:
Cross-checking disassembly between runs.
Profiling with hardware counters (e.g., using perf).
Identifying missed optimization opportunities due to incorrect cost models or spill decisions.
Comparing scalar vs vector codegen and spotting unnecessary spills or register pressure.
My colleague Luke Lau also set up a centralized LNT instance that runs nightly tests. This made it easy to detect and track performance regressions (or gains) shortly after new commits landed. When regressions did appear, we could use the profiles and disassembly generated by LNT to narrow down which functions were affected, and why.
Using llvm-exegesis (sort of). At the start of the project, llvm-exegesis, the tool LLVM provides to measure instruction latencies and throughput, didn’t support RISC-V at all. Over time, support was added incrementally across three patches: first for basic arithmetic instructions, then load instructions, and eventually vector instructions. This made it a lot more viable as a tool for microarchitectural analysis on RISC-V. However, despite this progress, we ultimately didn’t use llvm-exegesis to collect the latency data for our scheduling model. The results were too noisy, and we needed more control over how measurements were gathered. Instead, we developed an internal tool to generate the latency data, something we plan to share in the future.
Notable Contributions Without Immediate Benchmark Impact. While some patches may not have led to significant performance improvements in benchmarks, they were crucial for enhancing the RISC-V backend's robustness and maintainability:
Improved Vector Handling in matchSplatAsGather (PR #117878): This patch updated the matchSplatAsGather function to handle vectors of different sizes, enhancing code generation for @llvm.experimental.vector.match on RISC-V.
Addition of FMA Cost Model (PRs #125683 and #126076): These patches extended the cost model to cover the FMA instruction, ensuring accurate cost estimations for fused multiply-add operations.
Generalization of vp_fneg Cost Model (PR #126915): This change moved the cost model for vp_fneg from the RISC-V-specific implementation to the generic Target Transform Info (TTI) layer, promoting consistent handling across different targets.
Late Conditional Branch Optimization for RISC-V (PR #133256): Introduced a late RISC-V-specific optimization pass that replaces conditional branches with unconditional ones when the condition can be statically evaluated. This creates opportunities for further branch folding and cleanup later in the pipeline. While performance impact was limited in current benchmarks, it lays the foundation for smarter late-stage CFG optimizations.
These contributions, while not directly impacting benchmark results, laid the groundwork for future improvements.
This project significantly improved the performance of the RISC-V backend in LLVM through a combination of targeted optimizations, infrastructure improvements, and upstream contributions. We tackled key issues in vectorization, register allocation, and scheduling, demonstrating that careful backend tuning can yield substantial real-world benefits, especially on in-order cores like the SpacemiT-X60.
Future Work:
Vector latency modeling: The current scheduling model lacks accurate latencies for vector instructions.
Further scheduling model fine-tuning: This would impact the largest number of users and would align RISC-V with other targets in LLVM.
Improve vectorization: The similar performance between scalar and vectorized code suggests we are not fully exploiting vectorization opportunities. Deeper analysis might uncover missed cases or necessary model tuning.
Improvements to DAGCombine: after PR 130430, Philip Reames created issue 132787 with ideas to improve the store merging code.
This work was made possible thanks to support from RISE, under Research Project RP009. I would like to thank my colleagues Luke Lau and Alex Bradbury for their ongoing technical collaboration and insight throughout the project. I’m also grateful to Philip Reames from Rivos for his guidance and feedback. Finally, a sincere thank you to all the reviewers in the LLVM community who took the time to review, discuss, and help shape the patches that made these improvements possible.
Recent presentations at BlinkOn strike some familliar notes. Seems a common theme, ideas come back.
Since I joined Igalia in 2019, I don't think I've missed a BlinkOn. This year, however, there was a conflict with the W3C AC meetings and we felt that it was more useful that I attend those, since Igalia already had a sizable contingent at BlinkOn itself and my Web History talk with Chris Lilley was pre-recorded.
When I returned, and videos of the event began landing, I was keen to see what people talked about. There were lots of interesting talks, but one jumped out at me right away: Bramus gave one called "CSS Parser Extensions" - which I wasn't familliar with, so was keen to see. Turns out it was just very beginnings of him exploring ideas to make CSS polyfillable.
This talk made me sit up and pay attention because, actually, it's really how I came to be involved in standards. It's the thing that started a lot of the conversations that eventually became the Extensible Web Community Group and the Extensible Web Manifesto, and ultimately Houdini, a joint Task Force of the W3C TAG and CSS Working Group (in fact, I am also the one who proposed the name ✨). In his talk, he hit on many of the same notes that led me there too.
Polyfills are really interesting when you step back and look at them. They can be used to make the standards development, feedback and rollout so much better. But CSS is almost historically hostile to that approach becauase it just throws away anything it doesn't understand. That means if you want to polyfill something you've got to re-implement lots of stuff that the browser already does: You've got to re-fetch the stylesheet (if you can!) as text, and then bring your own parser to parse it, and then... well, you still can't actually realistically implement many things.
But what if you could?
Houdini has stalled. In my mind, this mainly due to when it happened and what it chose to focus on shipping first. One of the first things that we all agreed to in the first Houdini meeting was that we expose the parser. This is true for all of the reasons Bramus discussed, and more. But that effort got hung up on the fact that there was a sense we first needed a typed OM. I'm not sure how true that really is. Other cool Houdini things were, I think, also hung up on lots of things that were being reworked at the time, and resource competition. But I think that the thing that really killed it was just what shipped first. It was not something that might be really useful for polyfilling, like custom functions or custom media queries or custom pseduo classes, or very ambitiously, something like custom layouts --- but custom paint. The CSS Working Group doesn't publish a lot of new "paints". There are approximately 0 named background images, for example. There's no background-image: checkerboard; for example. But the working group does publish lots of those other things like functions or psueudo classes. See what I mean? Those other things were part of the real vision - they can be used to make cow paths. Or, they can be used to show that, actually, nobody wants that cow path. Or, if it isn't - It can instead rapidly inspire better solutions..
Anyway, the real challenge with most polyfills is performance. Any time that we're going to step out of "60 fps scrollers" into JS land that's iffy... But not impossible, and if we're honest, we'd have to admit that the truth is that our current/actual attempts to polyfill are definitely worse than something closer to native. With effort, surely we can at least improve things by looking at where there are some nice "joints" where we can cleave the problem.
This is why in recent years I've suggested that perhaps what would really benefit us is a few custom things (like functions) and then just enabling CSS-like languages, which can handle the fetch/parse problems and perhaps give us some of the most basic primitive ideas.
So, where will all of this go? Who knows - but I'm glad some others are interested and talking about some of it again.
This blog post might interest you if you want to try the bleeding edge NVK driver which allows to decode H264/5 video with the power of the Vulkan extensions VK_KHR_video_decode_h26x.
This is a summary of the instructions provided in the MR. This work needs a recent kernel with new features, so it will describe the steps to add this feature and build this new kernel on an Ubuntu based system.
To run the NVK driver, you need a custom patch to be applied on top of the Nouveau driver. This patch applies on minimum 6.12 kernel so you need to build a new kernel except if your distribution is running bleeding edge kernel which i doubt so here is my method I used to build this kernel.
Next step will be to configure the kernel. The best option I’ll recommend you is to copy the kernel config, your distribution is shipping with. On Ubuntu you can find it in /boot with the name config-6.8.0-52-generic for example.
$ cp /boot/config-6.8.0-52-generic .config
Then to get the default config, your kernel will use, including the specific options coming with Ubuntu, you’ll have to run:
$ make defconfig
This will setup the build and make it ready to compile with this version of the kernel, auto configuring the new features.
Two options CONFIG_SYSTEM_TRUSTED_KEYS and CONFIG_SYSTEM_REVOCATION_KEYS must be disabled to avoid compilation errors with missing certificates. For that you can set it up within menuconfig or you can edit .config and set these values to ""
Then you should be ready to go for a break ☕, short or long depending on your machine to cook the brand new kernel debian packaged, ready to use:
$ make clean
$ make -j `getconf _NPROCESSORS_ONLN` deb-pkg LOCALVERSION=-custom
The process should end up with a new package named linux-image-6.12.8-custom_6.12.8-3_amd64.deb in the upper folder which can then be installed along your previous kernel.
The first one will replace your current default menulist item in grub upon installation. This means that if you install it, next time you reboot, you’ll boot into that kernel.
Mesa depends on various system packages in addition to python modules and the the rust toolchain. So first we’ll have to install the given package which are all present in Ubuntu 24.04:
Now that the kernel and the Mesa driver have been built and are available for your machine, you should be able to decode your first h264 stream with the NVK driver.
As you might have use the Nvidia driver first and installed with your regular kernel, you might hit a weired error when invoking vulkaninfo such as:
ERROR: [Loader Message] Code 0 : setup_loader_term_phys_devs: Failed to detect any valid GPUs in the current config
ERROR at ./vulkaninfo/./vulkaninfo.h:247:vkEnumeratePhysicalDevices failed with ERROR_INITIALIZATION_FAILED
Indeed nouveau driver can not live along the Nvidia driver, so you’ll have to uninstall the Nvidia driver first to be able to use nouveau properly and the vulkan extensions.
One other solution is to boot on your new custom kernel and modify the file /etc/modprobe.d/nvidia-installer-disable-nouveau.conf to get something like:
# generated by nvidia-installer
#blacklist nouveau
options nouveau modeset=1
In that case the modeset=1 option will enable the driver and allow to use it.
Then you’ll have to reboot with this new configuration
As you may have noticed, during the configure stage that we chose to install the artifacts of the build in a folder named mesa/builddir/install.
Here is a script run-nvk.sh which you can use before calling any binary which will use this folder as a base to set the environment variable dedicated to the NVK Vulkan driver
Now its time to run a real application exploiting the power of Vulkan to decode multimedia content. For that I’ll recommend you to use GStreamer which ship with Vulkan elements for decoding in 1.24.2 version bundled in Ubuntu 24.04.
First of all, you’ll have to install the ubuntu packages for GStreamer
If you succeed to see this list of elements, you should be able to run a GStreamer pipeline with Vulkan Video extensioms. Here is a pipeline to decode a content:
Today, some more words on memory management, on the practicalities of a
system with conservatively-traced references.
The context is that I have finally started banging
Whippet into
Guile, initially in a configuration that
continues to use the conservative Boehm-Demers-Weiser (BDW) collector
behind the scene. In that way I can incrementally migrate over all of
the uses of the BDW API in Guile to use Whippet API instead, and then if
all goes well, I should be able to switch Whippet to use another GC
algorithm, probably the mostly-marking collector
(MMC).
MMC scales better than BDW for multithreaded mutators, and it can
eliminate fragmentation via Immix-inspired optimistic evacuation.
problem statement: how to manage ambiguous edges
A garbage-collected heap consists of memory, which is a set of
addressable locations. An object is a disjoint part of a heap, and is
the unit of allocation. A field is memory within an object that may
refer to another object by address. Objects are nodes in a directed graph in
which each edge is a field containing an object reference. A root is an
edge into the heap from outside. Garbage collection reclaims memory from objects that are not reachable from the graph
that starts from a set of roots. Reclaimed memory is available for new
allocations.
In the course of its work, a collector may want to relocate an object,
moving it to a different part of the heap. The collector can do so if
it can update all edges that refer to the object to instead refer to its
new location. Usually a collector arranges things so all edges have the
same representation, for example an aligned word in memory; updating an
edge means replacing the word’s value with the new address. Relocating
objects can improve locality and reduce fragmentation, so it is a good
technique to have available. (Sometimes we say evacuate, move, or compact
instead of relocate; it’s all the same.)
Some collectors allow ambiguous edges: words in memory whose value
may be the address of an object, or might just be scalar data.
Ambiguous edges usually come about if a compiler doesn’t precisely
record which stack locations or registers contain GC-managed objects.
Such ambiguous edges must be traced conservatively: the collector adds
the object to its idea of the set of live objects, as if the edge were a
real reference. This tracing mode isn’t supported by all collectors.
Any object that might be the target of an ambiguous edge cannot be
relocated by the collector; a collector that allows conservative edges
cannot rely on relocation as part of its reclamation strategy.
Still, if the collector can know that a given object will not be the referent
of an ambiguous edge, relocating it is possible.
How can one know that an object is not the target of an ambiguous edge?
We have to partition the heap somehow into
possibly-conservatively-referenced and
definitely-not-conservatively-referenced. The two ways that I know to
do this are spatially and temporally.
Spatial partitioning means that regardless of the set of root and
intra-heap edges, there are some objects that will never be
conservatively referenced. This might be the case for a type of object
that is “internal” to a language implementation; third-party users that
may lack the discipline to precisely track roots might not be exposed to
objects of a given kind. Still, link-time optimization tends to weather
these boundaries, so I don’t see it as being too reliable over time.
Temporal partitioning is more robust: if all ambiguous references come
from roots, then if one traces roots before intra-heap edges, then any
object not referenced after the roots-tracing phase is available for
relocation.
kinds of ambiguous edges in guile
So let’s talk about Guile! Guile uses BDW currently, which considers
edges to be ambiguous by default. However, given that objects carry
type tags, Guile can, with relatively little effort, switch to precisely
tracing most edges. “Most”, however, is not sufficient; to allow for
relocation, we need to eliminate intra-heap ambiguous edges, to
confine conservative tracing to the roots-tracing phase.
Conservatively tracing references from C stacks or even from static data
sections is not a problem: these are roots, so, fine.
Guile currently traces Scheme stacks almost-precisely: its compiler
emits stack maps for every call site, which uses liveness analysis to
only mark those slots that are Scheme values that will be used in the
continuation. However it’s possible that any given frame is marked
conservatively. The most common case is when using the BDW collector
and a thread is pre-empted by a signal; then its most recent stack frame
is likely not at a safepoint and indeed is likely undefined in terms of
Guile’s VM. It can also happen if there is a call site within a VM
operation, for example to a builtin procedure, if it throws an exception
and recurses, or causes GC itself. Also, when per-instruction
traps
are enabled, we can run Scheme between any two Guile VM operations.
So, Guile could change to trace Scheme stacks fully precisely, but this
is a lot of work; in the short term we will probably just trace Scheme
stacks as roots instead of during the main trace.
However, there is one more significant source of ambiguous roots, and
that is reified continuation objects. Unlike active stacks, these have
to be discovered during a trace and cannot be partitioned out to the
root phase. For delimited continuations, these consist of a slice of
the Scheme stack. Traversing a stack slice precisely is less
problematic than for active stacks, because it isn’t in motion, and it
is captured at a known point; but we will have to deal with stack frames
that are pre-empted in unexpected locations due to exceptions within
builtins. If a stack map is missing, probably the solution there is to
reconstruct one using local flow analysis over the bytecode of the stack
frame’s function; time-consuming, but it should be robust as we do it
elsewhere.
Undelimited continuations (those captured by call/cc) contain a slice
of the C stack also, for historical reasons, and there we can’t trace it
precisely at all. Therefore either we disable relocation if there are
any live undelimited continuation objects, or we eagerly pin any object
referred to by a freshly captured stack slice.
fin
If you want to follow along with the Whippet-in-Guile work, see the
wip-whippet
branch in Git. I’ve bumped its version to 4.0 because, well, why the
hell not; if it works, it will certainly be worth it. Until next time,
happy hacking!
Some short thoughts on recent antitrust and the future of the web platform...
Last week, in a 115 page US Antitrust ruling a federal judge in Virginia found that Google had two more monopolies, this time with relation to advertising technolgies. Previously, you'll recall that we had rulings related to search. There are still more open cases related to Android. And it's not only in the US that similar actions are playing out.
All of these cases kind of mention one another because the problems themselves are all deeply intertwined - but this one is really at the heart of it: That sweet, sweet ad money. I think that you could argue, reasonably, that pretty much everything else was somehow in service of that.
Initially, they made a ton of money showing ads every time someone searches, and pretty quickly signed a default search deal with Mozilla to drive the number of searches way up.
Why make a browser of your own? To drive the searches that show the ads, but also keep more of the money.
Why make OSes of your own, and deals around things that need to be installed? To guarantee that all of those devices drive the searches to show the ads.
And so on...
For a long time now, I've been trying to discuss what, to me, is a rather worrying problem: That those default search dollars are, in the end, what funds the whole web ecosystem. Don't forget that it's not just about the web itself, it's about the platform which provides the underlying technology for just about everything else at this point too.
Between years of blog posts, a podcast series, several talks, experiments like Open Prioritization I have been thinking about this a lot. Untangling it all is going to be quite complex.
In the US, the governments proposed remedies touch just about every part of this. I've been trying to think about how I could sum up my feelings and concerns, but it's quite complex. Then, the other day an article on arstechnica contained an illustration which seemed pretty perfect..
A "game" board that looks like the game Operation, but instead of pieces of internal anatomy there are logos for chrome, gmail, ads, adsense, android and on the board it says "Monoperation: Skill game where you are the DOJ" and the person is removing chrome, and a buzzer is going ff
This image (credited to Aurich Lawson) kind of hit the nail on its head for me: I deeply hope they will be absoltely surgical about this intervention, because the patient I'm worried about isn't Google, it's the whole Web Platform.
If this is interesting to you, my colleague Eric Meyer and I posted an Igalia Chats podcast episode on the topic: Adpocalypse Now?
Notes on AI for Mathematics and Theoretical Computer Science
In April 2025 I had the pleasure to attend an intense week-long workshop at the Simons Institute for the Theory of Computing entitled AI for Mathematics and Theoretical Computer Science. The event was organized jointly with the Simons Laufer Mathematical Sciences Institute (SLMath, for short). It was an intense time (five fully-packed days!) for learning a lot about cutting-edge ideas in this intersection of formal mathematics (primarily in Lean), AI, and powerful techniques for solving mathematical problems, such as SAT solvers and decision procedures (e.g., the Walnut system). Videos of the talks (but not of the training sessions) have been made available.
Every day, several dozen people were in attendance. Judging from the array of unclaimed badges (easily another several dozen), quite a lot more had signed up for the event, but didn't come for one reason or another. It was inspiring to be in the room with so many people involved in these ideas. The training sessions in the afternoon had a great vibe, since so many people we learning and working together simultaneously.
It was great to connect with a number of people, of all stripes. Most of the presenters and attendees were coming from academia, with a minority, such as myself, coming from industry.
The organization was fantastic. We had talks in the morning and training in the afternoon. The final talk in the morning, before lunch, was an introduction to the afternoon training. The training topics were:
The links above point to the tutorial git repos for following along at home.
In the open discussion on the final afternoon, I raised my hand and outed myself as someone coming to the workshop from an industry perspective. Although I had already met a few people in industry prior to Friday, I was able to meet even more by raising my hand and inviting fellow practioners to discuss things. This led to meeting a few more people.
The talks were fascinating; the selection of speakers and topics was excellent. Go ahead and take a look at the list of videos, pick out one or two of interest, grab a beverage of your choice, and enjoy.
With the release of GStreamer 1.26, we now have playback support for Versatile Video Coding (VVC/H.266). In this post, I’ll describe the pieces of the puzzle that enable this, the contributions that led to it, and hopefully provide a useful guideline to adding a new video codec in GStreamer.
With GStreamer 1.26 and the relevant plugins enabled, one can play multimedia files containing VVC content, for example, by using gst-play-1.0:
gst-play-1.0 vvc.mp4
By using gst-play-1.0, a pipeline using playbin3 will be created and the appropriate elements will be auto-plugged to decode and present the VVC content. Here’s what such a pipeline looks like:
Although the pipeline is quite large, the specific bits we’ll focus on in this blog are inside parsebin and decodebin3:
qtdemux → ... → h266parse → ... → avdec_h266
I’ll explain what each of those elements is doing in the next sections.
To store multiple kinds of media (e.g. video, audio and captions) in a way that keeps them synchronized, we typically make use of container formats. This process is usually called muxing, and in order to play back the file we perform de-muxing, which separates the streams again. That is what the qtdemux element is doing in the pipeline above, by extracting the audio and video streams from the input MP4 file and exposing them as the audio_0 and video_0 pads.
Support for muxing and demuxing VVC streams in container formats was added to:
qtmux and qtdemux: for ISOBMFF/QuickTime/MP4 files (often saved with the .mp4 extension)
mpegtsmux and tsdemux: for MPEG transport stream (MPEG-TS) files (often saved with the .ts extension)
Besides the fact that the demuxers are used for playback, by also adding support to VVC in the muxer elements we are then also able to perform remuxing: changing the container format without transcoding the underlying streams.
Some examples of simplified re-muxing pipelines (only taking into account the VVC video stream):
But why do we need h266parse when re-muxing from Matroska to MPEG-TS? That’s what I’ll explain in the next section.
Parsing and converting between VVC bitstream formats #
Video codecs like H.264, H.265, H.266 and AV1 may have different stream formats, depending on which container format is used to transport them. For VVC specifically, there are two main variants, as shown in the caps for h266parse:
Pad Templates: SINK template:'sink' Availability: Always Capabilities: video/x-h266
byte-stream or so-called Annex-B format (as in Annex B from the VVC specification): it separates the NAL units by start code prefixes (0x000001 or 0x00000001), and is the format used in MPEG-TS, or also when storing VVC bitstreams in files without containers (so-called “raw bitstream files”).
ℹ️ Note: It’s also possible to play raw VVC bitstream files with gst-play-1.0. That is achieved by the typefind element detecting the input file as VVC and playbin taking care of auto-plugging the elements.
vvc1 and vvi1: those formats use length field prefixes before each NAL unit. The difference between the two formats is the way that parameter sets (e.g. SPS, PPS, VPS NALs) are stored, and reflected in the codec_data field in GStreamer caps. For vvc1, the parameter sets are stored as container-level metadata, while vvi1 allows for the parameter sets to be stored also in the video bitstream.
The alignment field in the caps signals whether h266parse will collect multiple NALs into an Access Unit (AU) for a single GstBuffer, where an AU is the smallest unit for a decodable video frame, or whether each buffer will carry only one NAL.
That explains why we needed the h266parse when converting from MKV to MPEG-TS: it’s converting from vvc1/vvi1 to byte-stream! So the gst-launch-1.0 command with more explicit caps would be:
FFmpeg 7.1 has a native VVC decoder which is considered stable. In GStreamer 1.26, we have allowlisted that decoder in gst-libav, and it is now exposed as the avdec_h266 element.
Intel has added the vah266dec element in GStreamer 1.26, which enables hardware-accelerated VVC decoding on Intel Lunar Luke CPUs. However, it still has rank of 0 in GStreamer 1.26, so in order to test it out, one would need to, for example, manually set GST_PLUGIN_FEATURE_RANK.
Similar to h266parse, initially vah266dec was added with support for only the byte-stream format. I implemented support for the vvc1 and vvi1 modes in the base h266decoder class, which fixes the support for them in vah266dec as well. However, it hasn’t yet been merged and I don’t expect it to be backported to 1.26, so likely it will only be available in GStreamer 1.28.
Here’s a quick demo of vah266dec in action on an ASUS ExpertBook P5. In this screencast, I perform the following actions:
Run vainfo and display the presence of VVC decoding profile
gst-inspect vah266dec
export GST_PLUGIN_FEATURE_RANK='vah266dec:max'
Start playback of six simultaneous 4K@60 DASH VVC streams. The stream in question is the classic Tears of Steel, sourced from the DVB VVC test streams.
Run nvtop, showing GPU video decoding & CPU usage per process.
A tool that is handy for testing the new decoder elements is Fluster. It simplifies the process of testing decoder conformance and comparing decoders by using test suites that are adopted by the industry. It’s worth checking it out, and it’s already common practice to test new decoders with this test framework. I added the GStreamer VVC decoders to it: vvdec, avdec_h266 and vah266dec.
We’re still missing the ability to encode VVC video in GStreamer. I have a work-in-progress branch that adds the vvenc element, by using VVenC and safe Rust bindings (similarly to the vvdec element), but it still needs some work. I intend to work on it during the GStreamer Spring Hackfest 2025 to make it ready to submit upstream 🤞
2025 was my first year at FOSDEM, and I can say it was an incredible experience
where I met many colleagues from Igalia who live around
the world, and also many friends from the Linux display stack who are part of
my daily work and contributions to DRM/KMS. In addition, I met new faces and
recognized others with whom I had interacted on some online forums and we had
good and long conversations.
During FOSDEM 2025 I had the opportunity to present
about kworkflow in the kernel devroom. Kworkflow is a
set of tools that help kernel developers with their routine tasks and it is the
tool I use for my development tasks. In short, every contribution I make to the
Linux kernel is assisted by kworkflow.
The goal of my presentation was to spread the word about kworkflow. I aimed to
show how the suite consolidates good practices and recommendations of the
kernel workflow in short commands. These commands are easily configurable and
memorized for your current work setup, or for your multiple setups.
For me, Kworkflow is a tool that accommodates the needs of different agents in
the Linux kernel community. Active developers and maintainers are the main
target audience for kworkflow, but it is also inviting for users and user-space
developers who just want to report a problem and validate a solution without
needing to know every detail of the kernel development workflow.
Something I didn’t emphasize during the presentation but would like to correct
this flaw here is that the main author and developer of kworkflow is my
colleague at Igalia, Rodrigo Siqueira. Being honest,
my contributions are mostly on requesting and validating new features, fixing
bugs, and sharing scripts to increase feature coverage.
So, the video and slide deck of my FOSDEM presentation are available for
download
here.
And, as usual, you will find in this blog post the script of this presentation
and more detailed explanation of the demo presented there.
Kworkflow at FOSDEM 2025: Speaker Notes and Demo
Hi, I’m Melissa, a GPU kernel driver developer at Igalia and today I’ll be
giving a very inclusive talk to not let your motivation go by saving time with
kworkflow.
So, you’re a kernel developer, or you want to be a kernel developer, or you
don’t want to be a kernel developer. But you’re all united by a single need:
you need to validate a custom kernel with just one change, and you need to
verify that it fixes or improves something in the kernel.
And that’s a given change for a given distribution, or for a given device, or
for a given subsystem…
Look to this diagram and try to figure out the number of subsystems and related
work trees you can handle in the kernel.
So, whether you are a kernel developer or not, at some point you may come
across this type of situation:
There is a userspace developer who wants to report a kernel issue and says:
Oh, there is a problem in your driver that can only be reproduced by running this specific distribution.
And the kernel developer asks:
Oh, have you checked if this issue is still present in the latest kernel version of this branch?
But the userspace developer has never compiled and installed a custom kernel
before. So they have to read a lot of tutorials and kernel documentation to
create a kernel compilation and deployment script. Finally, the reporter
managed to compile and deploy a custom kernel and reports:
Sorry for the delay, this is the first time I have installed a custom kernel.
I am not sure if I did it right, but the issue is still present in the kernel
of the branch you pointed out.
And then, the kernel developer needs to reproduce this issue on their side, but
they have never worked with this distribution, so they just created a new
script, but the same script created by the reporter.
What’s the problem of this situation? The problem is that you keep creating new
scripts!
Every time you change distribution, change architecture, change hardware,
change project - even in the same company - the development setup may change
when you switch to a different project, you create another script for your new
kernel development workflow!
You know, you have a lot of babies, you have a collection of “my precious
scripts”, like Sméagol (Lord of the Rings) with the precious ring.
Instead of creating and accumulating scripts, save yourself time with
kworkflow. Here is a typical script that many of you may have. This is a
Raspberry Pi 4 script and contains everything you need to memorize to compile
and deploy a kernel on your Raspberry Pi 4.
With kworkflow, you only need to memorize two commands, and those commands are
not specific to Raspberry Pi. They are the same commands to different
architecture, kernel configuration, target device.
What is kworkflow?
Kworkflow is a collection of tools and software combined to:
Optimize Linux kernel development workflow.
Reduce time spent on repetitive tasks, since we are spending our lives
compiling kernels.
Standardize best practices.
Ensure reliable data exchange across kernel workflow. For example: two people
describe the same setup, but they are not seeing the same thing, kworkflow
can ensure both are actually with the same kernel, modules and options enabled.
I don’t know if you will get this analogy, but kworkflow is for me a megazord
of scripts. You are combining all of your scripts to create a very powerful
tool.
What is the main feature of kworflow?
There are many, but these are the most important for me:
Build & deploy custom kernels across devices & distros.
Handle cross-compilation seamlessly.
Manage multiple architecture, settings and target devices in the same work tree.
Organize kernel configuration files.
Facilitate remote debugging & code inspection.
Standardize Linux kernel patch submission guidelines. You don’t need to
double check documentantion neither Greg needs to tell you that you are not
following Linux kernel guidelines.
Upcoming: Interface to bookmark, apply and “reviewed-by” patches from
mailing lists (lore.kernel.org).
This is the list of commands you can run with kworkflow.
The first subset is to configure your tool for various situations you may face
in your daily tasks.
We have some tools to manage and interact with target machines.
# Manage and interact with target machines
kw ssh (s) - SSH support
kw remote (r) - Manage machines available via ssh
kw vm - QEMU support
To inspect and debug a kernel.
# Inspect and debug
kw device - Show basic hardware information
kw explore (e) - Explore string patterns in the work tree and git logs
kw debug - Linux kernel debug utilities
kw drm - Set of commands to work with DRM drivers
To automatize best practices for patch submission like codestyle, maintainers
and the correct list of recipients and mailing lists of this change, to ensure
we are sending the patch to who is interested in it.
# Automatize best practices for patch submission
kw codestyle (c) - Check code style
kw maintainers (m) - Get maintainers/mailing list
kw send-patch - Send patches via email
And the last one, the upcoming patch hub.
# Upcoming
kw patch-hub - Interact with patches (lore.kernel.org)
How can you save time with Kworkflow?
So how can you save time building and deploying a custom kernel?
First, you need a .config file.
Without kworkflow: You may be manually extracting and managing .config
files from different targets and saving them with different suffixes to link
the kernel to the target device or distribution, or any descriptive suffix to
help identify which is which. Or even copying and pasting from somewhere.
With kworkflow: you can use the kernel-config-manager command, or simply
kw k, to store, describe and retrieve a specific .config file very easily,
according to your current needs.
Then you want to build the kernel:
Without kworkflow: You are probably now memorizing a combination of
commands and options.
With kworkflow: you just need kw b (kw build) to build the kernel with
the correct settings for cross-compilation, compilation warnings, cflags,
etc. It also shows some information about the kernel, like number of modules.
Finally, to deploy the kernel in a target machine.
Without kworkflow: You might be doing things like: SSH connecting to the
remote machine, copying and removing files according to distributions and
architecture, and manually updating the bootloader for the target distribution.
With kworkflow: you just need kw d which does a lot of things for you,
like: deploying the kernel, preparing the target machine for the new
installation, listing available kernels and uninstall them, creating a tarball,
rebooting the machine after deploying the kernel, etc.
You can also save time on debugging kernels locally or remotely.
Without kworkflow: you do: ssh, manual setup and traces enablement,
copy&paste logs.
With kworkflow: more straighforward access to debug utilities: events,
trace, dmesg.
You can save time on managing multiple kernel images in the same work tree.
Without kworkflow: now you can be cloning multiple times the same
repository so you don’t lose compiled files when changing kernel
configuration or compilation options and manually managing build and deployment
scripts.
With kworkflow: you can use kw env to isolate multiple contexts in the
same worktree as environments, so you can keep different configurations in
the same worktree and switch between them easily without losing anything from
the last time you worked in a specific context.
Finally, you can save time when submitting kernel patches. In kworkflow, you
can find everything you need to wrap your changes in patch format and submit
them to the right list of recipients, those who can review, comment on, and
accept your changes.
This is a demo that the lead developer of the kw patch-hub feature sent me.
With this feature, you will be able to check out a series on a specific mailing
list, bookmark those patches in the kernel for validation, and when you are
satisfied with the proposed changes, you can automatically submit a reviewed-by
for that whole series to the mailing list.
Demo
Now a demo of how to use kw environment to deal with different devices,
architectures and distributions in the same work tree without losing compiled
files, build and deploy settings, .config file, remote access configuration and
other settings specific for those three devices that I have.
Setup
Three devices:
laptop (debian
x86
intel
local)
SteamDeck (steamos
x86
amd
remote)
RaspberryPi 4 (raspbian
arm64
broadcomm
remote)
Goal: To validate a change on DRM/VKMS using a single kernel tree.
Kworkflow commands:
kw env
kw d
kw bd
kw device
kw debug
kw drm
Demo script
In the same terminal and worktree.
First target device: Laptop (debian|x86|intel|local)
$ kw env --list # list environments available in this work tree
$ kw env --use LOCAL # select the environment of local machine (laptop) to use: loading pre-compiled files, kernel and kworkflow settings.
$ kw device # show device information
$ sudo modinfo vkms # show VKMS module information before applying kernel changes.
$ <open VKMS file and change module info>
$ kw bd # compile and install kernel with the given change
$ sudo modinfo vkms # show VKMS module information after kernel changes.
$ git checkout -- drivers
Second target device: RaspberryPi 4 (raspbian|arm64|broadcomm|remote)
$ kw env --use RPI_64 # move to the environment for a different target device.
$ kw device # show device information and kernel image name
$ kw drm --gui-off-after-reboot # set the system to not load graphical layer after reboot
$ kw b # build the kernel with the VKMS change
$ kw d --reboot # deploy the custom kernel in a Raspberry Pi 4 with Raspbian 64, and reboot
$ kw s # connect with the target machine via ssh and check the kernel image name
$ exit
Third target device: SteamDeck (steamos|x86|amd|remote)
$ kw env --use STEAMDECK # move to the environment for a different target device
$ kw device # show device information
$ kw debug --dmesg --follow --history --cmd="modprobe vkms" # run a command and show the related dmesg output
$ kw debug --dmesg --follow --history --cmd="modprobe -r vkms" # run a command and show the related dmesg output
$ <add a printk with a random msg to appear on dmesg log>
$ kw bd # deploy and install custom kernel to the target device
$ kw debug --dmesg --follow --history --cmd="modprobe vkms" # run a command and show the related dmesg output after build and deploy the kernel change
Q&A
Most of the questions raised at the end of the presentation were actually
suggestions and additions of new features to kworkflow.
The first participant, that is also a kernel maintainer, asked about two
features: (1) automatize getting patches from patchwork (or lore) and
triggering the process of building, deploying and validating them using the
existing workflow, (2) bisecting support. They are both very interesting
features. The first one fits well the patch-hub subproject, that is
under-development, and I’ve actually made a similar
request a couple of weeks
before the talk. The second is an already existing
request in kworkflow github
project.
Another request was to use kexec and avoid rebooting the kernel for testing.
Reviewing my presentation I realized I wasn’t very clear that kworkflow doesn’t
support kexec. As I replied, what it does is to install the modules and you can
load/unload them for validations, but for built-in parts, you need to reboot
the kernel.
Another two questions: one about Android Debug Bridge (ADB) support instead of
SSH and another about support to alternative ways of booting when the custom
kernel ended up broken but you only have one kernel image there. Kworkflow
doesn’t manage it yet, but I agree this is a very useful feature for embedded
devices. On Raspberry Pi 4, kworkflow mitigates this issue by preserving the
distro kernel image and using config.txt file to set a custom kernel for
booting. For ADB, there is no support too, and as I don’t see currently users
of KW working with Android, I don’t think we will have this support any time
soon, except if we find new volunteers and increase the pool of contributors.
The last two questions were regarding the status of b4 integration, that is
under development, and other debugging features that the tool doesn’t support
yet.
Finally, when Andrea and I were changing turn on the stage, he suggested to add
support for virtme-ng to kworkflow. So I
opened an issue for
tracking this feature request in the project github.
With all these questions and requests, I could see the general need for a tool
that integrates the variety of kernel developer workflows, as proposed by
kworflow. Also, there are still many cases to be covered by kworkflow.
Despite the high demand, this is a completely voluntary project and it is
unlikely that we will be able to meet these needs given the limited resources.
We will keep trying our best in the hope we can increase the pool of users and
contributors too.
In my previous post, when I introduced the switch to Skia for 2D rendering, I explained that we replaced Cairo with Skia keeping mostly the same architecture. This alone was an important improvement in performance, but still the graphics implementation was designed for Cairo and CPU rendering. Once we considered the switch to Skia as stable, we started to work on changes to take more advantage of Skia and GPU rendering to improve the performance even more. In this post I’m going to present some of those improvements and other not directly related to Skia and GPU rendering.
Explicit fence support
This is related to the DMA-BUF renderer used by the GTK port and WPE when using the new API. The composited buffer is shared as a DMA-BUF between the web and UI processes. Once the web process finished the composition we created a fence and waited for it, to make sure that when the UI process was notified that the composition was done the buffer was actually ready. This approach was safe, but slow. In 281640@main we introduced support for explicit fencing to the WPE port. When possible, an exportable fence is created, so that instead of waiting for it immediately, we export it as a file descriptor that is sent to the UI process as part of the message that notifies that a new frame has been composited. This unblocks the web process as soon as composition is done. When supported by the platform, for example in WPE under Wayland when the zwp_linux_explicit_synchronization_v1 protocol is available, the fence file descriptor is passed to the platform implementation. Otherwise, the UI process asynchronously waits for the fence by polling the file descriptor before passing the buffer to the platform. This is what we always do in the GTK port since 281744@main. This change improved the score of all MotionMark tests, see for example multiply.
Enable MSAA when available
In 282223@main we enabled the support for MSAA when possible in the WPE port only, because this is more important for embedded devices where we use 4 samples providing good enough quality with a better performance. This change improved the Motion Mark tests that use 2D canvas like canvas arcs, paths and canvas lines. You can see here the change in paths when run in a RaspberryPi 4 with WPE 64 bits.
Avoid textures copies in accelerated 2D canvas
As I also explained in the previous post, when 2D canvas is accelerated we now use a dedicated layer that renders into a texture that is copied to be passed to the compositor. In 283460@main we changed the implementation to use a CoordinatedPlatformLayerBufferNativeImage to handle the canvas texture and avoid the copy, directly passing the texture to the compositor. This improved the MotionMark tests that use 2D canvas. See canvas arcs, for example.
Introduce threaded GPU painting mode
In the initial implementation of the GPU rendering mode, layers were painted in the main thread. In 287060@main we moved the rendering task to a dedicated thread when using the GPU, with the same threaded rendering architecture we have always used for CPU rendering, but limited to 1 worker thread. This improved the performance of several MotionMark tests like images, suits and multiply. See images.
Update default GPU thread settings
Parallelization is not so important for GPU rendering compared to CPU, but still we realized that we got better results by increasing a bit the amount of worker threads when doing GPU rendering. In 290781@main we increased the limit of GPU worker threads to 2 for systems with at least 4 CPU cores. This improved mainly images and suits in MotionMark. See suits.
Hybrid threaded CPU+GPU rendering mode
We had either GPU or CPU worker threads for layer rendering. In systems with 4 CPU cores or more we now have 2 GPU worker threads. When those 2 threads are busy rendering, why not using the CPU to render other pending tiles? And the same applies when doing CPU rendering, when all workers are busy, could we use the GPU to render other pending tasks? We tried and turned out to be a good idea, especially in embedded devices. In 291106@main we introduced the hybrid mode, giving priority to GPU or CPU workers depending on the default rendering mode, and also taking into account special cases like on HiDPI, where we are always scaling, and we always prefer the GPU. This improved multiply, images and suits. See images.
Use Skia API for display list implementation
When rendering with Cairo and threaded rendering enabled we use our own implementation of display lists specific to Cairo. When switching to Skia we thought it was a good idea to use the WebCore display list implementation instead, since it’s cross-platform implementation shared with other ports. But we realized this implementation is not yet ready to support multiple threads, because it holds references to WebCore objects that are not thread safe. Main thread might change those objects before they have been processed by painting threads. So, we decided to try to use the Skia API (SkPicture) that supports recording in the main thread and replaying from worker threads. In 292639@main we replaced the WebCore display list usage by SkPicture. This was expected to be a neutral change in terms of performance but it surprisingly improved several MotionMark tests like leaves, multiply and suits. See leaves.
Use Damage to track the dirty region of GraphicsLayer
Every time there’s a change in a GraphicsLayer and it needs to be repainted, it’s notified and the area that changed is included so that we only render the parts of the layer that changed. That’s what we call the layer dirty region. It can happen that when there are many small updates in a layer we end up with lots of dirty regions on every layer flush. We used to have a limit of 32 dirty regions per layer, so that when more than 32 are added we just united them into the first dirty area. This limit was removed because we always unite the dirty areas for the same tiles when processing the updates to prepare the rendering tasks. However, we also tried to avoid handling the same dirty region twice, so every time a new dirty region was added we iterated the existing regions to check if it was already present. Without the 32 regions limit that means we ended up iterating a potentially very long list on every dirty region addition. The damage propagation feature uses a Damage class to efficiently handle dirty regions, so we thought we could reuse it to track the layer dirty region, bringing back the limit but uniting in a more efficient way than using always the first dirty area of the list. It also allowed to remove check for duplicated area in the list. This change was added in 292747@main and improved the performance of MotionMark leaves and multiply tests. See leaves.
Record all dirty tiles of a layer once
After the switch to use SkPicture for the display list implementation, we realized that this API would also allow to record the graphics layer once, using the bounding box of the dirty region, and then replay multiple times on worker threads for every dirty tile. Recording can be a very heavy operation, specially when there are shadows or filters, and it was always done for every tile due to the limitations of the previous display list implementation. In 292929@main we introduced the change with improvements in MotionMark leaves and multiply tests. See multiply.
MotionMark results
I’ve shown here the improvements of these changes in some of the MotionMark tests. I have to say that some of those changes also introduced small regressions in other tests, but the global improvement is still noticeable. Here is a table with the scores of all tests before these improvements and current main branch run by WPE MiniBrowser in a RaspberryPi 4 (64bit).
Test
Score July 2024
Score April 2025
Multiply
501.17
684.23
Canvas arcs
140.24
828.05
Canvas lines
1613.93
3086.60
Paths
375.52
4255.65
Leaves
319.31
470.78
Images
162.69
267.78
Suits
232.91
445.80
Design
33.79
64.06
What’s next?
There’s still quite a lot of room for improvement, so we are already working on other features and exploring ideas to continue improving the performance. Some of those are:
Damage tracking: this feature is already present, but disabled by default because it’s still work in progress. We currently use the damage information to only paint the areas of every layer that changed. But then we always compose a whole frame inside WebKit that is passed to the UI process to be presented on screen. It’s possible to use the damage information to improve both, the composition inside WebKit and the presentation of the composited frame on the screen. For more details about this feature read Pawel’s awesome blog post about it.
Use DMA-BUF for tile textures to improve pixel transfer operations: We currently use DMA-BUF buffers to share the composited frame between the web and UI process. We are now exploring the idea of using DMA-BUF also for the textures used by the WebKit compositor to generate the frame. This would allow to improve the performance of pixel transfer operations, for example when doing CPU rendering we need to upload the dirty regions from main memory to a compositor texture on every composition. With DMA-BUF backed textures we can map the buffer into main memory and paint with the CPU directly into the mapped buffer.
Compositor synchronization: We plan to try to improve the synchronization of the WebKit compositor with the system vblank and the different sources of composition (painted layers, video layers, CSS animations, WebGL, etc.)
Damage propagation is an optional WPE/GTK WebKit feature that — when enabled — reduces browser’s GPU utilization at the expense of increased CPU and memory utilization. It’s very useful especially in the context of low- and mid-end
embedded devices, where GPUs are most often not too powerful and thus become a performance bottleneck in many applications.
In computer graphics, the damage term is usually used in the context of repeatable rendering and means essentially “the region of a rendered scene that changed and requires repainting”.
In the context of WebKit, the above definition may be specialized a bit as WebKit’s rendering engine is about rendering web content to frames (passed further to the platform) in response to changes within a web page.
Thus the definition of WebKit’s damage refers, more specifically, to “the region of web page view that changed since previous frame and requires repainting”.
On the implementation level, the damage is almost always a collection of rectangles that cover the changed region. This is exactly the case for WPE and GTK WebKit ports.
To better understand what the above means, it’s recommended to carefully examine the below screenshot of GTK MiniBrowser as it depicts the rendering of the poster circle demo
with the damage visualizer activated:
In the image above, one can see the following elements:
the web page view — marked with a rectangle stroked to magenta color,
the damage — marked with red rectangles,
the browser elements — everything that lays above the rectangle stroked to a magenta color.
What the above image depicts in practice, is that during that particular frame rendering, the area highlighted red (the damage) has changed and needs to be repainted. Thus — as expected — only the moving parts of the demo require repainting.
It’s also worth emphasizing that in that case, it’s also easy to see how small fraction of the web page view requires repainting. Hence one can imagine the gains from the reduced amount of painting.
Normally, the job of the rendering engine is to paint the contents of a web page view to a frame (or buffer in more general terms) and provide such rendering result to the platform on every scene rendering iteration —
which usually is 60 times per second.
Without the damage propagation feature, the whole frame is marked as changed (the whole web page view) always. Therefore, the platform has to perform the full update of the pixels it has 60 times per second.
While in most of the use cases, the above approach is good enough, in the case of embedded devices with less powerful GPUs, this can be optimized. The basic idea is to produce the frame along with the damage information i.e. a hint for
the platform on what changed within the produced frame. With the damage provided (usually as an array of rectangles), the platform can optimize a lot of its operations as — effectively — it can
perform just a partial update of its internal memory. In practice, this usually means that fewer pixels require updating on the screen.
For the above optimization to work, the damage has to be calculated by the rendering engine for each frame and then propagated along with the produced frame up to its final destination. Thus the damage propagation can be summarized
as continuous damage calculation and propagation throughout the web engine.
Once the general idea has been highlighted, it’s possible to examine the damage propagation in more detail. Before reading further, however, it’s highly recommended for the reader to go carefully through the
famous “WPE Graphics architecture” article that gives a good overview of the WebKit graphics pipeline in general and which introduces the basic terminology
used in that context.
The information on the visual changes within the web page view has to travel a very long way before it reaches the final destination. As it traverses the thread and process boundaries in an orderly manner, it can be summarized
as forming a pipeline within the broader graphics pipeline. The image below presents an overview of such damage propagation pipeline:
This pipeline starts with the changes to the web page view visual state (RenderTree) being triggered by one of many possible sources. Such sources may include:
User interactions — e.g. moving mouse cursor around (and hence hovering elements etc.), typing text using keyboard etc.
Web API usage — e.g. the web page changing DOM, CSS etc.
multimedia — e.g. the media player in a playing state,
and many others.
Once the changes are induced for certain RenderObjects, their visual impact is calculated and encoded as rectangles called dirty as they
require re-painting within a GraphicsLayer the particular RenderObject
maps to. At this point, the visual changes may simply be called layer damage as the dirty rectangles are stored in the layer coordinate space and as they describe what changed within that certain layer since the last frame was rendered.
The next step in the pipeline is passing the layer damage of each GraphicsLayer
(GraphicsLayerCoordinated) to the WebKit’s compositor. This is done along with any other layer
updates and is mostly covered by the CoordinatedPlatformLayer.
The “coordinated” prefix of that name is not without meaning. As threaded accelerated compositing is usually used nowadays, passing the layer damage to the WebKit’s compositor must be coordinated between the main thread and
the compositor thread.
When the layer damage of each layer is passed to the WebKit’s compositor, it’s stored in the TextureMapperLayer that corresponds to the given
layer’s CoordinatedPlatformLayer. With that — and with all other layer-level updates — the
WebKit’s compositor can start computing the frame damage i.e. damage that is the final damage to be passed to the very end of the pipeline.
The first step to building frame damage is to process the layer updates. Layer updates describe changes of various layer properties such as size, position, transform, opacity, background color, etc. Many of those updates
have a visual impact on the final frame, therefore a portion of frame damage must be inferred from those changes. For example, a layer’s transform change that effectively changes the layer position means that the layer
visually disappears from one place and appears in the other. Thus the frame damage has to account for both the layer’s old and new position.
Once the layer updates are processed, WebKit’s compositor has a full set of information to take the layer damage of each layer into account. Thus in the second step, WebKit’s compositor traverses the tree formed out of
TextureMapperLayer objects and collects their layer damages. Once the layer damage of a certain layer
is collected, it’s transformed from the layer coordinate space into a global coordinate space so that it can be added to the frame damage directly.
After those two steps, the frame damage is ready. At this point, it can be used for a couple of extra use cases:
for WebKit’s compositor itself to perform some extra optimizations — as will be explained in the WebKit’s compositor optimizations section,
for layout tests.
Eventually — regardless of extra uses — the WebKit’s compositor composes the frame and sends it (a handle to it) to the UI Process along with frame damage using the IPC mechanism.
In the UI process, there are basically two options determining frame damage destiny — it can be either consumed or ignored — depending on the platform-facing implementation. At the moment of writing:
At the moment of writing, the damage propagation feature is run-time-disabled by default (PropagateDamagingInformation feature flag) and compile-time enabled by default for GTK and WPE (with new platform API) ports.
Overall, the feature works pretty well in the majority of real-world scenarios. However, there are still some uncovered code paths that lead to visual glitches. Therefore it’s fair to say the feature is still a work in progress.
The work, however, is pretty advanced. Moreover, the feature is set to a testable state and thus it’s active throughout all the layout test runs on CI.
Not only the feature is tested by every layout test that tests any kind of rendering, but it also has quite a lot of dedicated layout tests.
Not to mention the unit tests covering the Damage class.
In terms of functionalities, when the feature is enabled it:
activates the damage propagation pipeline and hence propagates the damage up to the platform,
When the feature is enabled, the main goal is to activate the damage propagation pipeline so that eventually the damage can be provided to the platform. However, in reality, a substantial part of the pipeline is always active
regardless of the features being enabled or compiled. This part of the pipeline ends before the damage reaches
CoordinatedPlatformLayer and is always active because it was used for layer-level optimizations for a long time.
More specifically — this part of the pipeline existed long before the damage propagation feature and was using layer damage to optimize the layer painting to the intermediate surfaces.
Because of the above, when the feature is enabled, only the part of the pipeline that starts with CoordinatedPlatformLayer
is activated. It is, however, still a significant portion of the pipeline and therefore it implies additional CPU/memory costs.
When the feature is activated and the damage flows through the WebKit’s compositor, it creates a unique opportunity for the compositor to utilize that information and reduce the amount of painting/compositing it has to perform.
At the moment of writing, the GTK/WPE WebKit’s compositor is using the damage to optimize the following:
to apply global glScissor to define the smallest possible clipping rect for all the painting it does — thus reducing the amount of painting,
to reduce the amount of painting when compositing the tiles of the layers using tiled backing stores.
Detailed descriptions of the above optimizations are well beyond the scope of this article and thus will be provided in one of the next articles on the subject of damage propagation.
As mentioned in the above sections, the feature only works in the GTK and the new-platform-API-powered WPE ports. This means that:
In the case of GTK, one can use MiniBrowser or any up-to-date GTK-WebKit-derived browser to test the feature.
In the case of WPE with the new WPE platform API the cog browser cannot be used as it uses the old API. Therefore, one has to use MiniBrowser
with the --use-wpe-platform-api argument to activate the new WPE platform API.
Moreover, as the feature is run-time-disabled by default, it’s necessary to activate it. In the case of MiniBrowser, the switch is --features=+PropagateDamagingInformation.
For quick testing, it’s highly recommended to use the latest revision of WebKit@main with wkdev SDK container and with GTK port.
Assuming one has set up the container, the commands to build and run GTK’s MiniBrowser are as follows:
It’s also worth mentioning that WEBKIT_SHOW_DAMAGE=1 environment variable disables damage-driven GTK/WPE WebKit’s compositor optimizations and therefore some glitches that are seen without the envvar, may not be seen
when it is set. The URL to this presentation is a great example to explore various glitches that are yet to be fixed. To trigger them, it’s enough to navigate
around the presentation using top/right/down/left arrows.
This article was meant to scratch the surface of the broad, damage propagation topic. While it focused mostly on introducing basic terminology and describing the damage propagation pipeline in more detail,
it briefly mentioned or skipped completely the following aspects of the feature:
the problem of storing the damage information efficiently,
the damage-driven optimizations of the GTK/WPE WebKit’s compositor,
the most common use cases for the feature,
the benchmark results on desktop-class and embedded devices.
Therefore, in the next articles, the above topics will be examined to a larger extent.
The new WPE platform API is still not released and thus it’s not yet officially announced. Some information on it, however, is provided by
this presentation prepared for a WebKit contributors meeting.
The platform that the WebKit renders to depends on the WebKit port:
in case of GTK port, the platform is GTK so the rendering is done to GtkWidget,
in case of WPE port with new WPE platform API, the platform is one of the following:
wayland — in that case rendering is done to the system’s compositor,
DRM — in that case rendering is done directly to the screen,
headless — in that case rendering is usually done into memory buffer.
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
On the WebRTC front, basic support for Rapid Synchronization was added, along with a couple of spec coverage improvements (https://commits.webkit.org/293567@main, https://commits.webkit.org/293569@main).
Dispatch a "canceled" error event for all queued utterances in case of SpeechSynthesis.
Support for the Camera desktop portal was added recently, it will benefit mostly Flatpak apps using WebKitGTK, such as GNOME Web, for access to capture devices, which is a requirement for WebRTC support.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Work continued on porting the in-place wasm interpreter (IPInt) to 32-bits.
We have been working on bringing the Temporal implementation in JSC up to the current spec, and a step towards that goal was implemented in WebKit PR #43849. This PR changes how calendar annotation key parsing works; it doesn't change anything observable, but sets the groundwork for parsing calendar critical flags and unknown annotations.
Releases 📦️
The recent releases of WebKitGTK and WPE WebKit 2.48 introduced a number of improvements to performance, reduced resource usage, better support for web platform features and standards, multimedia, and more!
Read more about these updates in the freshly published articles for WebKitGTK, and WPE WebKit.
Pawel Lampe published a blog post on the damage propagation feature. This feature reduces browser's GPU utilization at the expense of increased CPU and memory utilization in the WPE and GTK WebKit ports.
Our efforts to bring GstWebRTC support to WebKitGTK and WPEWebKit also include direct contributions to GStreamer. We recently improved WebRTC spec compliance in webrtcbin, by making the SDP mid attribute optional in offers and answers.
Servo has shown that we can build a browser with a modern, parallel layout engine in a fraction of the cost of the big incumbents, thanks to our powerfultooling, our strong community, and our thorough documentation.
But we can, and should, build Servo without generative AI tools like GitHub Copilot.
This post is my personal opinion, not necessarily representative of Servo or my colleagues at Igalia.
I hope it makes a difference.
Recently the TSC voted in favour of two proposals that relax our ban on AI contributions.
This was a mistake, and it was also a mistake to wait until after we had made our decision to seek community feedback (see § On governance).
§ Your feedback made it clear that those proposals are the wrong way forward for Servo.
Correction (2025-04-12)
A previous version of this post highlighted a logic error in the AI-assisted patch we used as a basis for those two proposals.
This error was made in a non-AI-assisted part of the patch.
I call on the TSC to explicitly reaffirm that generative AI tools like Copilot are not welcome in Servo, and make it clear that we intend to keep it that way indefinitely, in both our policy and the community, so we can start rebuilding trust.
It’s not enough to say oops, sorry, we will not be moving forward with these proposals.
Like any logic written by humans, this policy does have some unintended consequences.
Our intent was to ban AI tools that generate bullshit [a] in inscrutable ways, including GitHub Copilot and ChatGPT.
But there are other tools that use similarunderlyingtechnology in more useful and less problematic ways (see § Potential exceptions).
Reviewing these tools for use in Servo should be a community-driven process.
We should not punish contributors for honest mistakes, but we should make our policy easier to follow.
Some ways to do this include documenting the tools that are known to be allowed and not allowed, documenting how to turn off features that are not allowed, and giving contributors a way to declare that they’ve read and followed the policy.
The declaration would be a good place to provide a dated link to the policy, giving contributors the best chance to understand the policy and knowingly follow it (or violate it).
This is not perfect, and it won’t always be easy to enforce, but it should give contributors and maintainers a foundation of trust.
Potential exceptions
Proposals for exceptions should start in the community, and should focus on a specific tool used for a specific purpose.
If the proposal is for a specific kind of tool, it must come with concrete examples of which tools are to be allowed.
Much of the harm being caused by generative AI in the world around us comes from people using open-ended tools that are not fit for any purpose, or even treating them like they are AGI.
The goal of these discussions would be to understand:
the underlying challenges faced by contributors
how effective the tool is for the purpose
how well the tool and purpose mitigate the issues in the policy
whether there are any existing or alternative solutions
whether those solutions have problems that need to be addressed
Sometimes the purpose may need to be constrained to mitigate the issues in the policy.
Let’s look at a couple of examples.
For some tasks like speech recognition[b] and machine translation[c][d], tools with large language models and transformers are the state of the art (other than humans).
This means those tools may be probabilistic tools, and strictly speaking, they may be generative AI tools, because the models they use are generative models.
Generative AI does not necessarily mean “AI that generates bullshit in inscrutable ways”.
Speech recognition can be used in a variety of ways.
If plumbed into ChatGPT, it will have all of the same problems as ChatGPT.
If used for automatic captions, it can make videos and calls accessible to people that can’t hear well (myself included), but it can also infantilise us by censoring profanities and make serious errors that cause real harm.
If deployed for that purpose by an online video platform, it can undermine the labour of human transcribers and lower the overall quality of captions.
If used as an input method, it would be a clear win for accessibility.
My understanding of speech input tools is that they have a clear (if configurable) mapping from the things you say to the text they generate or the edits they make, so they may be a good fit.
In that case, maintainer burden and correctness and security would not be an issue, because the author is in complete control of what they write.
Copyright issues seem less of a concern to me, since these tools operate on such a small scale (words and symbols) that they are unlikely to reproduce a copyrightable amount of text verbatim, but I am not a lawyer.
As for ethical issues, these tools are generally trained once then run on the author’s device.
When used as an input method, they are not being used to undermine labour or justify layoffs.
I’m not sure about the process of training their models.
Machine translation can also be used in a variety of ways.
If deployed by a language learning app, it can ruin the quality of your core product, but hey, then you can lay off those pesky human translators.
If used to localise your product, your users will finally be able to compress to postcode file.
If used to localise your docs, it can make your docs worse than useless unless you take very careful precautions.
What if we allowed contributors to use machine translation to communicate with each other, but not in code commits, documentation, or any other work products?
Deployed carelessly, they will waste the reader’s time, and undermine the labour of actual human translators who would otherwise be happy to contribute to Servo.
If constrained to collaboration, it would still be far from perfect, but it may be worthwhile.
Maintainer burden should be mitigated, because this won’t change the amount or kind of text that needs to be reviewed.
Correctness and security too, because this won’t change the text that can be committed to Servo.
I can’t comment on the copyright issues, because I am not a lawyer.
The ethical issues may be significantly reduced, because this use case wasn’t a market for human translators in the first place.
Your feedback
I appreciate the feedback you gave on the Fediverse, on Bluesky, and on Reddit.
I also appreciate the comments on GitHub from several people who were more on the favouringsideoftheproposal, even though we reached different conclusions in most cases.
One comment argued that it’s possible to use AI autocomplete safely by accepting the completions one word at a time.
That said, the overall consensus in our community was overwhelmingly clear, including among many of those who were in favour of the proposals.
None of the benefits of generative AI tools are worth the cost in community goodwill [e].
Much of the dissent on GitHub was already covered by our existing policy, but there were quite a few arguments worth highlighting.
Machine translation
is generally not useful or effective for technical writing [h][i][j].
It can be, if some precautions are taken [k].
It may be less ethically encumbered than generative AI tools [l].
Client-side machine translation is ok [m].
Machine translation for collaboration is ok [n][o].
The proposals.
Proposal 1 is ill-defined [p].
Proposal 2 has an ill-defined distinction between autocompletes and “full” code generation [q][r][s].
Documentation
is just as technical as code [u].
Wrong documentation is worse than no documentation [v][w][x].
Good documentation requires human context [y][z].
GitHub Copilot
is not a good tool for answering questions [ab].
It isn’t even that good of a programming tool [ac].
Using it may be incompatible with the DCO [ad].
Using it could make us depend on Microsoft to protect us against legal liability [ae].
Correctness.
Generative AI code is wrong at an alarming rate [af].
Generative AI tools will lie to us with complete confidence [ag].
Generative AI tools (and users of those tools) cannot explain their reasoning [ah][ai].
Humans as supervisors are ill-equipped to deal with the subtle errors that generative AI tools make [aj][ak][al][am].
Even experts can easily be misled by these tools [an].
Typing is not the hard part of programming [ao], as even some of those in favour have said:
If I could offload that part of the work to copilot, I would be left with more energy for the challenging part.
Project health.
Partially lifting the ban will create uncertainty that increases maintainer burden for all contributions [ap][aq].
Becoming dependent on tools with non-free models is risky [ar].
Generative AI tools may not be fair use [as] → [at].
Outside of Servo, people have spent so much time cleaning up after LLM-generated mess [au].
Material.
Servo contributor refuses to spend time cleaning up after LLM-generated mess [av].
Others will stop donating [aw][ax][ay][az][ba][bb][bc][bd][be][bf][bg], will stop contributing [bh], will not start donating [bi], will not start contributing [bj][bk], or will not start promoting [bl] the project.
Broader context.
Allowing AI contributions is a bad signal for the project’s relationship with the broader AI movement [bm][bn][bo].
The modern AI movement is backed by overwhelming capital interests, and must be opposed equally strongly [bp].
People often “need” GitHub or Firefox, but no one “needs” Servo, so we can and should be held to a higher standard [bq].
Rejection of AI is only credible if the project rejects AI contributions [br].
We can attract funding from AI-adjacent parties without getting into AI ourselves [bs], though that may be easier said than done [bt].
On governance
Several people have raised concerns about how Servo’s governance could have led to this decision, and some have even suspected foul play.
But like most discussions in the TSC, most of the discussion around AI contributions happened async on Zulip, and we didn’t save anything special for the synchronous monthly public calls.
As a result, whenever the discussion overflowed the sync meeting, we just continued it internally, so the public minutes were missing the vast majority of the discussion (and the decisions).
These decisions should probably have happened in public.
Our decisions followed the TSC’s usual process, with a strong preference for resolving disagreements by consensus rather than by voting, but we didn’t have any consistent structure for moving from one to the other.
This may have made the decision process prone to being blocked and dominated by the most persistent participants.
Contrast this with decision making within Igalia, where we also prefer consensus before voting, but the consensus process is always used to inform proposals that are drafted by more than one person and then always voted on.
Most polls are “yes” or “no” by majority, and only a few polls for the most critical matters allow vetoing.
This ensures that proposals have meaningful support before being considered, and if only one person is strongly against something, they are heard but they generally can’t single-handedly block the decision with debate.
The rules are actually more complex than just by majority.
There’s clear advice on what “yes”, “no”, and “abstain” actually mean, they take into account abstaining and undecided voters, there are set time limits and times to contact undecided voters, and they provide for a way to abort a poll if the wording of the proposal is ill-formed.
We had twenty years to figure out all those details, and one of the improvements above only landed a couple of months ago.
We also didn’t have any consistent structure for community consultation, so it wasn’t clear how or when we should seek feedback.
A public RFC process may have helped with this, and would also help us collaborate on and document other decisions.
More personally, I did not participate in the extensive discussion in January and February that helped move consensus in the TSC towards allowing the non-code and Copilot exceptions until fairly late.
Some of that was because I was on leave, including for the vote on the initial Copilot “experiments”, but most of it was that I didn’t have the bandwidth.
Doing politics is hard, exhausting work, and there’s only so much of it you can do, even when you’re not wearing three other hats.
I’m a little (okay, a lot) late to it, but meyerweb is now participating in CSS Naked Day — I’ve removed the site’s styles, except in cases where pages have embedded CSS, which I’m not going to do a find-and-replace to try to suppress. So if I embedded a one-off CSS Grid layout, like on the Toolbox page, that will still be in force. Also, cached files with CSS links could take a little time to clear out. Otherwise, you should get 1990-style HTML. Enjoy!
(The site’s design will return tomorrow, or whenever I remember [or am prodded] to restore it.)
Na Igalia, a gente trabalha com o desenvolvimento de navegadores da Internet, tipo Chrome e Safari. Na verdade, atuamos com as tecnologias por trás desses navegadores, que permitem que os sites tenham uma boa aparência e funcionem corretamente, como HTML, CSS e JavaScript—os blocos de construção de todas as aplicações da Internet.
Em tudo o que fazemos, tentamos dar grande ênfase à responsabilidade social. Isso significa que o nosso foco vai além do lucro, priorizando ações que geram um impacto positivo na sociedade. Além disso, a Igalia é construída com base em valores de igualdade e transparência, profundamente enraizados em nossa estrutura organizacional. Estes compromissos com valores e responsabilidade social moldam os princípios fundamentais que orientam o nosso trabalho.
Update on what happened in WebKit in the week from March 31 to April 7.
Cross-Port 🐱
Graphics 🖼️
By default we divide layers that need to be painted into 512x512 tiles, and
only paint the tiles that have changed. We record each layer/tile combination
into a SkPicture and replay the painting commands in worker threads, either
on the CPU or the GPU. A change was
landed to improve the algorithm,
by recording the changed area of each layer into a single SkPicture, and for
each tile replay the same picture, but clipped to the tile dimensions and
position.
WPE WebKit 📟
WPE Platform API 🧩
New, modern platform API that supersedes usage of libwpe and WPE backends.
A WPE Platform-based implementation of Media Queries' Interaction Media
Features, supporting
pointer and hover-related queries, has
landed in WPE WebKit.
When using the Wayland backend, this change exposes the current state of
pointing devices (mouse and touchscreen), dynamically reacting to changes such
as plugging or unplugging. When the new WPEPlatform API is not used, the
previous behaviour, defined at build time, is still used.
Adaptation of WPE WebKit targeting the Android operating system.
A number of fixes havebeenmerged to fix and improve building WPE WebKit for Android. This is part of an ongoing effort to make it possible to build WPE-Android using upstream WebKit without needing additional patches.
The example MiniBrowser included with WPE-Android has beenfixed to handle edge-to-edge layouts on Android 15.
At Igalia, we work on developing Internet browsers such as Chrome and Safari. In fact, we work with the technologies behind these browsers that allow websites to look good and function correctly, such as HTML, CSS, and JavaScript—the building blocks of all Internet applications.
In everything we do, we try to place a strong emphasis on social responsibility. This means that our focus goes beyond profit, prioritizing actions that generate a positive impact on society. Igalia is built on values of equality and transparency, which are deeply embedded in our organizational structure. These commitments to values and social responsibility shape the fundamental principles that guide our work.
Doing a 32-bit build on ARM64 hardware now works with GCC 11.x as well.
Graphics 🖼️
Landed a change that improves the painting of tile fragments in the compositor if damage propagation is enabled and if the tiles sizes are bigger than 256x256. In those cases, less GPU is utilized when damage allows.
The GTK and WPE ports no longer useDisplayList to serialize the painting commands and replay them in worker threads, but SkPictureRecorder/SkPicture from Skia. Some parts of the WebCore painting system, especially font rendering, are not thread-safe yet, and our current cross-thread use of DisplayList makes it harder to improve the current architecture without breaking GTK and WPE ports. This motivated the search for an alternative implementation.
Community & Events 🤝
Sysprof is now able to filter samples by marks. This allows for statistically relevant data on what's running when a specific mark is ongoing, and as a consequence, allows for better data analysis. You can read more here.
The other day was W3C Breakouts Day: Effectively, an opportunity for people to create sessions to talk about or work on anything related to the Web. We do this twice a year. Once entirely virtually (last week) and then again during hybrid meetings in association with W3C's biggest event of the year, called "TPAC".
This year there were 4 blocks of sessions with 4-5 sessions competing concurrently for the same time slot. There were 2 in the morning that I'd chosen, but then realized that I had calendar conflicts with other meetings and wound up missing them.
In the afternoon there were 3 sessions proposed by Igalians - unfortunately two of them simulteneously:
There were actually several in that timeslot that I wanted to attend but the choice was pretty straightforward: I'd attend mine and Eric's. Unfortunately I did a bad job chairing and forgot to assign a scribe or record a presentation.
Eric's session told the story of SVG and how, despite it getting a lot of love from developers and designers and other working group participants, it just didn't get a lot of love or investment from the browser vendors themselves. Amelia Belamy-Royd's (former editor/chair) told us about how things ultimately stalled out around 2020 with so much left undone, burnout, disappointments, and a W3C working group that was almost closed up with a note last year before being sort of "rescued" at the last minute with a very targeted rechartering. However, that rechartering still hasn't resulted in much - no new meetings, etc. We talked about how Igalia has been investing, along with companies like Wix, in trying to help move things forward. Then the question was: How can we move it forward, together? You can read the minutes for more, but one idea was a collective around SVG.
I mention this because while might they seem at first like pretty different topics, Eric's session and my own are really just two things raising the same overarching question: Why have we built the infrastructure of the whole web ecosystem to be fundamentally dependent on the funding and prioritization of a few private organizations?. And - how can we fix that?.
My session presented some things we've done, or tried so far.
Things we're trying...
First, just moving from proprietary projects to open source has helped a bit. Instead of one organization being 100% responsible, the stewards themselves today contribute "only" ~80 to 95% of the commits.
My company Igalia is among the top few committers to all of the web engine projects every year for at least half a decade, and we have many ways that we try to diversify work upstream. What's interesting about attempts to diversify funding is that there is a kind of a spectrum here relating to both the scope of what we're tackling and how well understood the approach is...
one sponsor/single issuecollective/whole project
On the left is a single sponsor with very specific/measurable tasks. This could be a list of bugs, or implementation of a pretty stable feature in a single engine. You can contract Igalia for stuff like this - The :has() implementation and proof-of-concept that moved the needle in Chromium, for example, was sponsored by EyeO. CSS Grid in Blink and WebKit was sponsored by Bloomberg Tech. We know how to do this. We've got lots of practice.
Moving slightly more 'right', we have things like our Open Priortization which is trying to decide how to prioritize and share a funding burden. We know less of how to do this, we learned things with the experiment, but we've not repeated it because it involved a lot of "extra" work.
Then there's our efforts with MathML, funded by grants, then partnerships, then a collective aimed at generally advancing and maintaining MathML support in browsers. That's now involving more decision making - there's not a tight list of tasks or even a specific browser. You need to take in money to find out how much budget you have, and then try to figure out how to use it. In this case, there's a steering committee made up of the biggest funders. Every 6 months or so there is a report of the work that was done submitted for payment. Is that a great model?
We also have Wolvic, which attempted to have partnerships and a collective, with a model where if you put in a kind of minimum amount every 6 months then you would get invited to a town hall to discuss how we'd prioritize the spending of available funds. Is that a great model? The thing I like about it is that it binds things to some kind of reality. It's great if someone gave $500, for example, but if 10 other orgs also did so and they all want different things, none of which we can do with the available funds... At least they can all help decide what to do. In that model, the input is still only informative - it's ultimately Igalia who decides.
Or, you might have seen a new thing hosted at the Linux Foundation for funding work in Chromium. That's more formal, but kind of similar in challenges. Unfortunately there was no one attending our sessions who could talk about it - I know a bit more, but I'm not going to break news on my blog :). We'll have a podcast about it when we can.
Or, a little further right there's Open Web Docs (OWD), which I'm pleased does seem to be succeeding at sponsoring some real work and doing real prioritization. Florian from OWD was there and was able to give us some real thoughts. They too are drawing now from grants like Soverign Tech Fund. They produce as part of this an Impact Report.
Or, maybe all the way to the right you have a general browser fund like Servo. There it is the Technical Steering Committee that decides what to do with the funds.
A lot of this thinking is currently still pretty esoteric because, for example, through the collective, Servo isn't taking in enough money for even a single full time employee. I also mentioned our work with Interop, and the fact that even with that level of effort to priortize, it is very difficult to not wind up taking resources away from actual work in order to figure out which work to potentially do! It's hard to not add admin costs that eat away at the overall progress. But that's exactly why we should be talking about these things now. How can we make this work?
The Actual Discussion
As I said, we didn't have a scribe, but there was some discussion I can attempt to summarize from the queue I can still see in IRC.
Q. Do you think the W3C has a role to play?
That's why I brought it here. My own desire would be yes. There are some venues where working groups and interest groups are encouraged to pool funds and so on - but the W3C isn't currently one of them and I'm unsure how others feel. It's a thing I have been trying to pitch for a few years now that we could figure out.
The Wolvic model that I described above was born from thoughts around this. What if W3C groups had the ability to put money into a common fund and then at the end of the year they could decide how to deploy it. Maybe sometimes that would be for tools. Maybe sometimes that would be for fixing bugs. Maybe sometimes that would be for new implementation, or last implementation, or supporting spec authorship. But it would always be grounded on something real about collaboration that puts at some degree of power beyond the implementers. Maybe that would mean that print CSS would inch along at a snail's pace - but at least it's better than not at all, and it shows a way. At least it doesn't seem like the group isn't even picking up the phone.
Q. Are engines like Servo and Ladybird filing implementation reports? WPT?
Basically... Not exactly. The main thrust is that both engines do make themselves available on Web Platform Tests and closely track their scores. That said, the models differ quite a bit in their approach and Ladybird, for example, generally is more focused from the outside in. It's possible they only start with 25% of the standard required to load a certain page. So, at what point would they submit an impact report? Both projects do currently open issues when they find implementation related questions or problems, and both have the ability to expand the test suites in response to those issues. So, effectively: Nobody has time for that level of formality, but they're following the spirit of it.
Q. Doesn't it help to have a thing you can measure if you approach someone to ask for money?
Yes, that is the whole point of my spectrum above. The further right you move, the more of a question this is. On our podcast, for example, we've asked people "Why don't you donate to Mozilla?" and the main answer given is always "I don't know what they'll spend it on, but probably not things I would agree with". The more people putting in, the more there is to balance or require trust. Currently a lot of these work for grants or more specific/finite problems which do reports of success - like the one I provided above for MathML or the implementation report in OWD.
But does it mean there shouldn't be more general funds? Currently the general funds come from default search and wind up with a single org to decide - is it what we want?
So, that's all that was discussed. All in all, it was pretty good - but I'm slightly disappointed there wasn't a little more discussion of how we could collectively govern or priortize, or even if we all agreed that that's something that we want. I'd love to hear any of your thoughts!
Linux 6.14 is the second release of 2025, and as usual Igalia took part on it. It’s a very normal release, except that it was release on Monday, instead of the usual Sunday release that has been going on for years now. The reason behind this? Well, quoting Linus himself:
I’d like to say that some important last-minute thing came up and
delayed things.
But no. It’s just pure incompetence.
But we did not forget about it, so here’s our Linux 6.14 blog post!
A part of the development cycle for this release happened during late December, when a lot of maintainers and developers were taking their deserved breaks. As a result of this, this release contains less changes than usual as stated by LWN as the “lowest level of merge-window activity seen in years”. Nevertheless, some cool features made through this release:
NT synchronization primitives: Elizabeth Figura, from Codeweavers, is know from her work around improving Wine sync functions, like mutexes and semaphores. She was one the main collaborators behind the futex_waitv() work and now developed a virtual driver that is more compliant with the precise semantics that the NT kernel exposes. This allows Wine to behave closer to Windows without the need to create new syscalls, since this driver uses ioctl() as the front-end uAPI.
RWF_UNCACHED: Linux has two ways of dealing with storage I/O: buffered I/O (usually the preferred one) that stores data in a temporary buffer and regularly syncs the cache data with the device; and direct I/O that doesn’t use cache and always writes/reads synchronously with the storage device. Now a new mixed approach is available: uncached buffered I/O. This method is aimed to have a fast way to write or read data that will not be needed again in the short term. For reading, the device writes data in the buffer and as soon as the user finished reading the buffer, it’s cleared from the cache. For writing, as soon as userspace fills the cache, the device reads it and removes it from the cache. In this way we still have the advantage of using a fast cache but reducing the cache pressure.
amdgpu panic support: AMD developers added kernel panic support for amdgpu driver, “which displays a pretty user friendly message on the screen when a Linux kernel panic occurs” instead of just a black screen or a partial dmesg log.
As usual Kernel Newbies provides a very good summary, you should check it for more details: Linux 6.14 changelog. Now let’s jump to see what were the merged contributions by Igalia for this release!
DRM
For the DRM common infrastructure, we helped to land a standardization for DRM client memory usage reporting. Additionally, we contributed to improve and fix bugs found in drivers of AMD, Intel, Broadcom, and Vivante.
AMDGPU
For the AMD driver, we fixed bugs experienced by users of Cosmic Desktop Environment on several AMD hardware versions. One was uncovered with the introduction of overlay cursor mode, and a definition mismatch across the display driver caused a page-fault in the usage of multiple overlay planes. Another bug was related to division by zero on plane scaling. Also, we fixed regressions on VRR and MST generated by the series of changes to migrate AMD display driver from open-coded EDID handling to drm_edid struct.
Intel
For the Intel drivers, we fixed a bug in the xe GPU driver which prevented certain type of workarounds from being applied, helped with the maintainership of the i915 driver, handled external code contributions, maintained the development branch and sent several pull requests.
Also in the V3D driver, the active performance monitor is now properly stopped before being destroyed, addressing a potential use-after-free issue. Additionally, support for a global performance monitor has been added via a new DRM_IOCTL_V3D_PERFMON_SET_GLOBAL ioctl. This allows all jobs to share a single, globally configured perfmon, enabling more consistent performance tracking and paving the way for integration with user-space tools such as perfetto.
A small video demo of perfetto integration with V3D
etnaviv
On the etnaviv side, fdinfo support has been implemented to expose memory usage statistics per file descriptor, enhancing observability and debugging capabilities for memory-related behavior.
sched_ext
Many BPF schedulers (e.g., scx_lavd) frequently call bpf_ktime_get_ns() for tracking tasks’ runtime properties. bpf_ktime_get_ns() eventually reads a hardware timestamp counter (TSC). However, reading a hardware TSC is not performant in some hardware platforms, degrading instructions per cycyle (IPC).
We addressed the performance problem of reading hardware TSC by leveraging the rq clock in the scheduler core, introducing a scx_bpf_now() function for BPF schedulers. Whenever the rq clock is fresh and valid, scx_bpf_now() provides the rq clock, which is already updated by the scheduler core, so it can reduce reading the hardware TSC. Using scx_bpf_now() reduces the number of reading hardware TSC by 50-80% (e.g., 76% for scx_lavd).
Assorted kernel fixes
Continuing our efforts on cleaning up kernel bugs, we provided a few fixes that address issues reported by syzbot with the goal of increasing stability and security, leveraging the fuzzing capabilities of syzkaller to bring to the surface certain bugs that are hard to notice otherwise. We’re addressing bug reports from different kernel areas, including drivers and core subsystems such as the memory manager. As part of this effort, several fixes were done for the probe path of the rtlwifi driver.
Check the complete list of Igalia’s contributions for the 6.14 release
The February TC39 meeting in Seattle wrapped up with significant updates and advancements in ECMAScript, setting an exciting trajectory for the language's evolution. Here are the key highlights, proposal advancements, and lively discussions from the latest plenary.
The following proposals advanced to stage 4 early in the meeting, officially becoming a part of ECMAScript 2025. Congratulations to the people who shepherded them through the standardization process!
Float16Array: a typed array that uses 16-bit floating point values, mostly for interfacing with other systems that need 16-bit float arrays.
Champions: Leo Balter, Kevin Gibbons
RegExp.escape(): Sanitizes a string so that it can be used as a string literal pattern for the RegExp constructor.
Champions: Kevin Gibbons, Jordan Harband
Redeclarable global eval vars simplifies the mental model of global properties. It's no longer an error to redeclare a var or function global property with a let or const of the same name.
Now with full test262 coverage, the import defer proposal advanced to stage 3, without changes since its previous presentation. This is the signal for implementors to go ahead and implement it. This means that the proposal is likely to appear soon in browsers!
To clamp a number x to an interval [a, b] means to produce a value no smaller than a and no greater than b (returning x if x is in the interval). Oliver Medhurst presented a neat little proposal to add this feature to JS's Math standard library object. And Oliver was able to convince the committee to advance the discussion to stage 1.
Instances of Error and its subclasses have a stack property that returns a string representing the stack trace. However, this property is not specified, and previous attempts to define it in the spec did not get far because different JS engines have different string representations for the stack trace, and implementations can't converge on one behavior because there's code in the wild that does browser detection to know how to parse the format.
In December it was decided that specifying the presence of a stack property should be split off of the error stack proposal. This new error stack accessor proposal was first presented in this plenary, where it reached stage 2. The proposal achieves some amount of browser alignment on some details (e.g. is stack an own property? is it a getter/setter pair?), while also providing a specified base on which other proposals and web specs can build, but it leaves the stack trace string implementation-defined.
New TC39 contributor ZiJian Liu offered a suggestion for tackling a problem routinely faced by JS programmers who work closely with numbers:
"Am I sure that this numeric string S, if interpreted as a JS number, is going to be exactly preserved?"
The proposal is a new method on Numbers, isSafeNumeric, that would allow us to check this in advance. Essentially, ZiJian is trying to delimit a safe space for JS numbers. The discussion was heated, with many in the committee not sure what it actually means for a numeric string to be "preserved", and whether it can even be solved at all. Others thought that, although there may be no solution, it's worth advancing the proposal to stage 1 to begin to explore the space. Ultimately, the proposal did not advance to stage 1, but that doesn't mean it's the end—this topic may well come back in a sharper, more clearly defined form later on.
Temporal, the upcoming proposal for better date and time support in JS, has been seeing a surge of interest in the last few weeks because of a complete implementation being available in Firefox Nightly. Folks seem to be looking forward to using it in their codebases!
Our colleague Philip Chimento presented a status update. Firefox is at ~100% conformance with just a handful of open questions, and the Ladybird browser is the next closest to shipping a full implementation, at 97% conformance with the test suite.
The committee also reached consensus on making a minor change to the proposal which relaxed the requirements on JS engines when calculating lunar years far in the future or past.
Philip also presented a status update on the ShadowRealm proposal. ShadowRealm is a mechanism that lets you execute JavaScript code synchronously, in a fresh, isolated environment. This has a bunch of useful applications such as running user-supplied plugins without letting them destabilize your app, or prevention of supply chain attacks in your dependencies.
We think we have resolved all of the open questions on the TC39 side, but what remains is to gauge the interest in implementing the web integration parts. We had a lively discussion on what kinds of use cases we'd like to see in TC39 versus what kinds of use cases the web platform world would like to see.
Champions: Dave Herman, Caridy Patiño, Mark S. Miller, Leo Balter, Rick Waldron, Chengzhong Wu
Implementations of the decorators proposal are in progress: the Microsoft Edge team has an almost complete implementation on top of Chromium's V8 engine, and Firefox's implementation is in progress.
Although there are two implementations in progress, it has been stated that none of the three major browsers want to be the first one to ship among them, leaving the future of the proposal uncertain.
There was some progress on proposals related to ArrayBuffers. One topic was about the Immutable ArrayBuffer proposal, which allows creating ArrayBuffers in JS from read-only data, and in some cases allows zero-copy optimizations. The proposal advanced to stage 2.7.
Champions: Mark S. Miller, Peter Hoddie, Richard Gibson, Jack Works
In light of that, the committee considered whether or not it made sense to withdraw the Limited ArrayBuffer proposal (read-only views of mutable buffers). It was not withdrawn and remains at stage 1.
The well-known symbols Symbol.match, Symbol.matchAll, Symbol.replace, Symbol.search and Symbol.split allow an arbitrary object to be passed as the argument to the corresponding string methods and behave like a custom RegExp. However, these methods don't check that the argument is an object, so you could make "foo bar".split(" ") have arbitrary behavior by setting String.prototype[Symbol.split].
This is an issue especially for Node.js and Deno, since a lot of their internal code is written in JavaScript. They use primordials to guard their internal code from userland monkeypatching, but guarding against overriding the matching behavior of strings could lead to performance issues.
The proposed solution was to have the relevant string methods only look for these well-known symbols if the argument is an object, rather than doing so for all primitives other than null or undefined. This is technically a breaking change, but it's not expected to lead to web compatibility issues in the wild because of how niche these symbols are. Given that, the committee reached consensus on making this change.
The Records and Tuples proposal has been stuck at stage 2 for long time, due to significant concerns around unrealistic performance expectations. The committee again discussed the proposal, and how to rewrite it to introduce some of its capabilities to the language without falling into the same performance risks.
You can read more details on GitHub, but the summary is that Records and Tuples might become:
objects, rather than primitives
shallowly immutable, rather than enforcing deep immutability
using an equals() method rather than relying on === for recursive comparison
have special handling in Map/Set, easily allowing multi-value keys.
In discussions surrounding the topic of decimal, it has become increasingly clear that it overlaps with the measure proposal (possibly to be rechristened as amount -- watch this space) to such an extent that it might make sense to consider both proposals in a unified way. That may or may not mean that the proposals get literally merged together (although that could be a path forward). Ultimately, the committee wasn't in favor of merging the proposals, though there were concerns that, if they were kept separate, one proposal might advance without the other advancing. As usual with all discussions of decimal, the discussion overflowed into the next day, with Shane Carr of Google presenting his own sketch of how the unity of decimal and measure might happen.
Champions (Decimal): Jesse Alama , Jirka Maršík, Andrew Paprocki
Since at least 2015, V8 has exposed a non-standard API called Error.captureStackTrace() to expose an Error-like stack property on any arbitrary object. It also allows passing a function or constructor as its second argument, to skip any stack frames after the last call to that function, which can be used to hide implementation details that won't be useful to the user.
Although this API was V8-internal for so long, in 2023 JSC shipped an implementation of this API, and now SpiderMonkey is working on one. And since the V8 and JSC implementations have some differences, this is now being brought up as a TC39 proposal to settle on some exact behavior, which is now stage 1.
This proposal is only about Error.captureStackTrace(), and it does not attempt to specify V8's Error.prepareStackTrace() API, which allows customizing the stack trace string representation. This API is still V8-only, and there don't seem to be any plans to implement it elsewhere.
Champion: Matthew Gaudet
The "fixed" and "stable" object integrity traits #
The Stabilize proposal is exploring adding a new integrity trait for objects, similar to Object.preventExtension, Object.seal and Object.freeze.
A fixed object is an object whose properties can be safely introspected without triggering side effects, except for when triggering a getter through property access. In addition to that, it's also free from what we call the "override mistake": a non-writeable property doesn't prevent the same property from being set on objects that inherit from it.
const inheritFixed ={__proto__: fixedObject }; inheritFixed.x =3;// sets `inheritFixed.x` to `3`, while leaving `fixedObject.x` as `1`
An object that is both fixed and frozen is called stable.
The proposal was originally also exploring one more integrity trait, to prevent code from defining new private fields on an existing object through the return override trick. This has been removed from this proposal, and instead we are exploring changing the behavior of Object.preventExtensions to also cover this case.
Champions: Mark S. Miller, Chip Morningstar, Richard Gibson, Mathieu Hofman
Once upon a time, async functions did not exist, and neither did promises. For a long time, the only way to do asynchronous work in JS was with callbacks, resulting in "callback hell". Promises first appeared in userland libraries, which eventually converged into one single interoperable API shape called Promises/A+.
When JS added the Promise built-in in ES6, it followed Promises/A+, which included a way to interoperate with other promise libraries. You might know that resolving a promise p1 with a value which is a different promise p2 will not immediately fulfill p1, but it will wait until p2 is resolved and have the same fulfilled value or rejection reason as p2. For compatibility with promise libraries, this doesn't only work for built-in promises, but for any object that has a .then method (called "thenables").
In the time since Promise was added as a built-in, however, it has become clear that thenables are a problem, because it's easy for folks working on the JS engines to forget they exist, resulting in JS code execution happening in unexpected places inside the engine. In fact, even objects fully created within the engine can end up being thenables, since you can set Object.prototype.then to a function. This has led to a number of security vulnerabilities in JS engines, including one last year involving async generators that needed fixes in the JS specification.
It is not feasible to completely get rid of thenables because pre-ES6 promise libraries are still being used to some extent. However, this proposal is about looking for ways to change their behavior so that these bugs can be avoided. It just became stage 1, meaning the possible solutions are still in the process of being explored, but some proposed ideas were:
Make it impossible to set Object.prototype.then.
Ignore thenables for some internal operations.
Change the definition of thenable so that having a then method on Object.prototype and other fundamental built-in objects and prototypes doesn't count, while it would count for regular user-created objects.
During the discussion in plenary, it was mentioned that userland JS also runs into issues with thenables when the call to .then leads to reentrancy (that is, if it calls back into the code that called it). If all engine vulnerabilities caused by thenables are related to reentrancy, then both issues could be solved at once. But it does not seem like that is the case, and solving the reentrancy issue might be harder.
Eemeli Aro from Mozilla presented an update on stable formatting. This proposal aims to add a "stable" locale for addressing some of the weaknesses of our current model of localization. Most importantly, people need an entirely separate code path for either unlocalized or machine-readable use cases which hurts in that it adds complexity to the interface, and it distracts users away from the patterns they ought to be using for their interfaces. This is relevant for use-cases such as testing (especially snapshot testing).
Temporal already made some strides in this direction by keeping the API surface consistent while allowing users to specify the ISO8601 calendar or the UTC timezone instead of relying on localizable alternatives. This proposal would add a "null" locale either in the form of the literal null value in JavaScript or using the "zxx" pattern commonly used in the Internationalization world, in order to provide a stable formatting output so users could write their interface once and just use this specific locale to achieve their desired result.
In the meeting, Eemeli presented their proposal for various formats that should be a part of this stable locale and the committee expressed a preference for the "zxx" locale instead of null with some concerns regarding null being too similar to undefined.
The Intl Locale Info API proposal, which is very close to done, was brought back to the committee perhaps for the last time before Stage 4. The notable change was to remove minimal days from the API due to the lack of strong use cases for it. Finally, there were discussions about the final remaining open questions, especially those that would block implementations. These are planned to be fixed shortly before the proposal goes to Stage 4.
On Thursday evening after the meeting adjourned, the committee members traveled 2 blocks down the road to a SeattleJS meetup kindly hosted by DocuSign at their HQ. A number of committee members gave presentations on TC39-related topics. Two of these were by our colleagues Nicolò Ribaudo, who gave an introduction to the deferred imports proposal, and Philip Chimento, who gave a tour of the Temporal API.
After the plenary ended on Thursday, the discussion continued on Friday with a session of the TG5 part of TC39, which is dedicated to research aspects of JavaScript.
Our colleague Jesse Alama presented on Formalizing JS decimal numbers with the Lean proof assistant. There were a number of other presentations - a report on user studies of the MessageFormat 2.0, studies on TC39 proposals, A parser generator template literal tag generating template literal tags and "uncanny valleys" in language design.
I’ve blogged in the past about how WebKit on Linux integrates with Sysprof, and provides a number of marks on various metrics. At the time that was a pretty big leap in WebKit development since it gave use a number of new insights, and enabled various performance optimizations to land.
But over time we started to notice some limitations in Sysprof. We now have tons of data being collected (yay!) but some types of data analysis were pretty difficult yet. In particular, it was difficult to answer questions like “why does render times increased after 3 seconds?” or “what is the CPU doing during layout?”
In order to answer these questions, I’ve introduced a new feature in Sysprof: filtering by marks.
Select a mark to filter by in the Marks view
Samples will be filtered by that mark
Hopefully people can use this new feature to provide developers with more insightful profiling data! For example if you spot a slowdown in GNOME Shell, you open Sysprof, profile your whole system, and filter by the relevant Mutter marks to demonstrate what’s happening there.
Here’s a fancier video (with music) demonstrating the new feature:
The browser find-in-page feature is intended to allow users to identify where a search term appears in the page. Browsers highlight the locations of the string
using highlights, typically one color for the active match and another color for
the other matches. Both Chrome and Firefox have this behavior, and problems arise
when the default browser color offers poor contrast in the page, or can be easily
confused with other highlighted content.
Safari works around this problem by applying an overlay and painting search
highlights on top. But what can be done in Chrome and Firefox?
The newly available ::search-text pseudo highlight provides styling for the
find-in-page highlight using CSS. Within a ::search-text rule you can use
properties for colors (text and background), text decorations such as underlines,
and shadows. A companion ::search-text:current selector matches the active
find-in-page result and can be styled separately.
As an example, let’s color find-in-page
results green and add a red underline for the active match:
<style> :root::search-text{ color: green; } :root::search-text:current{ color: green; text-decoration: red solid underline; } </style> <p>Find find in this example of find-in-page result styling.</p>
In general, the find-in-page markers should be consistent across the entire page,
so we recommend that you define the ::search-text properties on the root. All
other elements will inherit the pseudo class through the
highlight inheritence
mechanism.
Note that if you do not specify ::serach-text:current,
the active match will use the same styling as inactive matches. In practice, it is best
to always provide styles for ::search-text:current when defining ::search-text, and
vice versa, with sufficient difference in visual appearance to make it clear to users
which is the active match.
This feature is available in Chrome 136.0.7090.0 and later, when “Experimental Web Platform features”
is enabled with chrome://flags. It will likely be available to all users in Chrome 138.
Modifying the appearance of user agent features, such as find-in-page highlighting,
has significant potential to hurt users through poor contrast, small details, or other
accessibility problems. Always maintain good contrast with all the backgrounds present
on the page. Ensure that ::search-text styling is unambiguous. Include find-in-page
actions in your accessibility testing.
Find-in-page highlight styling is beneficial when the native markers pose accessibility
problems, such as poor contrast. It’s one of the motivations for providing this feature.
User find-in-page actions express personal information, so steps have been
taken to ensure that sites cannot observe the presence or absence of find-in-page
results. Computed style queries in Javascript will report the presence of
::search-text styles regardless of whether or not they are currently rendered
for an element.
As part of my performance analysis work for LGE webOS, I often had to capture Chrome Traces from an embedded device. So, to make it convenient, I wrote a simple command line helper to obtain the traces remotely, named trace-chrome.
In this blog post will explain why it is useful, and how to use it.
Chromium provides an infrastructure for capturing static tracing data, based on Perfetto. In this blog post I am not going through its architecture or implementation, but focus on how we instruct a trace capture to start and stop, and how to then fetch the results.
Chrome/Chromium provides user interfaces for capturing and analyzing traces locally. This can be done opening a tab and pointing it to the chrome://tracing URL.
The tracing capture UI is quite powerful, and completely implemented in web. This has a downside, though: running the capture UI introduces a significant overhead in several resources (CPU, memory, GPU, …).
This overhead may be even more significant when tracing Chromium or any other Chromium based web runtime in an embedded device, where we have CPU, storage and memory constraints.
Chromium does a great work at minimizing the overhead, by postponing the trace processing as much as possible, and providing a minimal UI when the capture is ongoing. But it may still be too much.
How to avoid this problem?
Capturing UI should not run in the system we are tracing. We can run the UI in a different computer to capture the trace.
Same about storage, we want it to happen in a different computer.
The solution for both is tracing remotely. Both the user interface for controlling the recording, and the recording storage happen in a different computer.
Target device: it is the one that runs the Chromium web runtime instance we are going to trace.
Host device: the device that will run the tracing UI, to configure, start and stop the recording, and to explore the tracing results.
OK, now we know we want to trace remotely the target device Chromium instance. How can we do that? First, we need to connect our tracing tools running in the host to the Chromium instance in the target device.
This is done using the remote debugging port: a multi-purpose HTTP port provided by Chromium. This port is used not only for tracing, it offers access to Chrome Developer Tools.
The Chromium remote debugging port is disabled by default, but it can be enabled using the command line switch --remote-debugging-port=PORT in the target Chromium instance. This will open an HTTP port in the localhost interface, that can be used to connect.
Why localhost? Because this interface does not provide any authentication or encryption. So it is unsafe. It is user responsibility to provide some security (i.e. by using an setting an SSH tunnel between the host and the target device to connect to the remote debugging port).
Chromium browser provides a solution for tracing remotely. Just opening the URL chrome://inspect in the host device. It provides this user interface:
First, the checkbox for Discover network targets needs to be set.
Then press the Configure… button to set the list of IP addressed and ports where we expect target remote debugging ports to be.
Do not forget to add to the list the end point that is accessible from the host device. I.e. in the case of an SSH tunnel from the host device to the target device port, it needs to be the host side of the tunnel.
For the case we set up the host side tunnel at the port 10101, we will see this:
Then, just pressing the trace link will show the Chromium tracing UI, but connected to the target device Chromium instance.
Over the last 8 years, I have been involved quite often in exploring the performance of Chromium in embedded devices. Specifically for the LGE webOS web stack. In this problem space, Chromium tracing capabilities are handy, providing a developers oriented view of different metrics, including the time spent running known operations in specific threads.
At that time I did not know about chrome://inspect so I really did not have an easy way to collect Chromium traces from a different machine. This is important as one performance analysis principle is that collecting the information should be as lightweight as possible. Running the tracing UI in the same Chromium instance that is analyzed is against that principle.
The solution? I wrote a very simple NodeJS script, that allows to capture a Chromium trace from the command line.
This is convenient for several reasons:
No need to launch the full tracing UI.
As we completely detach that UI from the capturing step, without an additional step to record the trace to a file, we are not affected on the unstability of the tracing UI handling the captured trace (not a problem usually, but it happens).
Easier to repeat tests for specific tracing categories, instead of manually enabling them in the tracing UI.
The script just provides an easy to use command line interface to the already existing chrome-remote-interface NodeJS module.
To connect to a running Chromium instance remote debugging port, the --host and --port parameters need to be used. In the examples I am going to use the port 9999 and the host localhost.
Warning
Note that, in this case, the parameter --host refers to the network address of the remote debugging port access point. It is not referring to the host machine where we run the script.
Now, the most important step: recording a Chromium trace. To do this, we will provide a list of categories (parameter --categories), and a file path to record the trace (parameter --output):
This will start recording. To stop recording, just press <Ctrl>+C, and the trace will be transferred and stored to the provided file path.
Tip
Which categories to use? Good presets for certain problem scopes can be obtained in Chrome. Just open chrome://tracing, press the Record button, and play with the predefined settings. In the bottom you will see the list of categories to pass for each of them.
Now the tracing file has been obtained, it can be opened from Chrome or Chromium running in host: load in a tab the URL chrome://tracing and press the Load button.
Tip
The traces are completely standalone. So they can be loaded in any other computer without any additional artifact. This is useful, as those traces can be shared among developers or uploaded to a ticket tracker.
But, if you want to do that, do not forget to compress first with gzip to make the trace smaller. chrome://tracing can open the compressed traces directly.
The script also supports periodical recording of the memory-infra system. This captures periodical dumps of the state of memory, with specific instrumentation in several categories.
To use it, add the category disabled-by-default-memory-infra, and pass the following parameters to configure the capture:
--memory_dump_mode <background|detailed|simple>: level of detail. background is designed to have almost no impact in execution, running very fast. light mode shows a few entries, while detailed is unlimited, and provides the most complete information.
--memory_dump_interval: the interval in miliseconds between snapshots.
For convenience, it is also possible to use trace-chrome with npx. It will install the script and the dependencies in the NPM cache, and run from them:
trace-chrome is a very simple tool, just providing a convenient command line interface for interacting with remote Chromium instances. It is specially useful for tracing embedded devices.
It has been useful for me for years, in a number of platforms, from Windows to Linux, from desktop to low end devices.
Update on what happened in WebKit in the week from March 17 to March 24.
Cross-Port 🐱
Limited the amount data stored for certain elements of WebKitWebViewSessionState. This results in memory savings, and avoids oddly large objects which resulted in web view state being restored slowly.
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Fixed an integer overflow when using wasm/gc on 32-bits.
Graphics 🖼️
Landed a change that fixes a few scenarios where the damage was not generated on layer property changes.
Releases 📦️
WebKitGTK 2.48.0 and WPE WebKit 2.48.0 have been released. While they may not look as exciting as the 2.46 series, which introduced the use of Skia for painting, they nevertheless includes half a year of improvements. This development cycle focused on reworking internals, which brings modest performance improvements for all kinds of devices, but most importantly cleanups which will enable further improvements going forward.
For those who need longer to integrate newer releases, which we know can be a longer process for embedded device distrihytos, we have also published WPE WebKit 2.46.7 with a few stability and security fixes.
Accompanying these releases there is security advisory WSA-2025-0002 (GTK, WPE), which covers the solved security issues. Crucially, all three contain the fix for an issue known to be exploited in the wild, and therefore we strongly encourage updating.
The inspiration for doing Leaning In! came from the tutorial at BOBKonf 2024 by Joachim Breitner and David Christiansen. The tutorial room was full; in fact, it was overfull and not everyone who wanted to attend could attend. I’d kept my eye on Lean from its earliest days but lost the thread for a long time. The image I had of Lean came from its version 1 and 2 days, when the project was still closely aligned the aims of homotopy type theory. I didn’t know about Lean version 3. So when I opened my eyes and woke up, I was in the current era of Lean (version 4), with a great language, humongous standard library, and pretty sensibile tooling. I was on board right away. As an organizer of Racketfest, I had some experience putting together (small) conferences, so I thought I’d give it a go with Lean.
I announced the conference a few months ago, so there wasn’t all that much time to find speakers and plan. Still, we had 33 people in the room. When I first started planning the workshop, I thought there’d only be 10-12 people. This was my first time organizing a Lean workshop of any sort, so my initial expectations were very modest. I booked a fairly small room at Spielfeld for that. After some encouragement from Joachim, who politely suggested that 10-12 might be a bit too small, I requested a somewhat larger room, for up to 20 people. But as registrations kept coming in, I needed to renegotiate with Spielfeld. Ultimately, they put us in their largest room (a more appropriately sized room exists but had already been booked). The room we were in was somewhat too big, but I’m glad we had the space.
Lean is a delightful mix of program verification and mathematics formalization. That was reflected in the program. We had three talks,
that, I’d say, were definitely more in the computer science camp. With Lean, it’s not so clear at times. Lukas’s talk was motivated by some applications coming from computer science but the topic makes sense on its own and could have been taken up by a mathematician. The opening talk, Recursive definitions, by Joachim Breitner, was about the internals of Lean itself, so I think it doesn’t count as a talk on formalizing mathematics. But it sort of was, in the sense that it was about the logic in the Lean kernel. It was computer science-y, but it wasn’t really about using Lean, but more about better understanding how Lean works under the hood.
It is clear that mathematics formalization in Lean is very much ready for research level mathematics. The mathematics library is very well developed, and Lean is fast enough, with good enough tooling, to enable mathematicians to do serious stuff. We are light years past noodling about the Peano axioms or How do I formalize a group?. I have a guy feeling that we may be approaching a point in the near future wher Lean might become a common way of doing mathematics.
What didn’t go so well
The part of the event that probably didn’t go quite as I had planned was the Proof Clinic in the afternoon. The intention of the proof clinic was to take advantage of the fact that many of us had come to Berlin to meet face-to-face, and there were several experts in the room. Let’s work together! If there’s anything you’re stuck on, let’s talk about it and make some progress, today. Think of it as a sort of micro-unconference (just one hour long) within a workshop.
That sounds good, but I didn’t prepare the attendees well enough. I only started adding topics to the list of potential discussion items in the morning, and I was the only one adding them. Privately, I had a few discussion items in my back pocket, but they were intended just to get the conversation going. My idea was that once we prime the pump, we’ll have all sorts of things to talk about.
That’s not quite what happened. We did, ultimately, discuss a few interesting things but it took a while for us to warm up. Also, doing the proof clinic as a single large group might not have been the best idea. Perhaps we should have split up into groups and tried to work together that way.
I also learned that several attendees don’t use Zulip, so my assumption that Zulip is the one and only way for people to communicate about Lean wasn’t quite right. I could have done better communication with attendees in advance to make sure that we coordinate discussion in Zulip, instead of simply assuming that, of course, everyone is there.
The future
Will there be another edition of Leaning In!
Yes, I think so. It's a lot of work to organize a conference (and there's always more to do, even when you know that there's a lot!). But the community benefits are clear. Stay tuned!
(This is my first NPM package. I made it in TypeScript; it’s my first go at the language.)
What?
Decimal128 is an IEEE standard for floating-point decimal numbers. These numbers aren’t the binary floating-point numbers that you know and love (?), but decimal numbers. You know, the kind we learn about before we’re even ten years old. In the binary world, things like 0.1 + 0.2 aren’t exactly* equal to 0.3, and calculations like 0.7 * 1.05 work out to exactly0.735. These kinds of numbers are what we use when doing all sorts of everyday calculations, especially those having to do with money.
Decimal128 encodes decimal numbers into 128 bits. It is a fixed-width encoding, unlike arbitrary-precision numbers, which, of course, require an arbitrary amount of space. The encoding can represent of numbers with up to 34 significant digits and an exponent of –6143 to 6144. That is a truly vast amount of space if one keeps the intended use cases involving human-readable and -writable numbers (read: money) in mind.
Why?
I’m working on extending the JavaScript language with decimal numbers (proposal-decimal). One of the design decisions that has to be made there is whether to implement arbitrary-precision decimal numbers or to implement some kind of approximation thereof, with Decimal128 being the main contender. As far as I could tell, there was no implementation of Decimal128 in JavaScript, so I made one.
The intention isn’t to support the full Decimal128 standard, nor should one expect to achieve the performance that, say, a C/C++ library would give you in userland JavaScript. (To say nothing of having machine-native decimal instructions, which is truly exotic.) The intention is to give JavaScript developers something that genuinely strives to approximate Decimal128 for JS programs.
In particular, the hope is that this library offers the JS community a chance to get a feel for what Decimal128 might be like.
How to use
Just do
$ npm install decimal128
and start using the provided Decimal128 class.
Issues?
If you find any bugs or would like to request a feature, just open an issue and I’ll get on it.
The decimals around us: Cataloging support for decimal numbers
Decimals numbers are a data type that aims to exactly represent decimal numbers. Some programmers may not know, or fully realize, that, in most programming languages, the numbers that you enter look like decimal numbers but internally are represented as binary—that is, base-2—floating-point numbers. Things that are totally simple for us, such as 0.1, simply cannot be represented exactly in binary. The decimal data type—whatever its stripe or flavor—aims to remedy this by giving us a way of representing and working with decimal numbers, not binary approximations thereof. (Wikipedia has more.)
To help with my work on adding decimals to JavaScript, I've gone through a list of popular programming languages, taken from the 2022 StackOverflow developer survey. What follows is a brief summary of where these languages stand regarding decimals. The intention is to keep things simple. The purpose is:
If a language does have decimals, say so;
If a language does not have decimals, but at least one third-party library exists, mention it and link to it. If a discussion is underway to add decimals to the language, link to that discussion.
There is no intention to filter out an language in particular; I'm just working with a slice of languages found in in the StackOverflow list linked to earlier. If a language does not have decimals, there may well be multiple third-part decimal libraries. I'm not aware of all libraries, so if I have linked to a minor library and neglect to link to a more high-profile one, please let me know. More importantly, if I have misrepresented the basic fact of whether decimals exists at all in a language, send mail.
C
C does not have decimals. But they're working on it! The C23 standard (as in, 2023) standard proposes to add new fixed bit-width data types (32, 64, and 128) for these numbers.
C#
C# has decimals in its underlying .NET subsystem. (For the same reason, decimals also exist in Visual Basic.)
C++
C++ does not have decimals. But—like C—they're working on it!
Dart
Dart does not have decimals. But a third-party library exists.
Go
Go does not have decimals, but a third-party library exists.
JavaScript does not have decimals. We're working on it!
Kotlin
Kotlin does not have decimals. But, in a way, it does: since Kotlin is running on the JVM, one can get decimals by using Java's built-in support.
Ruby has decimals. Despite that, there is some third-party work to improve the built-in support.
Rust
Rust does not have decimals, but a crate exists.
SQL
SQL has decimals (it is the DECIMAL data type). (Here is the documentation for, e.g., PostgreSQL, and here is the documentation for MySQL.)
TypeScript does not have decimals. However, if decimals get added to JavaScript (see above), TypeScript will probably inherit decimals, eventually.
Here’s how to unbreak floating-point math in JavaScript
Because computers are limited, they work in a finite range of numbers, namely, those that can be represented straightforwardly as fixed-length (usually 32 or 64) sequences of bits. If you’ve only got 32 or 64 bits, it’s clear that there are only so many numbers you can represent, whether we’re talking about integers or decimals. For integers, it’s clear that there’s a way to exactly represent mathematical integers (within the finite domain permitted by 32 or 64 bits). For decimals, we have to deal with the limits imposed by having only a fixed number of bits: most decimal numbers cannot be exactly represented. This leads to headaches in all sorts of contexts where decimals arise, such as finance, science, engineering, and machine learning.
It has to do with our use of base 10 and the computer’s use of base 2. Math strikes again! Exactness of decimal numbers isn’t an abstruse, edge case-y problem that some mathematicians thought up to poke fun at programmers engineers who aren’t blessed to work in an infinite domain. Consider a simple example. Fire up your favorite JavaScript engine and evaluate this:
1 + 2 === 3
You should get true. Duh. But take that example and work it with decimals:
0.1 + 0.2 === 0.3
You’ll get false.
How can that be? Is floating-point math broken in JavaScript? Short answer: yes, it is. But if it’s any consolation, it’s not just JavaScript that’s broken in this regard. You’ll get the same result in all sorts of other languages. This isn’t wat. This is the unavoidable burden we programmers bear when dealing with decimal numbers on machines with limited precision.
Maybe you’re thinking OK, but if that’s right, how in the world do decimal numbers get handled at all? Think of all the financial applications out there that must be doing the wrong thing countless times a day. You’re quite right! One way of getting around oddities like the one above is by always rounding. So instead of working with, say, this is by handling decimal numbers as strings (sequences of digits). You would then define operations such as addition, multiplication, and equality by doing elementary school math, digit by digit (or, rather, character by character).
So what to do?
Numbers in JavaScript are supposed to be IEEE 754 floating-point numbers. A consequence of this is, effectively, that 0.1 + 0.2 will never be 0.3 (in the sense of the === operator in JavaScript). So what can be done?
There’s an npm library out there, decimal.js, that provides support for arbitrary precision decimals. There are probably other libraries out there that have similar or equivalent functionality.
As you might imagine, the issue under discussion is old. There are workarounds using a library.
But what about extending the language of JavaScript so that the equation does get validated? Can we make JavaScript work with decimals correctly, without using a library?
Yes, we can.
Aside: Huge integers
It’s worth thinking about a similar issue that also arises from the finiteness of our machines: arbitrarily large integers in JavaScript. Out of the box, JavaScript didn’t support extremely large integers. You’ve got 32-bit or (more likely) 64-bit signed integers. But even though that’s a big range, it’s still, of course, limited. BigInt, a proposal to extend JS with precisely this kind of thing, reached Stage 4 in 2019, so it should be available in pretty much every JavaScript engine you can find. Go ahead and fire up Node or open your browser’s inspector and plug in the number of nanoseconds since the Big Bang:
(Not a scientician. May not be true. Not intended to be a factual claim.)
Adding big decimals to the language
OK, enough about big integers. What about adding support for arbitrary precision decimals in JavaScript? Or, at least, high-precision decimals? As we see above, we don’t even need to wrack our brains trying to think of complicated scenarios where a ton of digits after the decimal point are needed. Just look at 0.1 + 0.2 = 0.3. That’s pretty low-precision, and it still doesn’t work. Is there anything analogous to BigInt for non-integer decimal numbers? No, not as a library; we already discussed that. Can we add it to the language, so that, out of the box—with no third-party library—we can work with decimals?
The answer is yes. Work is proceeding on this matter, but things remain to unsettled. The relevant proposal is BigDecimal. I’ll be working on this for a while. I want to get big decimals into JavaScript. There are all sorts of issues to resolve, but they’re definitely resolvable. We have experience with arbitrary precision arithmetic in other languages. It can be done.
So yes, floating-point math is broken in JavaScript, but help is on the way. You’ll see more from me here as I tackle this interesting problem; stay tuned!
Binary floats can let us down! When close enough isn't enough
If you've played Monopoly, you'll know abuot the Bank Error in Your Favor card in the Community Chest. Remember this?
A bank error in your favor? Sweet! But what if the bank makes an error in its favor? Surely that's just as possible, right?
I'm here to tell you that if you're doing everyday financial calculations—nothing fancy, but involving money that you care about—then you might need to know that using binary floating point numbers, then something might be going wrong. Let's see how binary floating-point numbers might yield bank errors in your favor—or the bank's.
In a wonderful paper on decimal floating-point numbers, Mike Colishaw gives an example.
Here's how you can reproduce that in JavaScript:
(1.05 * 0.7).toPrecision(2);
# 0.73
Some programmers might not be aware of this, but many are. By pointing this out I'm not trying to be a smartypants who knows something you don't. For me, this example illustrates just how common this sort of error might be.
For programmers who are aware of the issue, one typical approache to dealing with it is this: Never work with sub-units of a currency. (Some currencies don't have this issue. If that's you and your problem domain, you can kick back and be glad that you don't need to engage in the following sorts of headaches.) For instance, when working with US dollars of euros, this approach mandates that one never works with euros and cents, but only with cents. In this setting, dollars exist only as an abstraction on top of cents. As far as possible, calculations never use floats. But if a floating-point number threatens to come up, some form of rounding is used.
Another aproach for a programmer is to delegate financial calculations to an external system, such as a relational database, that natively supports proper decimal calculations. One difficulty is that even if one delegates these calculations to an external system, if one lets a floating-point value flow int your program, even a value that can be trusted, it may become tainted just by being imported into a language that doesn't properly support decimals. If, for instance, the result of a calculation done in, say, Postgres, is exactly 0.1, and that flows into your JavaScript program as a number, it's possible that you'll be dealing with a contaminated value. For instance:
This example, admittedly, requires quite a lot of decimals (19!) before the ugly reality of the situation rears its head. The reality is that 0.1 does not, and cannot, have an exact representation in binary. The earlier example with the cost of a phone call is there to raise your awareness of the possibility that one doesn't need to go 19 decimal places before one starts to see some weirdness showing up.
There are all sorts of examples of this. It's exceedingly rare for a decimal number to have an exact representation in binary. Of the numbers 0.1, 0.2, …, 0.9, only 0.5 can be exactly represented in binary.
Next time you look at a bank statement, or a bill where some tax is calculated, I invite you to ask how that was calculated. Are they using decimals, or floats? Is it correct?
I'm working on the decimal proposal for TC39 to try to work what it might be like to add proper decimal numbers to JavaScript. There are a few very interesting degrees of freedom in the design space (such as the precise datatype to be used to represent these kinds of number), but I'm optimistic that a reasonable path forward exists, that consensus between JS programmers and JS engine implementors can be found, and eventually implemented. If you're interested in these issues, check out the README in the proposal and get in touch!
 #
#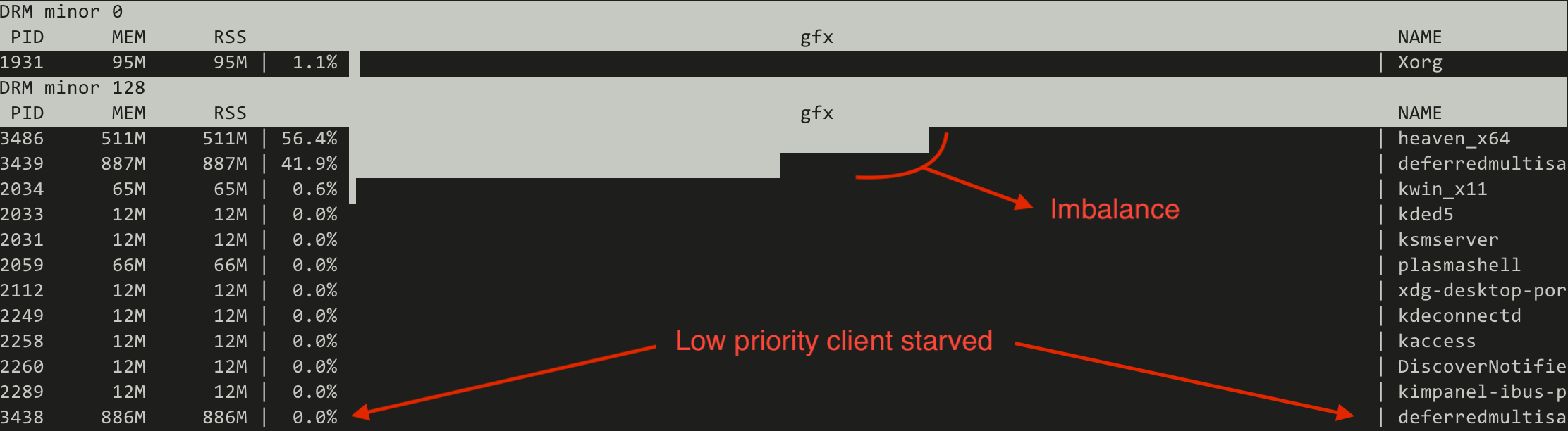

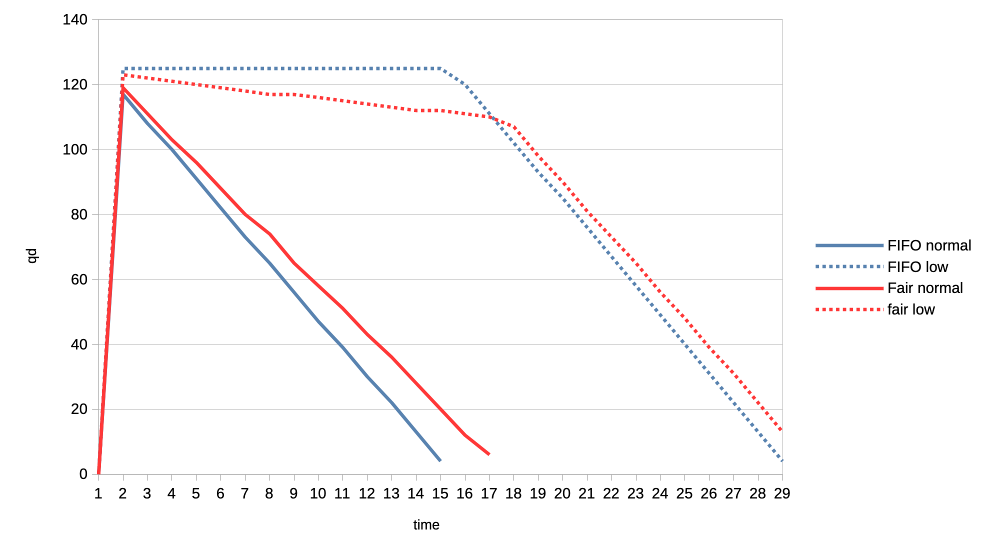
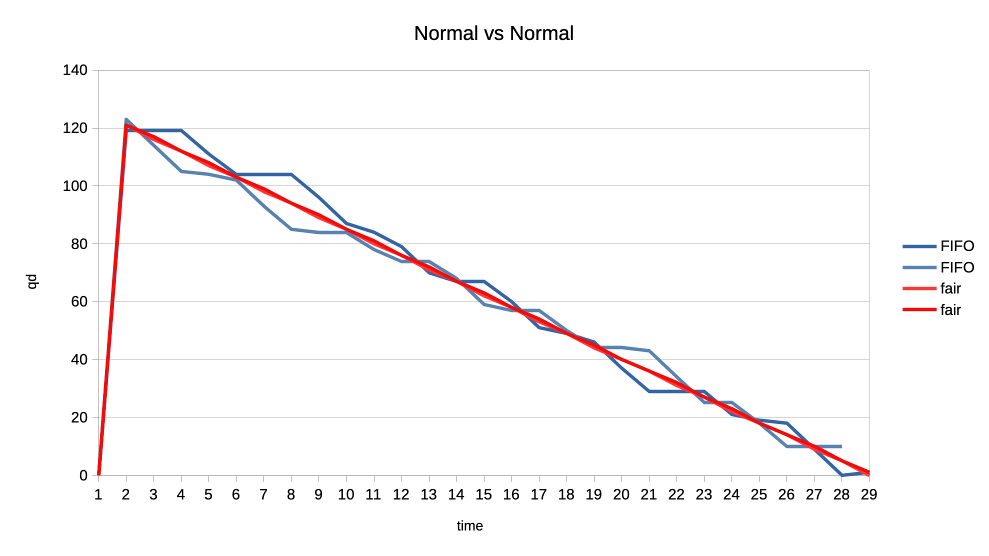
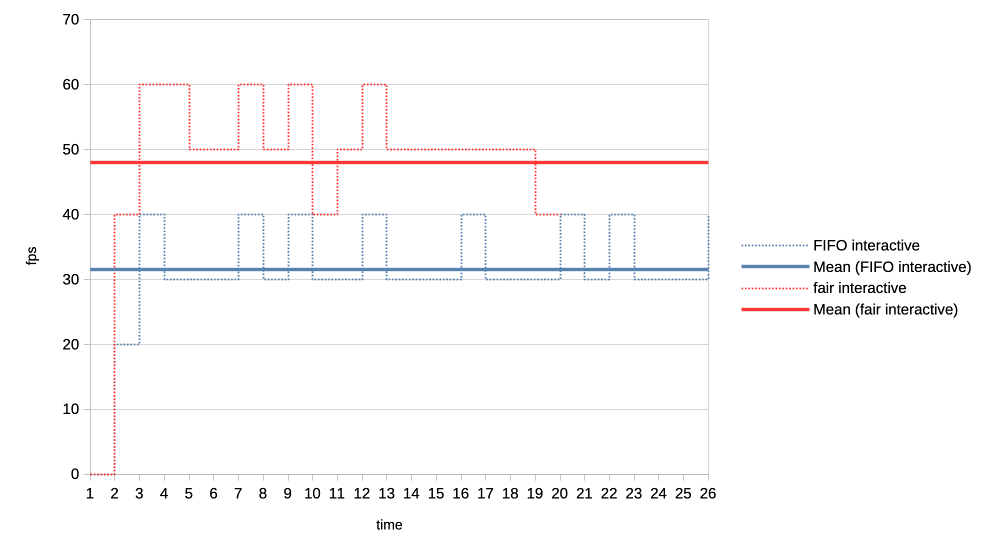
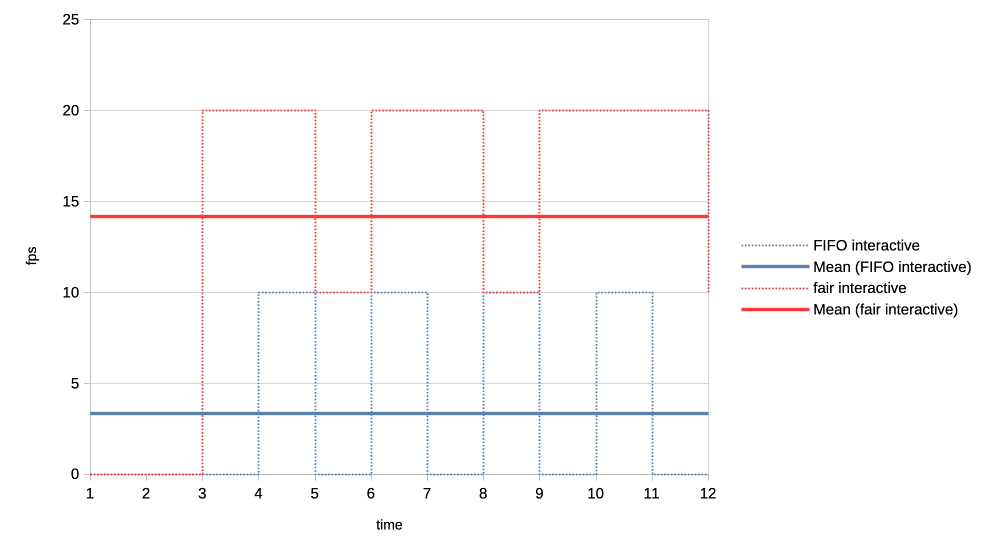

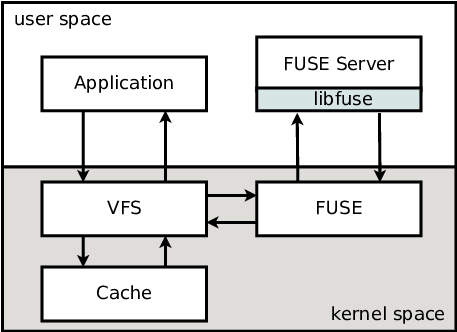
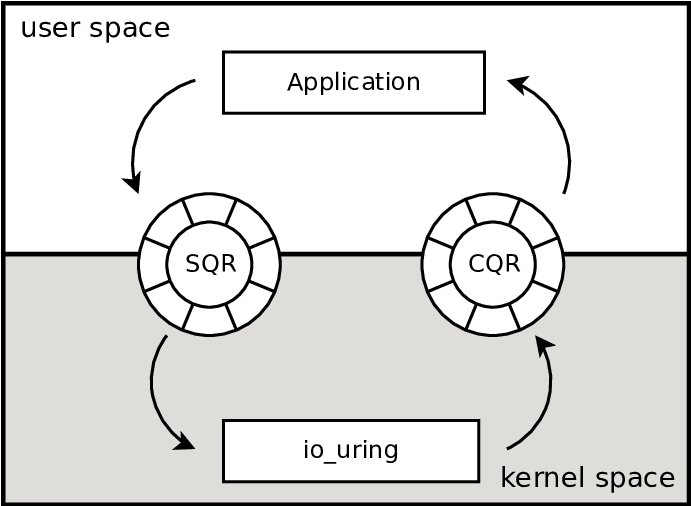
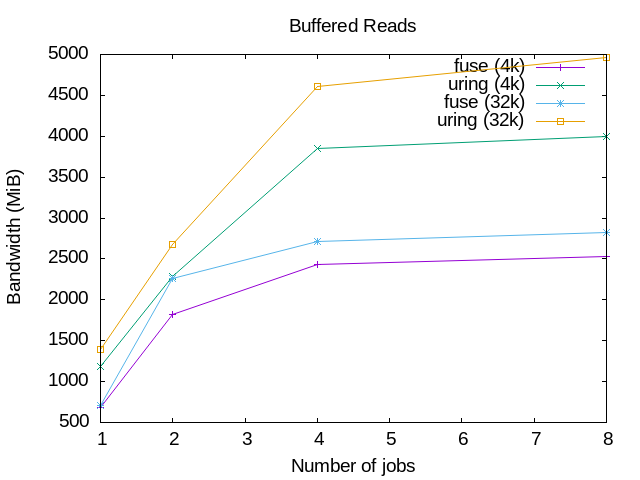
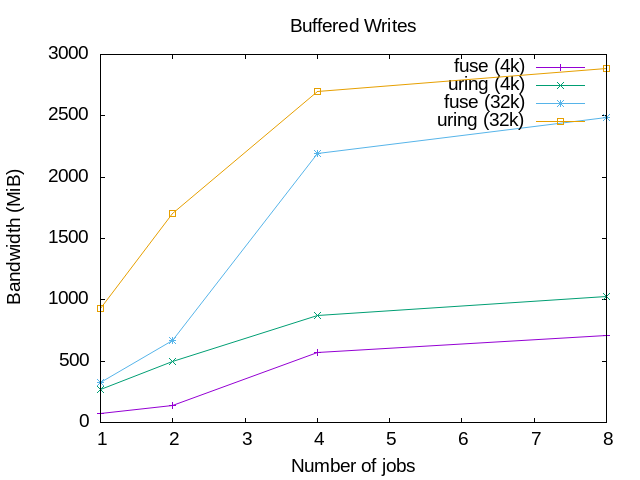
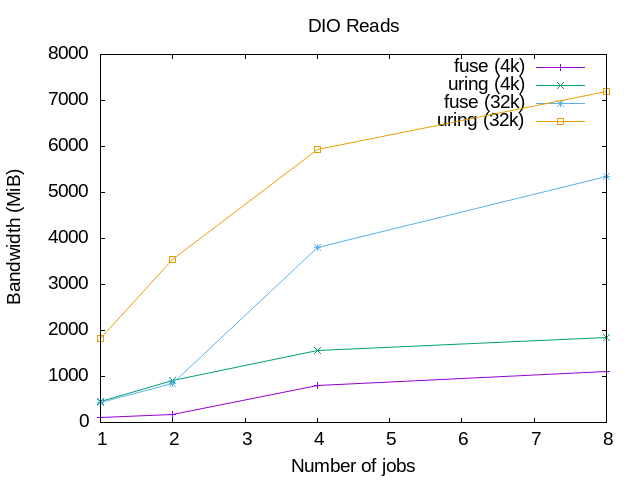
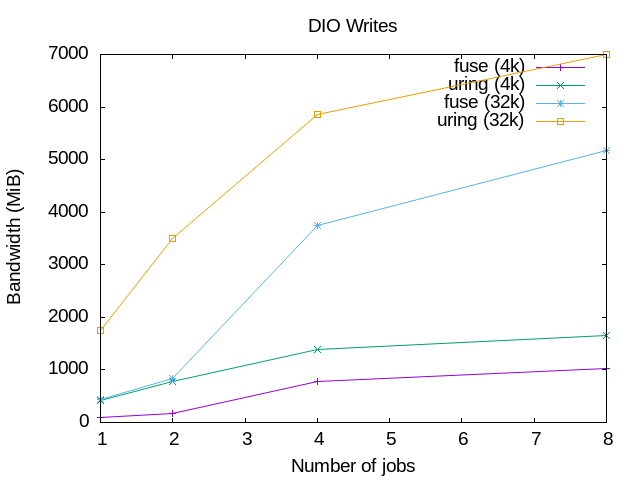














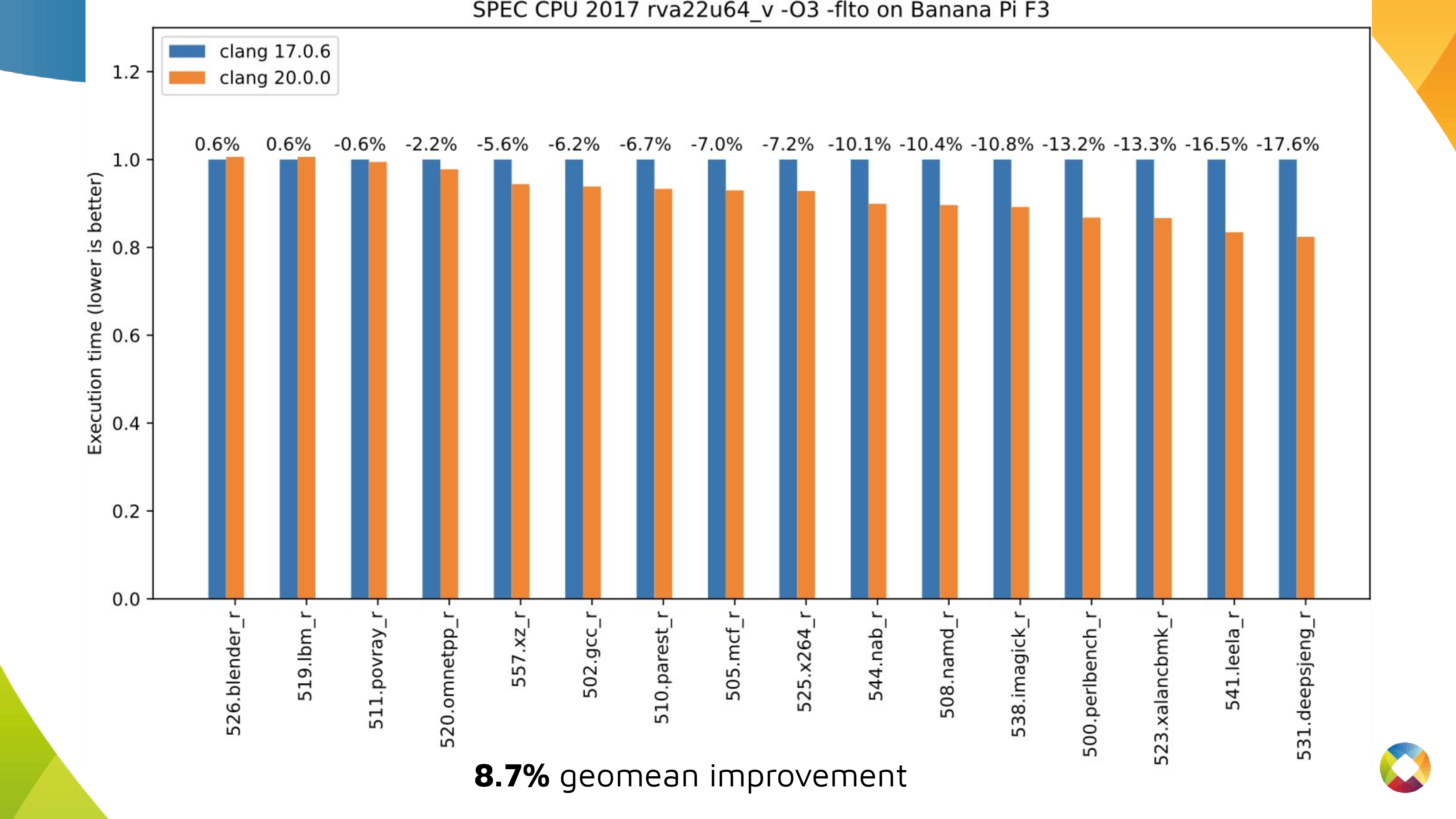





















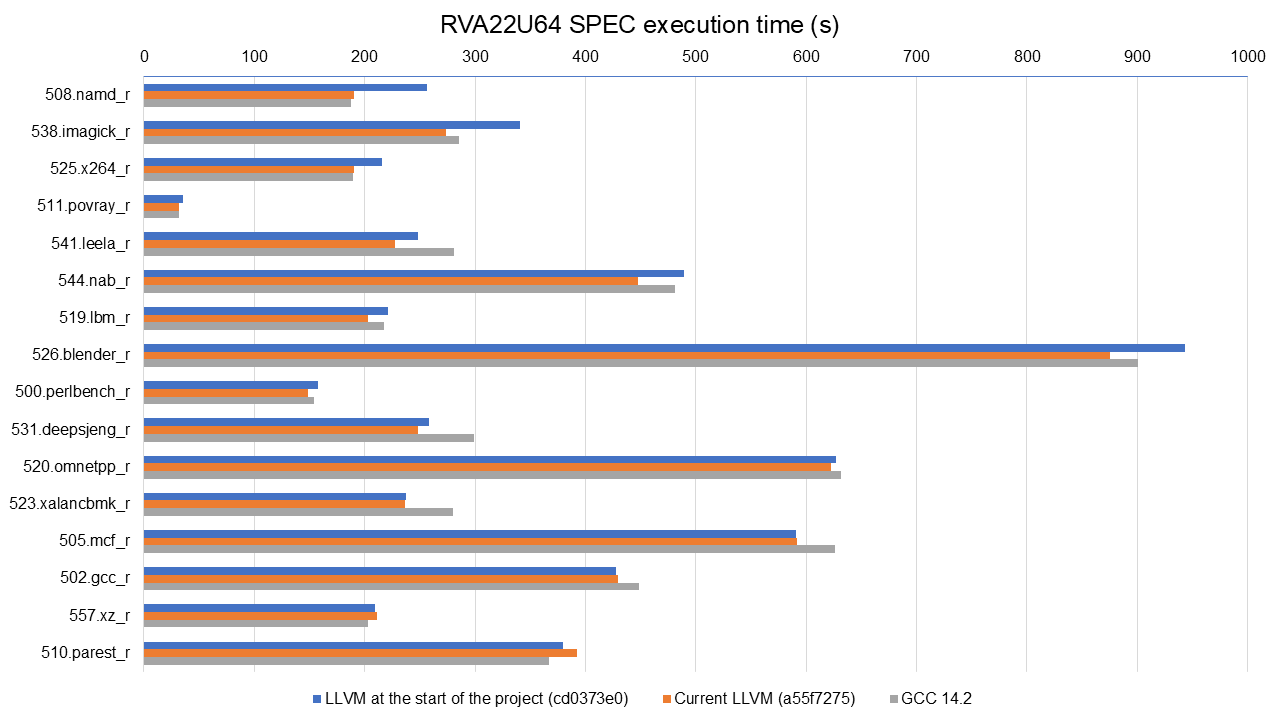
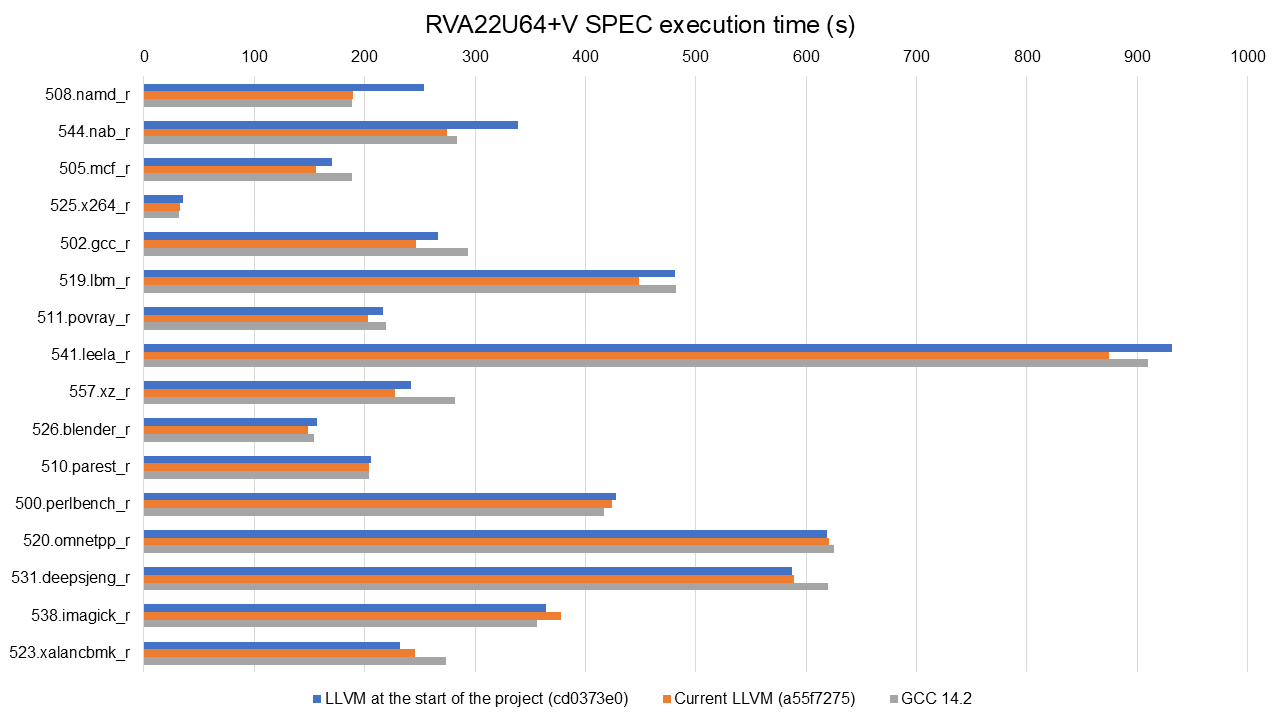
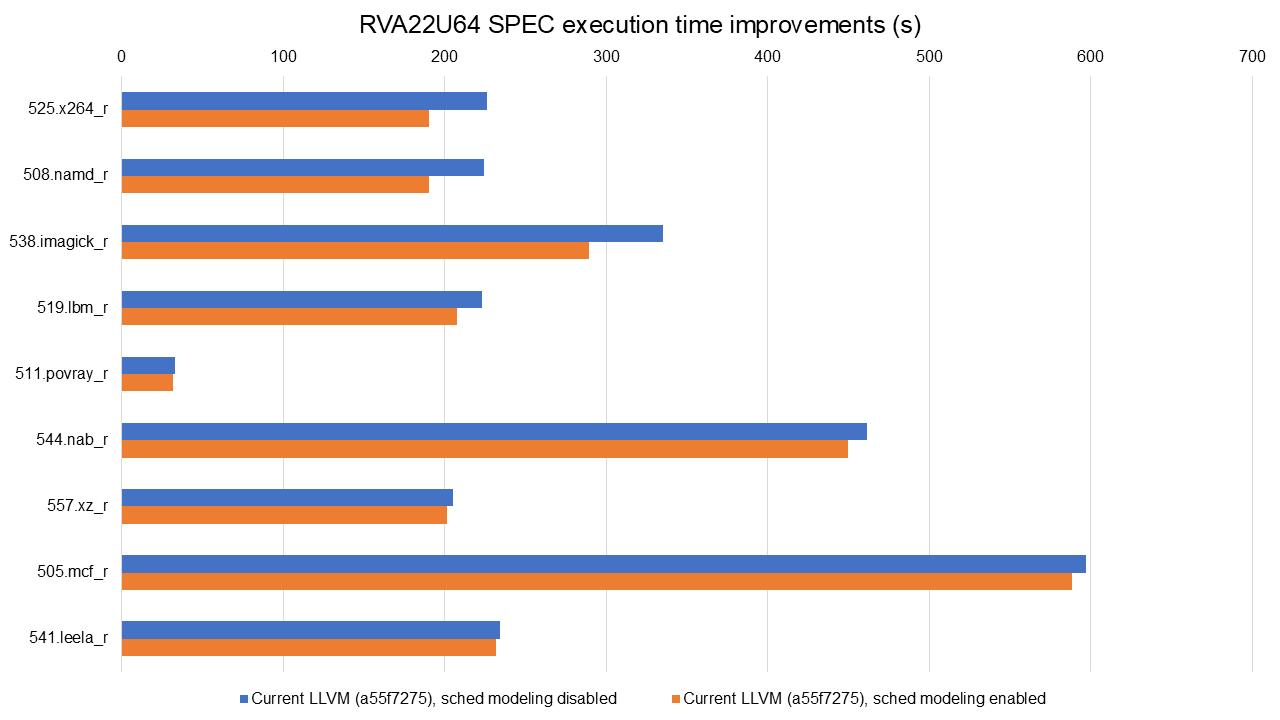
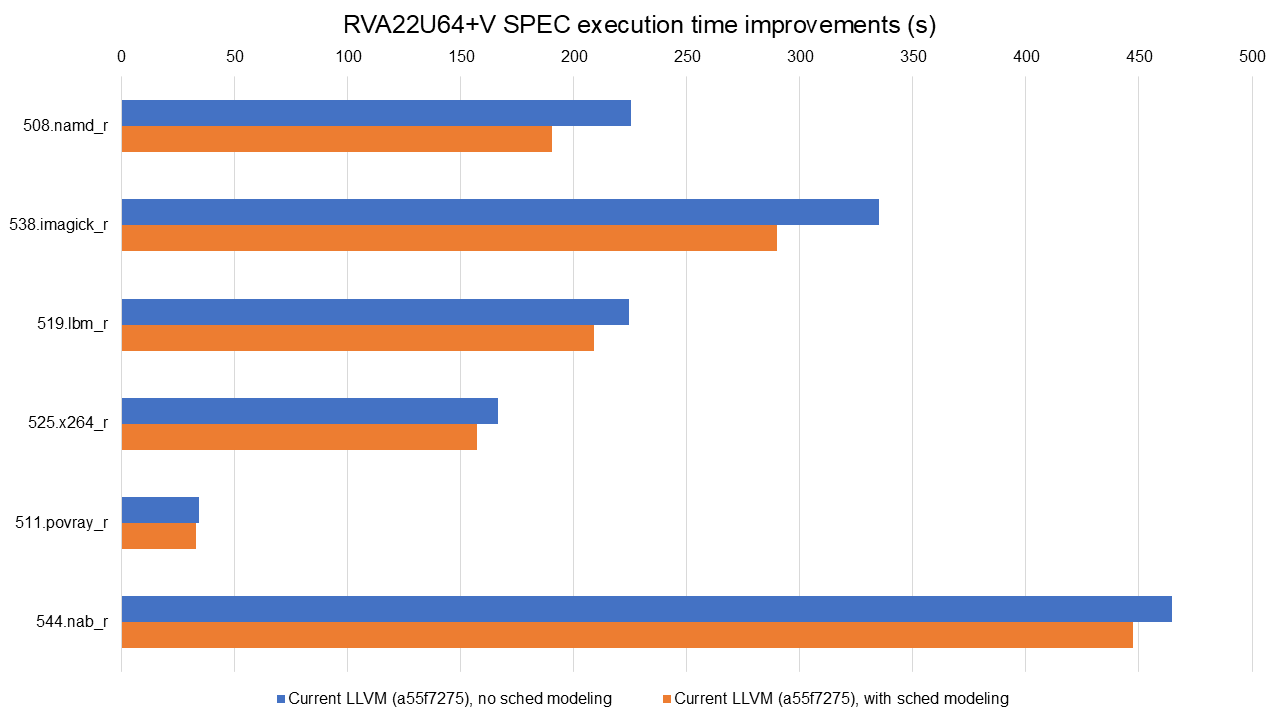
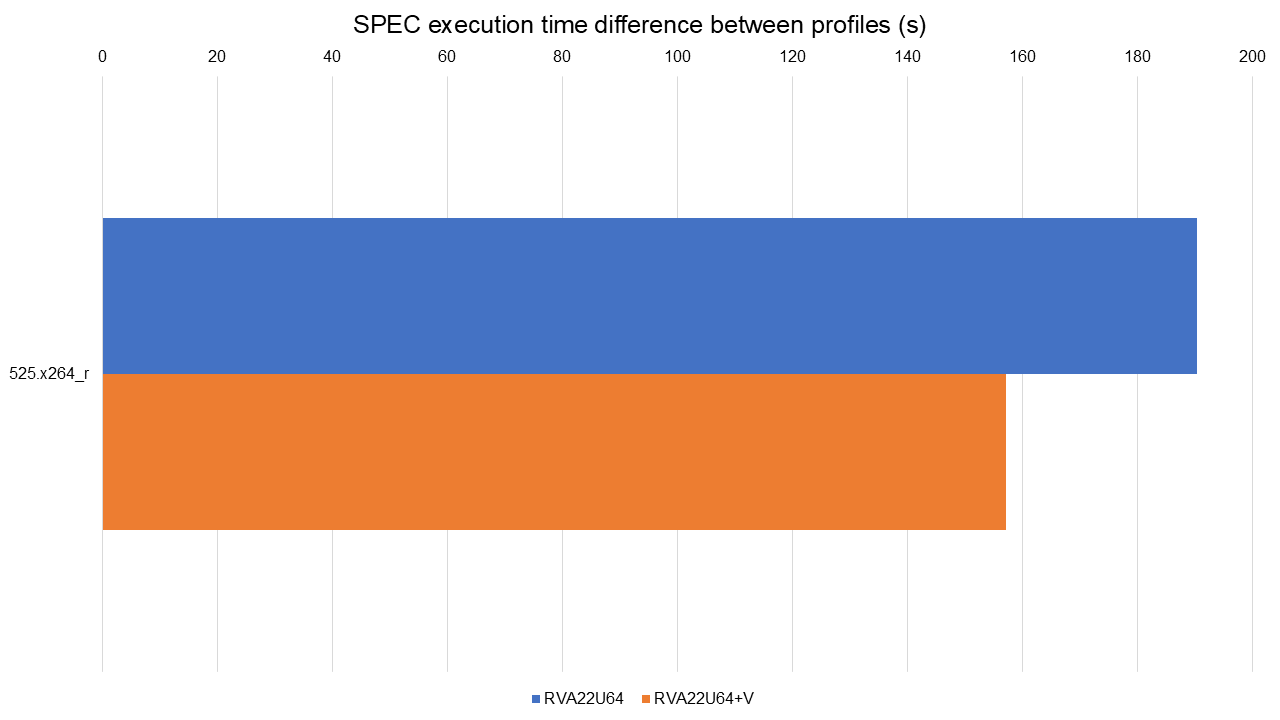
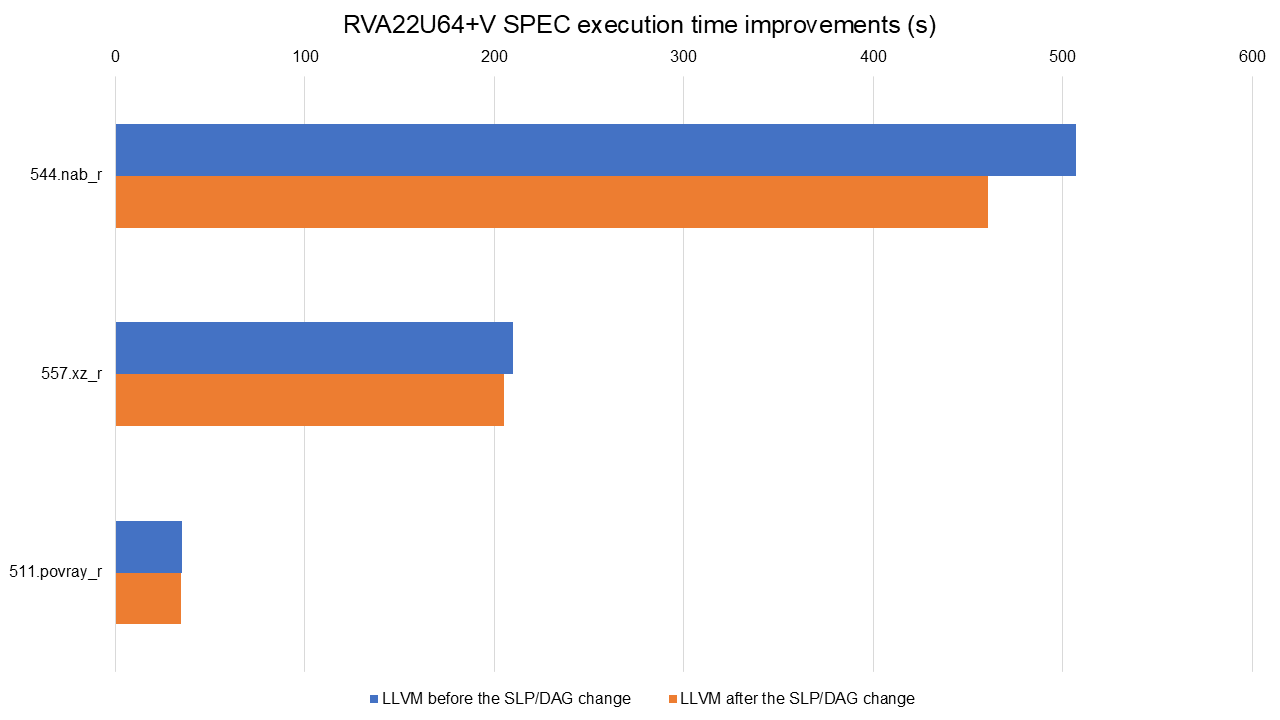
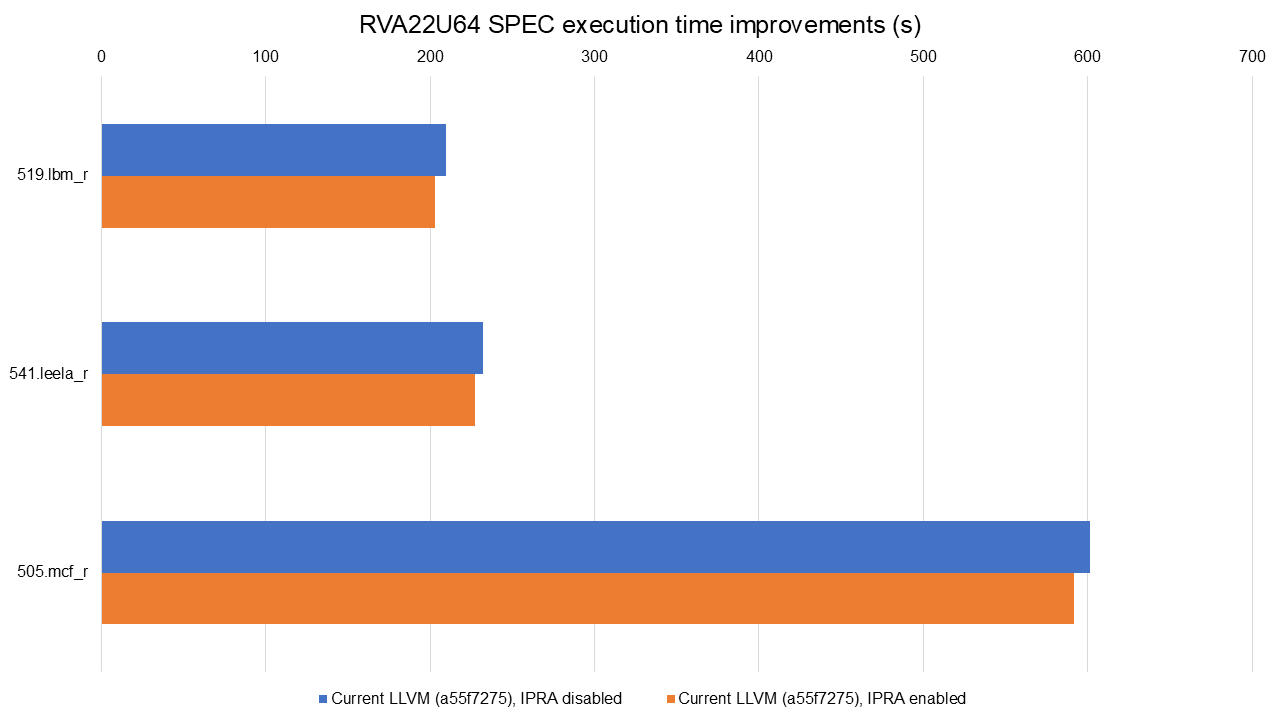
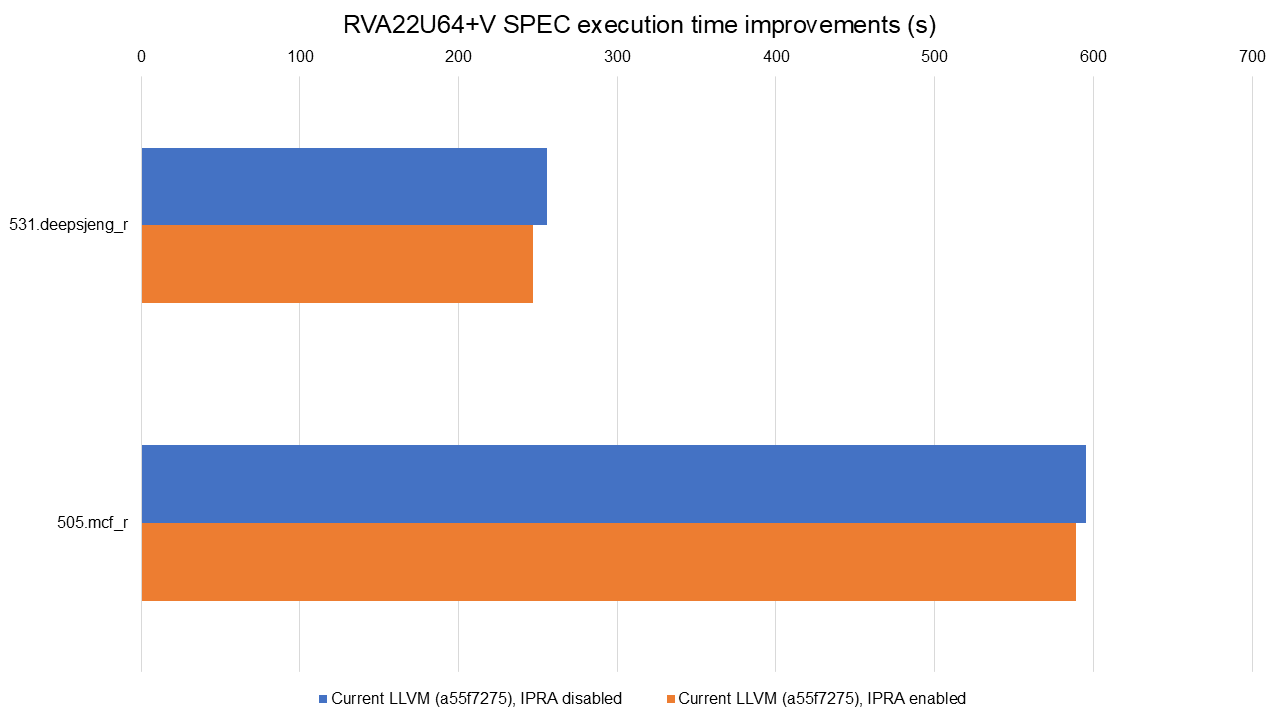




















 There is a userspace developer who wants to report a kernel issue and says:
There is a userspace developer who wants to report a kernel issue and says:












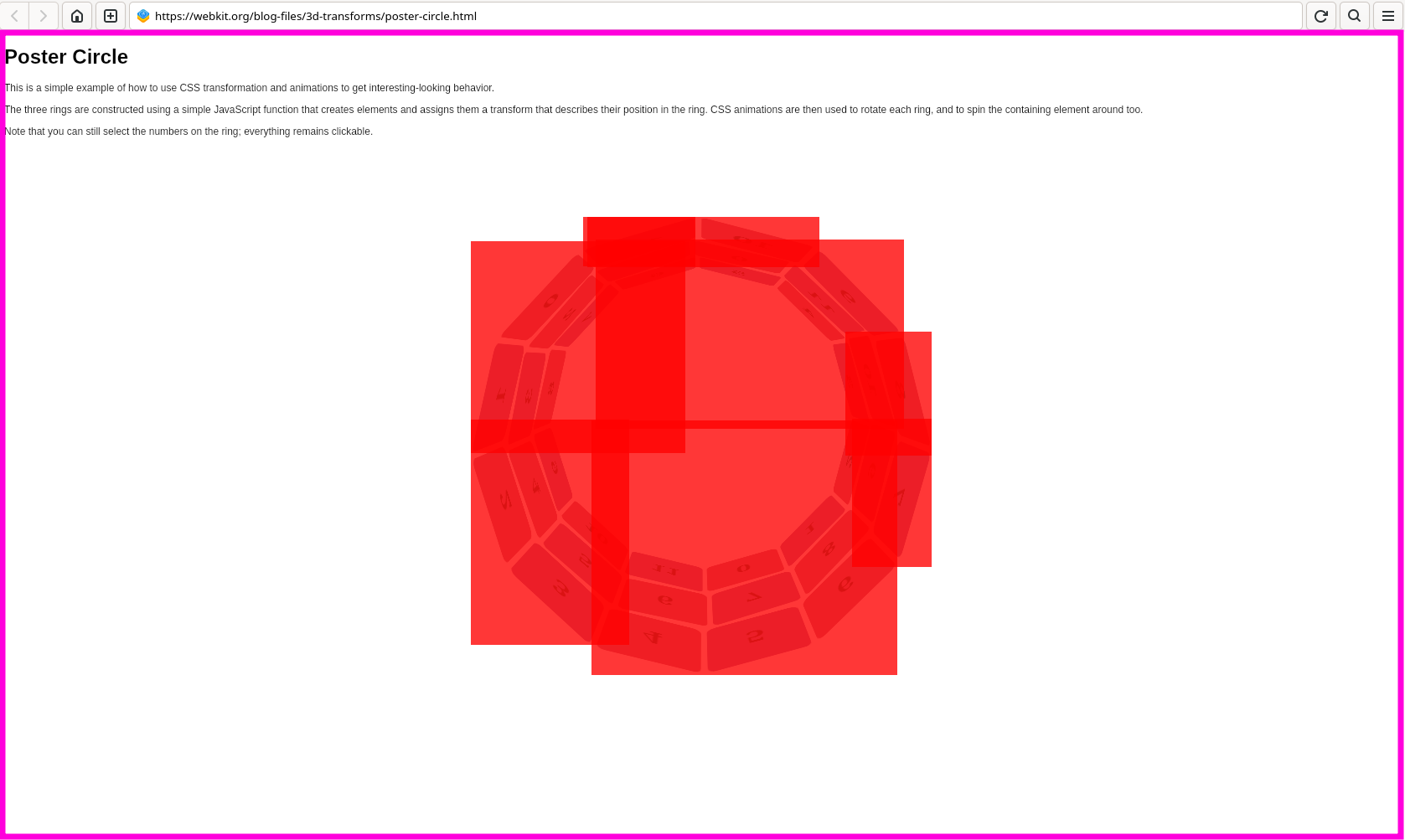 In the image above, one can see the following elements:
In the image above, one can see the following elements: